






9
Sep
[欧拉数学]找出严谨的答案
By 苏剑林 | 2013-09-09 | 19285位读者 | 引用在之前的一些文章中,我们已经谈到过欧拉数学。总体上来讲,欧拉数学就是具有创造性的、直觉性的技巧和方法,这些方法能够推导出一些漂亮的结果,而方法本身却并不严密。然而,在很多情况下,严密与直觉只是一步之遥。接下来要介绍的是我上学期《数学分析》期末考的一道试题,而我解答这道题的灵感来源便是“欧拉数学”。
数列${a_n}$是递增的正数列,求证:$\sum\limits_{n=1}^{\infty}\left(1-\frac{a_n}{a_{n+1}}\right)$收敛等价于${a_n}$收敛。
据说参考答案给出的方法是利用数列的柯西收敛准则,我也没有仔细去看,我在探索自己的更富有直觉型的方法。这就是所谓的“I do not understand what I can not create.”。下面是我的思路。
ODE的坐标变换
熟悉理论力学的读者应该能够领略到变分法在变换坐标系中的作用。比如,如果要将下面的平面二体问题方程
$$\left\{\begin{aligned}\frac{d^2 x}{dt^t}=\frac{-\mu x}{(x^2+y^2)^{3/2}}\\
\frac{d^2 y}{dt^t}=\frac{-\mu y}{(x^2+y^2)^{3/2}}\end{aligned}\right.\tag{1}$$
变换到极坐标系下,如果直接代入计算,将会是一道十分繁琐的计算题。但是,我们知道,上述方程只不过是作用量
$$S=\int \left[\frac{1}{2}\left(\dot{x}^2+\dot{y}^2\right)+\frac{\mu}{\sqrt{x^2+y^2}}\right]dt\tag{2}$$
变分之后的拉格朗日方程,那么我们就可以直接对作用量进行坐标变换。而由于作用量一般只涉及到了一阶导数,因此作用量的变换一般来说比较简单。比如,很容易写出,$(2)$在极坐标下的形式为
$$S=\int \left[\frac{1}{2}\left(\dot{r}^2+r^2\dot{\theta}^2\right)+\frac{\mu}{r}\right]dt\tag{3}$$
对$(3)$进行变分,得到的拉格朗日方程为
$$\left\{\begin{aligned}&\ddot{r}=r\dot{\theta}^2-\frac{\mu}{r^2}\\
&\frac{d}{dt}\left(r^2\dot{\theta}\right)=0\end{aligned}\right.\tag{4}$$
就这样完成了坐标系的变换。如果想直接代入$(1)$暴力计算,那么请参考《方程与宇宙》:二体问题的来来去去(一)
19
Apr
柯西命题:盯着它到显然成立为止!
By 苏剑林 | 2015-04-19 | 43195位读者 | 引用数学分析中数列极限部分,有一个很基本的“柯西命题”:
如果$\lim_{n\to\infty} x_n=a$,则
$$\lim_{n\to\infty}\frac{x_1+x_2+\dots+x_n}{n}=a$$
本文所要谈的便是这个命题,当然还包括类似的一些题目。
柯西命题的证明
柯西命题的证明并不难,只需要根据极限收敛的定义,由于$\lim_{n\to\infty} x_n=a$,所以任意给定$\varepsilon > 0$,存在足够大的$N$,使得对于任意的$n > N$,都有
$$\left|x_n - a\right| < \varepsilon/2\quad(\forall n > N)$$
3
Aug
运动相机测试:家乡的星空
By 苏剑林 | 2016-08-03 | 37842位读者 | 引用记得很早之前就想尝试一下拍星空,无奈一直都没有设备。以前只知道单反可以拍星空,因此,一直以来的想法就是有钱了就去买台单反。因为各种原因一拖再拖,最后慢慢觉得,对于我这种三分钟热度的人来说,单反的意义还真的不是很大。
这两年,在小米的鼓吹下,小蚁运动相机在国内算是慢慢掀起了一股运动相机潮。这种相机的特点是小巧、灵活,价格也不贵(相比单反)。灵活不仅仅是说它便于携带,而且还是功能上的灵活,比如一代小蚁还支持编程拍摄!(写程序控制快门、ISO、拍摄间隔,并实现定时拍摄等)这样当然很快就吸引了我,在小蚁2代众筹之时,我也咬咬牙,入了一台。
前两天回到家,刚好晴夜,马上就试了一下拍星空的效果。下面是在我家楼顶拍的,用ISO400曝光30秒的效果:

