






30
Aug
从费马大定理谈起(八):艾森斯坦整数
By 苏剑林 | 2014-08-30 | 43813位读者 | 引用
Gotthold_Eisenstein
是时候向n=3进军了,为了证明这个情况,我们需要一个新的数环:艾森斯坦整数(Eisenstein Integer)。艾森斯坦是德国著名数学家,同时代的高斯曾经评价:“只有三个划时代的数学家:阿基米德,牛顿和艾森斯坦。”足见艾森斯坦的成就斐然。事实上,阅读费马大定理的研究史,同时也是在阅读数学名人录——没有超高的数学,几乎不可能在费马大定理中有所建树。
基本定义
跟高斯整数一样,艾森斯坦整数也是复整数的一种,其中,高斯整数是以1和$i$为基,$i$其实是一个四次单位根,也就是$x^4-1=0$的一个非实数根,因此高斯整数也叫做四次分圆整数;而艾森斯坦整数以1和$\omega$为基,$\omega$是三次单位根,也就是$x^3-1=0$的一个非实数根。任意一个艾森斯坦整数都可以记为$a+b\omega,\,a,b\in\mathbb{Z}$,艾森斯坦整数环记为$\mathbb{Z}[\omega]$,也称为三次分圆整数环。
21
Jan
怎么会这么巧!背后的隐藏信息
By 苏剑林 | 2015-01-21 | 37921位读者 | 引用假设我是一名中学数学老师,在给学生兴致勃勃地讲“素数”,讲完素数的定义和相关性质后,正当我接着往下讲时,有个捣蛋的学生提问,“老师,你能不能举一个三位数的素数?”。可是我手头上没有1000以内的素数表,我也没记住超过100的素数,那怎么办呢?我只好在黑板上写出几个三位数,比如173、211、463,然后跟学生说“让我们来检验这些数是不是素数”。最终的结果是:它们都是素数!然后会有学生疑问:怎么会这么巧?
素数的概率
首先的问题是,任意写一个三位数,它是素数的概率是多少?三位数的素数共有143个,三位数共有900个,于是概率应该是143/900,大约是六分之一。看起来挺低的,要“蒙中”似乎不容易。
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 220226位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
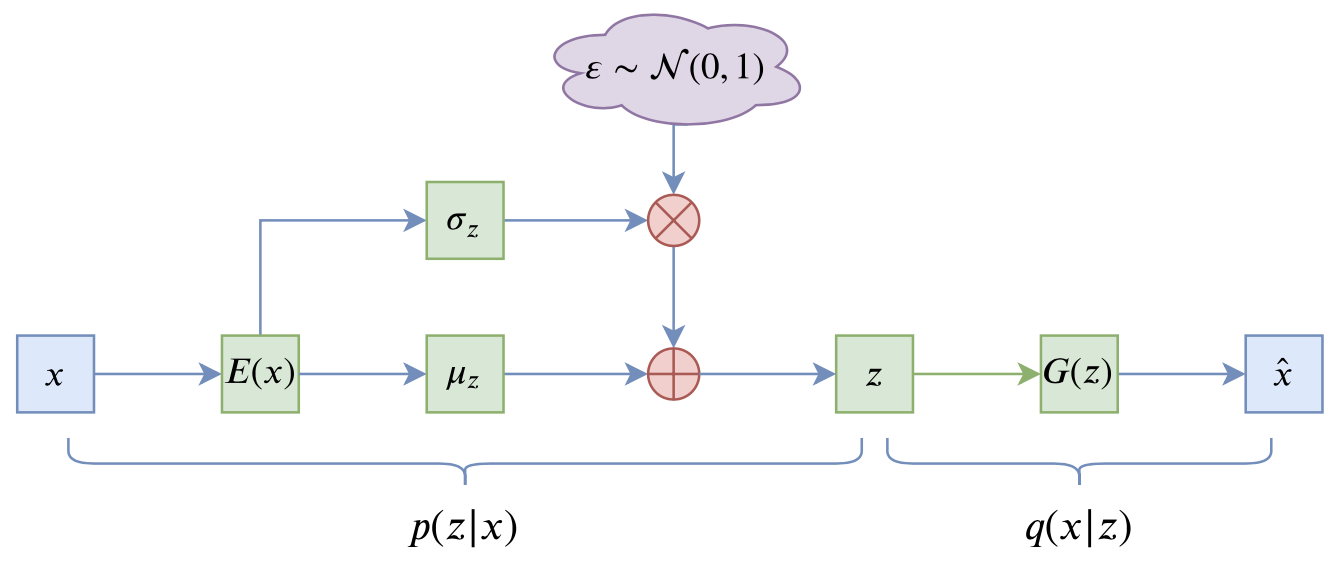
VAE训练流程图示
13
Jan
当概率遇上复变:从二项分布到泊松分布
By 苏剑林 | 2015-01-13 | 25747位读者 | 引用泊松分布,适合于描述单位时间内随机事件发生的次数的概率分布,如某一服务设施在一定时间内受到的服务请求的次数、汽车站台的候客人数等。[维基百科]泊松分布也可以作为小概率的二项分布的近似,其推导过程在一般的概率论教材都会讲到。可是一般教材上给出的证明并不是那么让人赏心悦目,如《概率论与数理统计教程》(第二版,茆诗松等编)的第98页就给出的证明过程。那么,哪个证明过程才更让人点赞呢?我认为是利用母函数的证明。
二项分布的母函数为
$$\begin{equation}(q+px)^n,\quad q=1-p\end{equation}$$
7
Dec
一阶偏微分方程的特征线法
By 苏剑林 | 2017-12-07 | 85609位读者 | 引用本文以尽可能清晰、简明的方式来介绍了一阶偏微分方程的特征线法。个人认为这是偏微分方程理论中较为简单但事实上又容易让人含糊的一部分内容,因此尝试以自己的文字来做一番介绍。当然,更准确来说其实是笔者自己的备忘。
拟线性情形
一般步骤
考虑偏微分方程
$$\begin{equation}\boldsymbol{\alpha}(\boldsymbol{x},u) \cdot \frac{\partial}{\partial \boldsymbol{x}} u = \beta(\boldsymbol{x},u)\end{equation}$$
