






19
Sep
Softmax后传:寻找Top-K的光滑近似
By 苏剑林 | 2024-09-19 | 33961位读者 | 引用Softmax,顾名思义是“soft的max”,是$\max$算子(准确来说是$\text{argmax}$)的光滑近似,它通过指数归一化将任意向量$\boldsymbol{x}\in\mathbb{R}^n$转化为分量非负且和为1的新向量,并允许我们通过温度参数来调节它与$\text{argmax}$(的one hot形式)的近似程度。除了指数归一化外,我们此前在《通向概率分布之路:盘点Softmax及其替代品》也介绍过其他一些能实现相同效果的方案。
我们知道,最大值通常又称Top-1,它的光滑近似方案看起来已经相当成熟,那读者有没有思考过,一般的Top-$k$的光滑近似又是怎么样的呢?下面让我们一起来探讨一下这个问题。
问题描述
设向量$\boldsymbol{x}=(x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$,简单起见我们假设它们两两不相等,即$i\neq j \Leftrightarrow x_i\neq x_j$。记$\Omega_k(\boldsymbol{x})$为$\boldsymbol{x}$最大的$k$个分量的下标集合,即$|\Omega_k(\boldsymbol{x})|=k$以及$\forall i\in \Omega_k(\boldsymbol{x}), j \not\in \Omega_k(\boldsymbol{x})\Rightarrow x_i > x_j$。我们定义Top-$k$算子$\mathcal{T}_k$为$\mathbb{R}^n\mapsto\{0,1\}^n$的映射:
\begin{equation}
[\mathcal{T}_k(\boldsymbol{x})]_i = \left\{\begin{aligned}1,\,\, i\in \Omega_k(\boldsymbol{x}) \\ 0,\,\, i \not\in \Omega_k(\boldsymbol{x})\end{aligned}\right.
\end{equation}
说白了,如果$x_i$属于最大的$k$个元素之一,那么对应的位置变成1,否则变成0,最终结果是一个Multi-Hot向量,比如$\mathcal{T}_2([3,2,1,4]) = [1,0,0,1]$。
15
Aug
让MathJax更好地兼容谷歌翻译和延时加载
By 苏剑林 | 2024-08-15 | 20625位读者 | 引用很早之前,就有读者提出希望把Cool Papers上面的数学公式渲染一下,因为很多偏数学的论文,它们的摘要甚至标题上都带有LaTeX代码写的数学公式,如果不把这些公式渲染出来,那么看上去就像是一堆乱码,确实会比较影响阅读体验。然而,之前的测试显示,负责渲染公式的MathJax跟谷歌翻译和延时加载都不大兼容,所以尽管需求存在已久,但笔者一直没有把它加上去。
不过好消息是,经过反复查阅和调试,这两天笔者总算把兼容性问题解决了,所以现在大家看到的Cool Papers已经能够渲染数学公式了。这篇文章总结一下解决方案,供大家参考。