家乡的星空
6
Dec
人生苦短,我用Python!
By 苏剑林 | 2015-12-06 | 56222位读者 | 引用
15
Apr
斯特灵(stirling)公式与渐近级数
By 苏剑林 | 2016-04-15 | 58915位读者 | 引用斯特灵近似,或者称斯特灵公式,最开始是作为阶乘的近似提出
$$n!\sim \sqrt{2\pi n}\left(\frac{n}{e}\right)^n$$
符号$\sim$意味着
$$\lim_{n\to\infty}\frac{\sqrt{2\pi n}\left(\frac{n}{e}\right)^n}{n!}=1$$
将斯特灵公式进一步提高精度,就得到所谓的斯特灵级数
$$n!=\sqrt{2\pi n}\left(\frac{n}{e}\right)^n\left(1+\frac{1}{12n}+\frac{1}{288n^2}\dots\right)$$
很遗憾,这个是渐近级数。
相关资料有:
https://zh.wikipedia.org/zh-cn/斯特灵公式
https://en.wikipedia.org/wiki/Stirling%27s_approximation
本文将会谈到斯特灵公式及其渐近级数的一个改进的推导,并解释渐近级数为什么渐近。
3
Dec
词向量与Embedding究竟是怎么回事?
By 苏剑林 | 2016-12-03 | 273053位读者 | 引用词向量,英文名叫Word Embedding,按照字面意思,应该是词嵌入。说到词向量,不少读者应该会立马想到Google出品的Word2Vec,大牌效应就是不一样。另外,用Keras之类的框架还有一个Embedding层,也说是将词ID映射为向量。由于先入为主的意识,大家可能就会将词向量跟Word2Vec等同起来,而反过来问“Embedding是哪种词向量?”这类问题,尤其是对于初学者来说,应该是很混淆的。事实上,哪怕对于老手,也不一定能够很好地说清楚。
这一切,还得从one hot说起...
五十步笑百步
one hot,中文可以翻译为“独热”,是最原始的用来表示字、词的方式。为了简单,本文以字为例,词也是类似的。假如词表中有“科、学、空、间、不、错”六个字,one hot就是给这六个字分别用一个0-1编码:
$$\begin{array}{c|c}\hline\text{科} & [1, 0, 0, 0, 0, 0]\\
\text{学} & [0, 1, 0, 0, 0, 0]\\
\text{空} & [0, 0, 1, 0, 0, 0]\\
\text{间} & [0, 0, 0, 1, 0, 0]\\
\text{不} & [0, 0, 0, 0, 1, 0]\\
\text{错} & [0, 0, 0, 0, 0, 1]\\
\hline
\end{array}$$
15
Jan
SVD分解(一):自编码器与人工智能
By 苏剑林 | 2017-01-15 | 48478位读者 | 引用咋看上去,SVD分解是比较传统的数据挖掘手段,自编码器是深度学习中一个比较“先进”的概念,应该没啥交集才对。而本文则要说,如果不考虑激活函数,那么两者将是等价的。进一步的思考就可以发现,不管是SVD还是自编码器,我们降维,并不是纯粹地为了减少储存量或者减少计算量,而是“智能”的初步体现。
等价性
假设有一个$m$行$n$列的庞大矩阵$M_{m\times n}$,这可能使得计算甚至存储上都成问题,于是考虑一个分解,希望找到矩阵$A_{m\times k}$和$B_{k\times n}$,使得
$$M_{m\times n}=A_{m\times k}\times B_{k\times n}$$
这里的乘法是矩阵乘法。如图
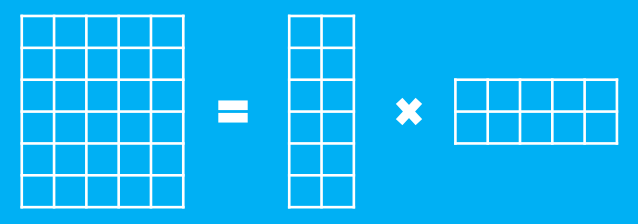
SVD

最近评论