






9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 104021位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 86860位读者 | 引用
24
Feb
CRF用过了,不妨再了解下更快的MEMM?
By 苏剑林 | 2020-02-24 | 51550位读者 | 引用HMM、MEMM、CRF被称为是三大经典概率图模型,在深度学习之前的机器学习时代,它们被广泛用于各种序列标注相关的任务中。一个有趣的现象是,到了深度学习时代,HMM和MEMM似乎都“没落”了,舞台上就只留下CRF。相信做NLP的读者朋友们就算没亲自做过也会听说过BiLSTM+CRF做中文分词、命名实体识别等任务,却几乎没有听说过BiLSTM+HMM、BiLSTM+MEMM的,这是为什么呢?
今天就让我们来学习一番MEMM,并且通过与CRF的对比,来让我们更深刻地理解概率图模型的思想与设计。
模型推导
MEMM全称Maximum Entropy Markov Model,中文名可译为“最大熵马尔可夫模型”。不得不说,这个名字可能会吓退80%的初学者:最大熵还没搞懂,马尔可夫也不认识,这两个合起来怕不是天书?而事实上,不管是MEMM还是CRF,它们的模型都远比它们的名字来得简单,它们的概念和设计都非常朴素自然,并不难理解。
9
Mar
Seq2Seq中Exposure Bias现象的浅析与对策
By 苏剑林 | 2020-03-09 | 100110位读者 | 引用前些天笔者写了《CRF用过了,不妨再了解下更快的MEMM?》,里边提到了MEMM的局部归一化和CRF的全局归一化的优劣。同时,笔者联想到了Seq2Seq模型,因为Seq2Seq模型的典型训练方案Teacher Forcing就是一个局部归一化模型,所以它也存在着局部归一化所带来的毛病——也就是我们经常说的“Exposure Bias”。带着这个想法,笔者继续思考了一翻,将最后的思考结果记录在此文。