摘要带有公式的论文
14
Nov
当Batch Size增大时,学习率该如何随之变化?
By 苏剑林 | 2024-11-14 | 37199位读者 | 引用随着算力的飞速进步,有越多越多的场景希望能够实现“算力换时间”,即通过堆砌算力来缩短模型训练时间。理想情况下,我们希望投入$n$倍的算力,那么达到同样效果的时间则缩短为$1/n$,此时总的算力成本是一致的。这个“希望”看上去很合理和自然,但实际上并不平凡,即便我们不考虑通信之类的瓶颈,当算力超过一定规模或者模型小于一定规模时,增加算力往往只能增大Batch Size。然而,增大Batch Size一定可以缩短训练时间并保持效果不变吗?
这就是接下来我们要讨论的话题:当Batch Size增大时,各种超参数尤其是学习率该如何调整,才能保持原本的训练效果并最大化训练效率?我们也可以称之为Batch Size与学习率之间的Scaling Law。
方差视角
直觉上,当Batch Size增大时,每个Batch的梯度将会更准,所以步子就可以迈大一点,也就是增大学习率,以求更快达到终点,缩短训练时间,这一点大体上都能想到。问题就是,增大多少才是最合适的呢?
26
Sep
利用“熄火保护 + 通断器”实现燃气灶智能关火
By 苏剑林 | 2024-09-26 | 18667位读者 | 引用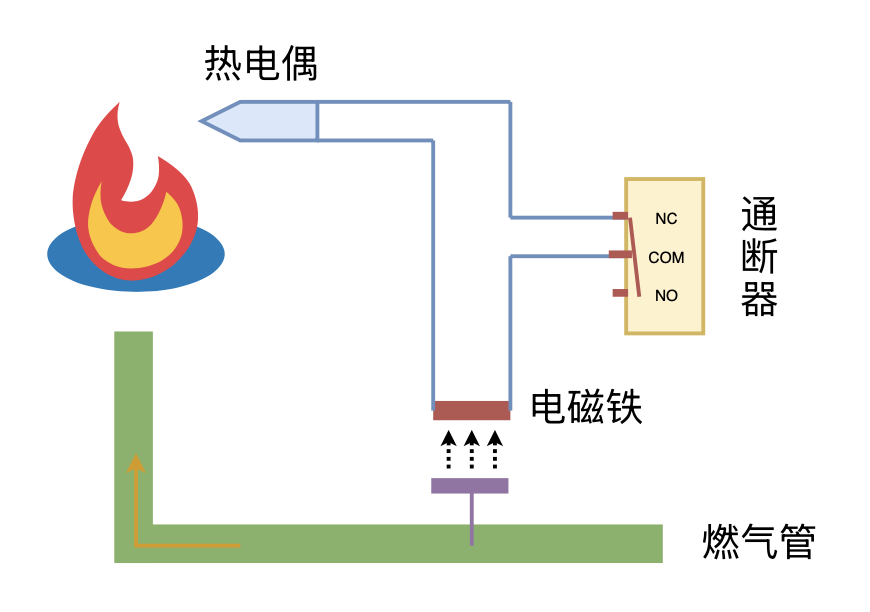
11
Oct
低秩近似之路(三):CR
By 苏剑林 | 2024-10-11 | 20663位读者 | 引用在《低秩近似之路(二):SVD》中,我们证明了SVD可以给出任意矩阵的最优低秩近似。那里的最优近似是无约束的,也就是说SVD给出的结果只管误差上的最小,不在乎矩阵的具体结构,而在很多应用场景中,出于可解释性或者非线性处理等需求,我们往往希望得到具有某些特殊结构的近似分解。
因此,从这篇文章开始,我们将探究一些具有特定结构的低秩近似,而本文将聚焦于其中的CR近似(Column-Row Approximation),它提供了加速矩阵乘法运算的一种简单方案。
问题背景
矩阵的最优$r$秩近似的一般提法是
\begin{equation}\mathop{\text{argmin}}_{\text{rank}(\tilde{\boldsymbol{M}})\leq r}\Vert \tilde{\boldsymbol{M}} - \boldsymbol{M}\Vert_F^2\label{eq:loss-m2}\end{equation}
30
Oct
低秩近似之路(四):ID
By 苏剑林 | 2024-10-30 | 22199位读者 | 引用这篇文章的主角是ID(Interpolative Decomposition),中文可以称之为“插值分解”,它同样可以理解为是一种具有特定结构的低秩分解,其中的一侧是该矩阵的若干列(当然如果你偏好于行,那么选择行也没什么问题),换句话说,ID试图从一个矩阵中找出若干关键列作为“骨架”(通常也称作“草图”)来逼近原始矩阵。
可能很多读者都未曾听说过ID,即便维基百科也只有几句语焉不详的介绍(链接),但事实上,ID跟SVD一样早已内置在SciPy之中(参考scipy.linalg.interpolative),这侧面印证了ID的实用价值。
基本定义
前三篇文章我们分别介绍了伪逆、SVD、CR近似,它们都可以视为寻找特定结构的低秩近似:
\begin{equation}\mathop{\text{argmin}}_{\text{rank}(\tilde{\boldsymbol{M}})\leq r}\Vert \tilde{\boldsymbol{M}} - \boldsymbol{M}\Vert_F^2\end{equation}
6
Nov
VQ的又一技巧:给编码表加一个线性变换
By 苏剑林 | 2024-11-06 | 31332位读者 | 引用在《VQ的旋转技巧:梯度直通估计的一般推广》中,我们介绍了VQ(Vector Quantization)的Rotation Trick,它的思想是通过推广VQ的STE(Straight-Through Estimator)来为VQ设计更好的梯度,从而缓解VQ的编码表坍缩、编码表利用率低等问题。
无独有偶,昨天发布在arXiv上的论文《Addressing Representation Collapse in Vector Quantized Models with One Linear Layer》提出了改善VQ的另一个技巧:给编码表加一个线性变换。这个技巧单纯改变了编码表的参数化方式,不改变VQ背后的理论框架,但实测效果非常优异,称得上是简单有效的经典案例。
18
Nov
Adam的epsilon如何影响学习率的Scaling Law?
By 苏剑林 | 2024-11-18 | 21265位读者 | 引用上一篇文章《当Batch Size增大时,学习率该如何随之变化?》我们从多个角度讨论了学习率与Batch Size之间的缩放规律,其中对于Adam优化器我们采用了SignSGD近似,这是分析Adam优化器常用的手段。那么一个很自然的问题就是:用SignSGD来近似Adam究竟有多科学呢?
我们知道,Adam优化器的更新量分母会带有一个$\epsilon$,初衷是预防除零错误,所以其值通常很接近于零,以至于我们做理论分析的时候通常选择忽略掉它。然而,当前LLM的训练尤其是低精度训练,我们往往会选择偏大的$\epsilon$,这导致在训练的中、后期$\epsilon$往往已经超过梯度平方大小,所以$\epsilon$的存在事实上已经不可忽略。
因此,这篇文章我们试图探索$\epsilon$如何影响Adam的学习率与Batch Size的Scaling Law,为相关问题提供一个参考的计算方案。

最近评论