






6
Jun
收到新版《量子力学与路径积分》
By 苏剑林 | 2015-06-06 | 40366位读者 | 引用
《量子力学与路径积分》封面
今天收到高教出版社的王超编辑寄来的费曼著作新版《量子力学与路径积分》了,兴奋ing...
《量子力学与路径积分》是费曼的一本经典著作,更是量子力学的经典著作——它是我目前读过的唯一一本从路径积分出发、并且以路径积分为第一性原理的量子力学著作(徐一鸿的《简明量子场论》好象是我读过的唯一一本纯粹以路径积分为方法的量子场论著作,也非常不错),其它类型的量子力学著作,也有部分谈到路径积分,但无一不是从哈密顿形式中引出路径积分的,在那种情况之下,路径积分只能算是一个推论。但是路径积分明明就作为量子力学的三种形式之一,它应该是可以作为量子力学的基本原理来提出的,而不应该作为另一种形式的推论。费曼做了尝试——从路径积分出发讲解量子力学,而且显然这种尝试是很成功的,至少对于我来说,路径积分是一种非常容易理解的量子力学形式。(这也许跟我的数学基础有关)
30
Aug
封闭曲线所围成的面积:一个新技巧
By 苏剑林 | 2015-08-30 | 62210位读者 | 引用本文主要做了一个尝试,尝试不通过Green公式而实现将封闭曲线的面积与线积分相互转换。这种转换的思路,因为仅仅利用了二重积分的积分变换,较为容易理解,而且易于推广。至于这种技巧是否真正具有实际价值,还请读者评论。
假设平面上一条简单封闭曲线由以下参数方程给出:
$$\begin{equation}\left\{\begin{aligned}x = f(t)\\y = g(t)\end{aligned}\right.\end{equation}$$
其中参数$t$位于某个区间$[a,b]$上,即$f(a)=f(b),g(a)=g(b)$。现在的问题是,求该封闭曲线围成的区域的面积。
15
Jul
漫话模型|模型与选芒果
By 苏剑林 | 2015-07-15 | 37619位读者 | 引用很多人觉得“模型”、“大数据”、“机器学习”这些字眼很高大很神秘,事实上,它跟我们生活中选水果差不了多少。本文用了几千字,来试图教会大家怎么选芒果...
模型的比喻

芒果
假如我要从一批芒果中,找出好吃的那个来。而我不能直接切开芒果尝尝,所以我只能观察芒果,能观察到的量有颜色、表面的气味、大小等等,这些就是我们能够收集到的信息(特征)。
生活中还要很多这样的例子,比如买火柴(可能年轻的城里人还没见过火柴?),如何判断一盒火柴的质量?难道要每根火柴都划划,看看着不着火?显然不行,我们最多也只能划几根,全部划了,火柴也不成火柴了。当然,我们还能看看火柴的样子,闻闻火柴的气味,这些动作是可以接受的。
最近一直在考虑一些自然语言处理问题和一些非线性分析问题,无暇总结发文,在此表示抱歉。本文要说的是对于一阶非线性差分方程(当然高阶也可以类似地做)的一种摄动格式,理论上来说,本方法可以得到任意一阶非线性差分方程的显式渐近解。
非线性差分方程
对于一般的一阶非线性差分方程
$$\begin{equation}\label{chafenfangcheng}x_{n+1}-x_n = f(x_n)\end{equation}$$
通常来说,差分方程很少有解析解,因此要通过渐近分析等手段来分析非线性差分方程的性质。很多时候,我们首先会考虑将差分替换为求导,得到微分方程
$$\begin{equation}\label{weifenfangcheng}\frac{dx}{dn}=f(x)\end{equation}$$
作为差分方程$\eqref{chafenfangcheng}$的近似。其中的原因,除了微分方程有比较简单的显式解之外,另一重要原因是微分方程$\eqref{weifenfangcheng}$近似保留了差分方程$\eqref{chafenfangcheng}$的一些比较重要的性质,如渐近性。例如,考虑离散的阻滞增长模型:
$$\begin{equation}\label{zuzhizengzhang}x_{n+1}=(1+\alpha)x_n -\beta x_n^2\end{equation}$$
对应的微分方程为(差分替换为求导):
$$\begin{equation}\frac{dx}{dn}=\alpha x -\beta x^2\end{equation}$$
此方程解得
$$\begin{equation}x_n = \frac{\alpha}{\beta+c e^{-\alpha n}}\end{equation}$$
其中$c$是任意常数。上述结果已经大概给出了原差分方程$\eqref{zuzhizengzhang}$的解的变化趋势,并且成功给出了最终的渐近极限$x_n \to \frac{\alpha}{\beta}$。下图是当$\alpha=\beta=1$且$c=1$(即$x_0=\frac{1}{2}$)时,微分方程的解与差分方程的解的值比较。
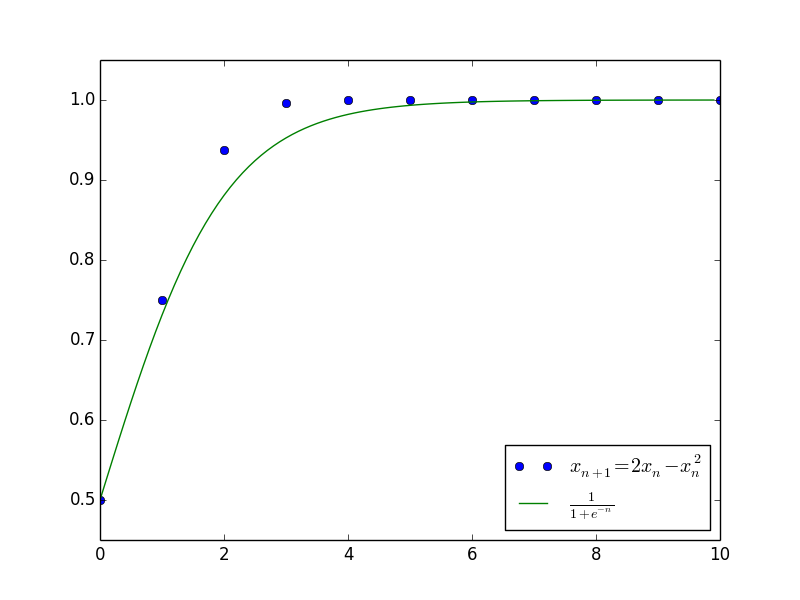
差分方程的摄动法1
现在的问题是,既然微分方程的解可以作为一个形态良好的近似解了,那么是否可以在微分方程的解的基础上,进一步加入修正项提高精度?
7
Mar
通过ssh动态端口转发共享校园资源(附带干货)
By 苏剑林 | 2016-03-07 | 35764位读者 | 引用众所周知,校园网最宝贵的资源应该有两样:一是IPv6,IPv6是访问Google等网站的最理想途径,当然IPv6并非所有高校都有;二是论文库,一般高校都会买了一部分论文库(知网、万方等)的下载权,供校园用户使用。如果说访问Google还有VPN等诸多方式的话,那么对于校外用户来说访问知网等资源就显得格外宝贵了,一般只是叫校内用户下载,或者就只能付费了(那个贵呀!)。
站长还是学生,在学校同时享用着IPv6和论文库资源,确实很爽。自从用上Openwrt的路由之后,一直想着怎么把校园网资源共享出去。曾经考虑过搭建PPTP VPN,但是感觉略有复杂(当然,跟其他VPN相比,搭建PPTP VPN算是非常简单的了,可是我还是不怎么喜欢。),而且当时还没解决内网穿透的问题。最近借助ssh反向代理的方式实现了内网穿透,继而认识到,通过ssh动态端口转发,居然还可以搭建代理,并且实现远程访问内网(校园网)资源,而且几乎不用在路由器本身上面做任何配置。不得不说,ssh真是一个极其强大的东西呀。
添加普通帐号
既然要共享,就没理由把root账户都分享出去了,因此,第一步要实现的是在Openwrt上添加一个代理账号,而且为了安全和保密,这个账号不允许真的登陆服务器进行操作,而只允许进行端口转发。
18
May
调侃:万有引力与爱因斯坦的理论
By 苏剑林 | 2016-05-18 | 48249位读者 | 引用我不是研究引力的,也没有很好地学习过引力。在理论物理方面,我学习经典力学和量子力学比学习广义相对论要多得多。因此,本来我是不应该谈引力的,以免误人子弟。不过,在一次坐车的途中,司机的刹车和加速让我联想到了一些跟引力有关的东西,自我感觉比较有趣,所以发给大家分享一下,也请大家指正。
等效原理

