






6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 146115位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。
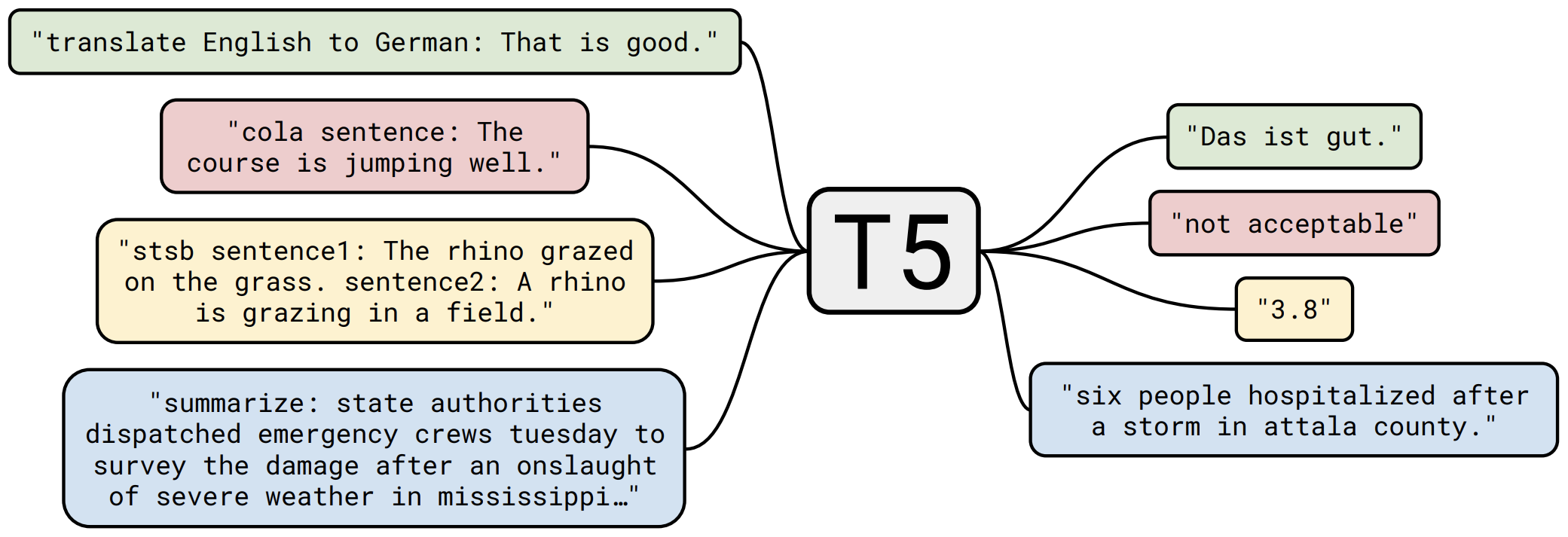
“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。
20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 79204位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 169022位读者 | 引用在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
![P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 82532位读者 | 引用
20
Apr
你的语言模型有没有“无法预测的词”?
By 苏剑林 | 2022-04-20 | 23800位读者 | 引用众所周知,分类模型通常都是先得到编码向量,然后接一个Dense层预测每个类别的概率,而预测时则是输出概率最大的类别。但大家是否想过这样一种可能:训练好的分类模型可能存在“无法预测的类别”,即不管输入是什么,都不可能预测出某个类别$k$,类别$k$永远不可能成为概率最大的那个。
当然,这种情况一般只出现在类别数远远超过编码向量维度的场景,常规的分类问题很少这么极端的。然而,我们知道语言模型本质上也是一个分类模型,它的类别数也就是词表的总大小,往往是远超过向量维度的,那么我们的语言模型是否有“无法预测的词”?(只考虑Greedy解码)
是否存在
ACL2022的论文《Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice》首先探究了这个问题,正如其标题所言,答案是“理论上存在但实际出现概率很小”。
13
Sep
大词表语言模型在续写任务上的一个问题及对策
By 苏剑林 | 2023-09-13 | 38037位读者 | 引用对于LLM来说,通过增大Tokenizer的词表来提高压缩率,从而缩短序列长度、降低解码成本,是大家都喜闻乐见的事情。毕竟增大词表只需要增大Embedding层和输出的Dense层,这部分增加的计算量几乎不可感知,但缩短序列长度之后带来的解码速度提升却是实打实的。当然,增加词表大小也可能会对模型效果带来一些负面影响,所以也不能无节制地增加词表大小。本文就来分析增大词表后语言模型在续写任务上会出现的一个问题,并提出参考的解决方案。
优劣分析
增加词表大小的好处是显而易见的。一方面,由于LLM是自回归的,它的解码会越来越慢,而“增大词表 → 提高压缩率 → 缩短序列长度”,换言之相同文本对应的tokens数变少了,也就是解码步数变少了,从而解码速度提升了;另一方面,语言模型的训练方式是Teacher Forcing,缩短序列长度能够缓解Teacher Forcing带来的Exposure Bias问题,从而可能提升模型效果。
1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 386503位读者 | 引用话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 127660位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
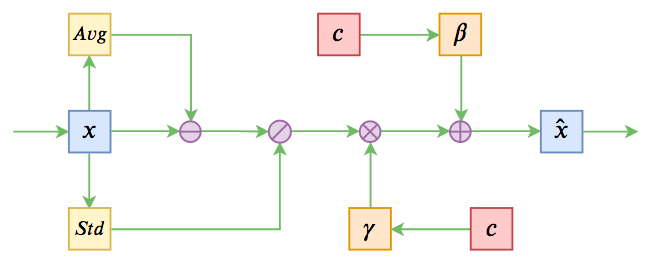
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。

最近评论