其中$\boldsymbol{\alpha}$是一个$n$维向量函数,$\beta$是一个标量函数,$\cdot$是向量的点积,$u\equiv u(\boldsymbol{x})$是$n$元函数,$\boldsymbol{x}$是它的自变量。
13
Nov
ARXIV数学论文分布:偏微分方程最热门!
By 苏剑林 | 2015-11-13 | 33417位读者 | 引用笔者成功地保研到了中山大学的基础数学专业,这个专业自然是比较理论性的,虽然如此,我还会保持着我对数据分析、计算机等方面的兴趣。这几天兴致来了,想做一下结合我的专业跟数据挖掘相结合的研究,所以就爬取了ARXIV上面近五年(2010年到2014年)的数学论文(包含的数据有:标题、分类、年份、月份),想对这几年来数学的“行情”做一下简单的分析。个人认为,ARVIX作为目前全球最大的论文预印本的电子数据库,对它的数据进行分析,所得到的结论是能够具有一定的代表性的。
当然,本文只是用来练手爬虫和基本数据分析的文章,并没有挖掘出特别有价值的信息。文末附录了笔者爬取到的数据,供有兴趣的读者进一步分析研究。
整体情况
这五年来,ARXIV的数学论文总数为135009篇,平均每年27000篇,或者每天74篇。
1
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(一)
By 苏剑林 | 2015-12-01 | 87226位读者 | 引用熵的概念
作为一名物理爱好者,我一直对统计力学中“熵”这个概念感到神秘和好奇。因此,当我接触数据科学的时候,我也对最大熵模型产生了浓厚的兴趣。
熵是什么?在通俗的介绍中,熵一般有两种解释:(1)熵是不确定性的度量;(2)熵是信息的度量。看上去说的不是一回事,其实它们说的就是同一个意思。首先,熵是不确定性的度量,它衡量着我们对某个事物的“无知程度”。熵为什么又是信息的度量呢?既然熵代表了我们对事物的无知,那么当我们从“无知”到“完全认识”这个过程中,就会获得一定的信息量,我们开始越无知,那么到达“完全认识”时,获得的信息量就越大,因此,作为不确定性的度量的熵,也可以看作是信息的度量,说准确点,是我们能从中获得的最大的信息量。
2
Jun
路径积分系列:3.路径积分
By 苏剑林 | 2016-06-02 | 77885位读者 | 引用路径积分是量子力学的一种描述方法,源于物理学家费曼[5],它是一种泛函积分,它已经成为现代量子理论的主流形式. 近年来,研究人员对它的兴趣愈发增加,尤其是它在量子领域以外的应用,出现了一些著作,如[7]. 但在国内了解路径积分的人并不多,很多量子物理专业的学生可能并没有听说过路径积分.
从数学角度来看,路径积分是求偏微分方程的Green函数的一种方法. 我们知道,在偏微分方程的研究中,如果能够求出对应的Green函数,那么对偏微分方程的研究会大有帮助,而通常情况下Green函数并不容易求解. 但构建路径积分只需要无穷小时刻的Green函数,因此形式和概念上都相当简单.
本章并没有新的内容,只是做了一个尝试:从随机游走问题出发,给出路径积分的一个简明而直接的介绍,展示了如何将抛物型的偏微分方程问题转化为路径积分形式.
从点的概率到路径的概率
在上一章对随机游走的研究中,我们得出从$x_0$出发,$t$时间后,走到$x_n$处的概率密度为
$$\frac{1}{\sqrt{2\pi \alpha T}}\exp\left(-\frac{(x_n-x_0)^2}{2\alpha t}\right).\tag{22}$$
这是某时刻某点到另一个时刻另一点的概率,在数学上,我们称之为扩散方程$(21)$的传播子,或者Green函数.

最近评论