经典的Seq2Seq模型图示
本文算是一篇进阶文章,适合对Seq2Seq模型已经有一定的了解、希望进一步提升模型的理解或表现的读者。关于Seq2Seq的入门文章,可以阅读旧作《玩转Keras之seq2seq自动生成标题》和《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。
本文的内容大致为:
1、Exposure Bias的成因分析及例子;
2、简单可行的缓解Exposure Bias问题的策略。
7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 114922位读者 | 引用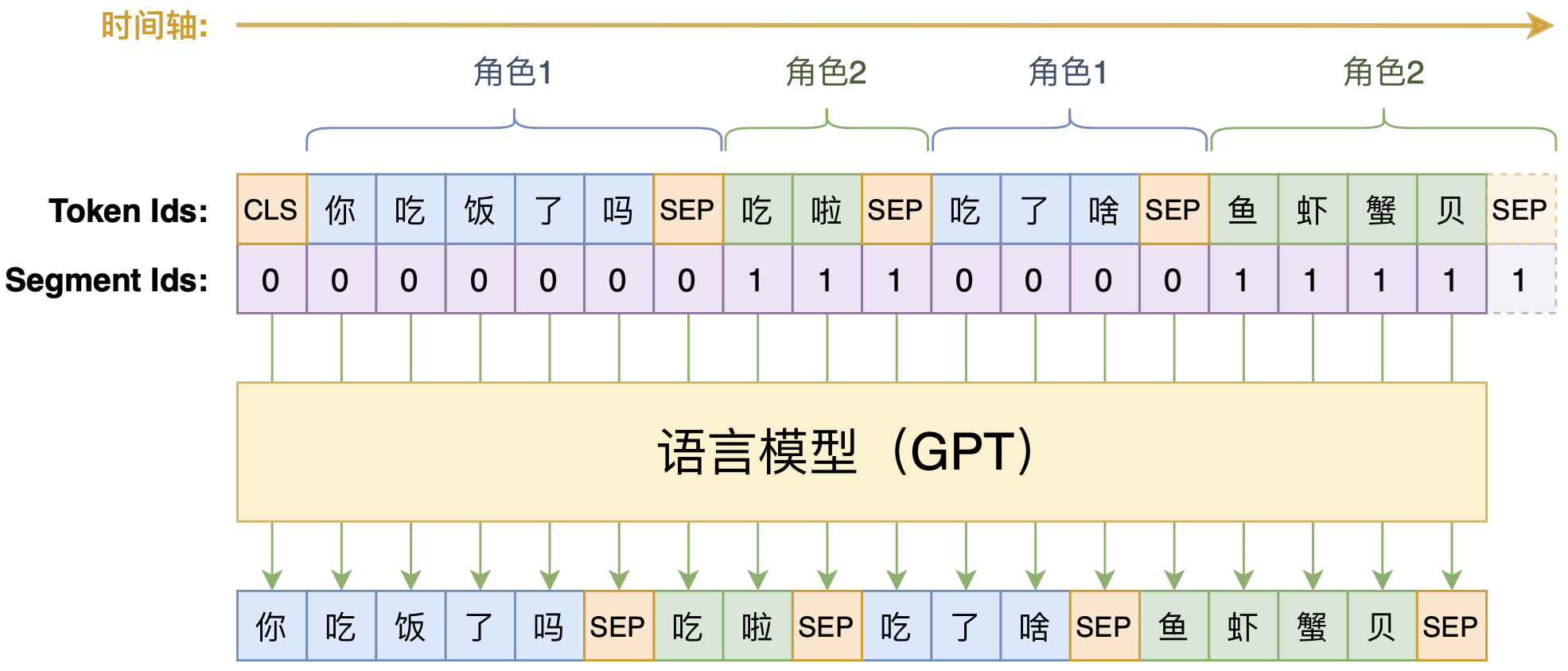
23
Jun
从采样看优化:可导优化与不可导优化的统一视角
By 苏剑林 | 2020-06-23 | 62513位读者 | 引用不少读者都应该知道,损失函数与评测指标的不一致性是机器学习的典型现象之一,比如分类问题中损失函数用交叉熵,评测指标则是准确率或者F1,又比如文本生成中损失函数是teacher-forcing形式的交叉熵,评测指标则是BLEU、ROUGE等。理想情况下,当然是评测什么指标,我们就去优化这个指标,然而评测指标通常都是不可导的,而我们多数都是使用基于梯度的优化器,这就要求最小化的目标必须是可导的,这是不一致性的来源。
前些天在arxiv刷到了一篇名为《MLE-guided parameter search for task loss minimization in neural sequence modeling》的论文,顾名思义,它是研究如何直接优化文本生成的评测指标的。经过阅读,笔者发现这篇论文很有价值,事实上它提供了一种优化评测指标的新思路,适用范围并不局限于文本生成中。不仅如此,它甚至还包含了一种理解可导优化与不可导优化的统一视角。
采样视角
首先,我们可以通过采样的视角来重新看待优化问题:设模型当前参数为$\theta$,优化目标为$l(\theta)$,我们希望决定下一步的更新量$\Delta\theta$,为此,我们先构建分布
\begin{equation}p(\Delta\theta|\theta)=\frac{e^{-[l(\theta + \Delta\theta) - l(\theta)]/\alpha}}{Z(\theta)},\quad Z(\theta) = \int e^{-[l(\theta + \Delta\theta) - l(\theta)]/\alpha} d(\Delta\theta)\end{equation}
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 100263位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 60279位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
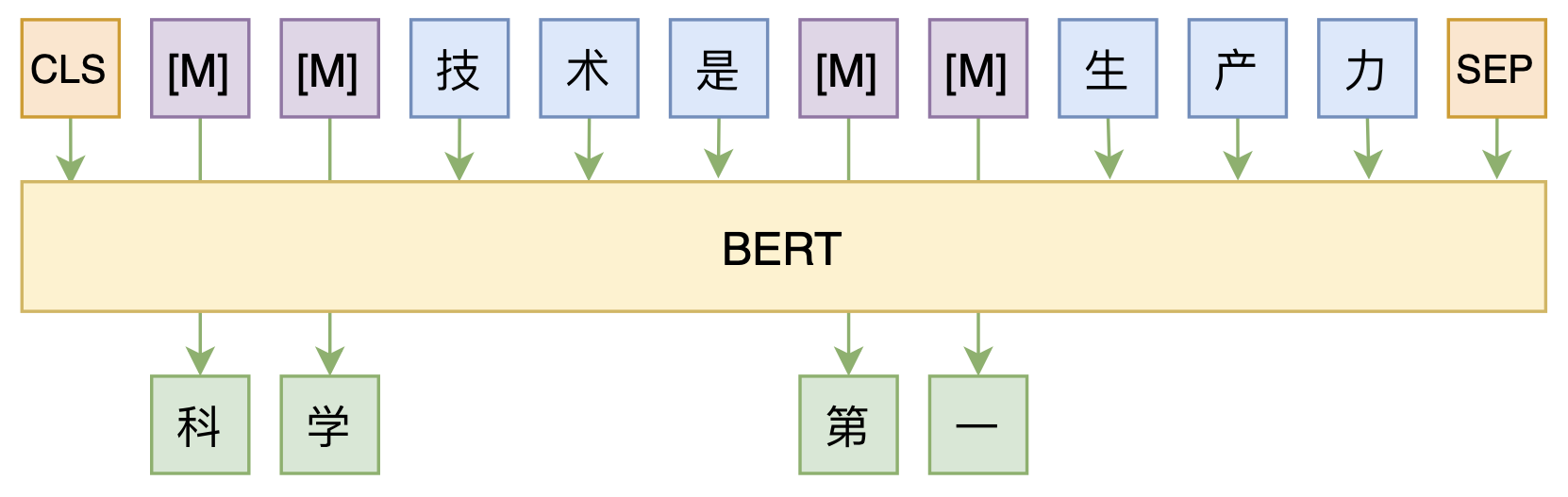
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。

最近评论