坐汽车
引力,准确来说应该是“万有引力”。所谓“万有”,有两个含义:1、所有物体都能够产生引力;2、所有物体都被引力影响。一个力居然是“万有”的,这让爱因斯坦感觉到非常奇怪,这也是四种基本力之中,引力跟其他力区别最明显的地方。相比之下,电磁相互作用力就只能存在于有“电”的地方,弱相互作用只存在于费米子,等等。
除了引力之外,我们平时还遇到过什么“万有”的力吗?貌似没有。但是我们想象一下,当你坐在一辆长途大巴匀速前进时,突然司机来了一个急刹车,在刹车的那一瞬间,所有人都往前倾了,不仅如此,可能你的行李箱、你的随身物品都往前移的,事实上,车上所有东西都受到了一个往前的力!对于那辆车上的人和物来说,刹车的那一瞬间,就存在着一个“万有”的力!
2
Jun
路径积分系列:3.路径积分
By 苏剑林 | 2016-06-02 | 73604位读者 | 引用路径积分是量子力学的一种描述方法,源于物理学家费曼[5],它是一种泛函积分,它已经成为现代量子理论的主流形式. 近年来,研究人员对它的兴趣愈发增加,尤其是它在量子领域以外的应用,出现了一些著作,如[7]. 但在国内了解路径积分的人并不多,很多量子物理专业的学生可能并没有听说过路径积分.
从数学角度来看,路径积分是求偏微分方程的Green函数的一种方法. 我们知道,在偏微分方程的研究中,如果能够求出对应的Green函数,那么对偏微分方程的研究会大有帮助,而通常情况下Green函数并不容易求解. 但构建路径积分只需要无穷小时刻的Green函数,因此形式和概念上都相当简单.
本章并没有新的内容,只是做了一个尝试:从随机游走问题出发,给出路径积分的一个简明而直接的介绍,展示了如何将抛物型的偏微分方程问题转化为路径积分形式.
从点的概率到路径的概率
在上一章对随机游走的研究中,我们得出从$x_0$出发,$t$时间后,走到$x_n$处的概率密度为
$$\frac{1}{\sqrt{2\pi \alpha T}}\exp\left(-\frac{(x_n-x_0)^2}{2\alpha t}\right).\tag{22}$$
这是某时刻某点到另一个时刻另一点的概率,在数学上,我们称之为扩散方程$(21)$的传播子,或者Green函数.
25
Jun
OCR技术浅探:6. 光学识别
By 苏剑林 | 2016-06-25 | 70742位读者 | 引用经过第一、二步,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别.
模型选择
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型.
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型. 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果. 事实上,我们选择卷积神经网络的主要原因有:
1. 对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2. 比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3. 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的.

最近评论