






23
Jan
揭开迷雾,来一顿美味的Capsule盛宴
By 苏剑林 | 2018-01-23 | 472372位读者 | 引用
Geoffrey Hinton在谷歌多伦多办公室
由深度学习先驱Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,无疑是去年深度学习界最热点的消息之一。得益于各种媒体的各种吹捧,Capsule被冠以了各种神秘的色彩,诸如“抛弃了梯度下降”、“推倒深度学习重来”等字眼层出不穷,但也有人觉得Capsule不外乎是一个新的炒作概念。
本文试图揭开让人迷惘的云雾,领悟Capsule背后的原理和魅力,品尝这一顿Capsule盛宴。同时,笔者补做了一个自己设计的实验,这个实验能比原论文的实验更有力说明Capsule的确产生效果了。
菜谱一览:
1、Capsule是什么?
2、Capsule为什么要这样做?
3、Capsule真的好吗?
4、我觉得Capsule怎样?
5、若干小菜。
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 229806位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
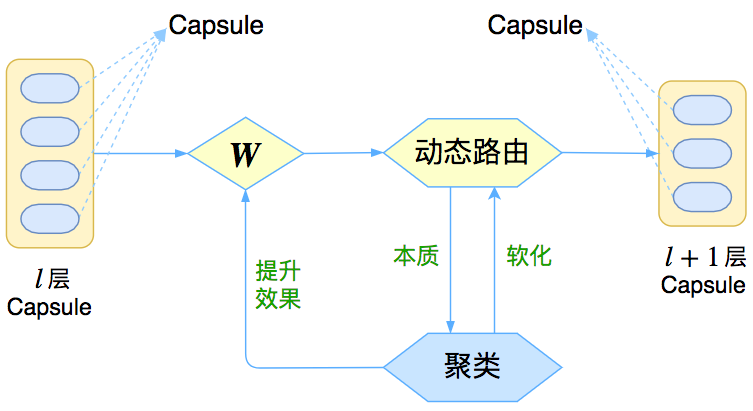
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 168756位读者 | 引用在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
![P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 67418位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
7
Sep
BytePiece:更纯粹、更高压缩率的Tokenizer
By 苏剑林 | 2023-09-07 | 67155位读者 | 引用目前在LLM中最流行的Tokenizer(分词器)应该是Google的SentencePiece了,因为它符合Tokenizer的一些理想特性,比如语言无关、数据驱动等,并且由于它是C++写的,所以Tokenize(分词)的速度很快,非常适合追求效率的场景。然而,它也有一些明显的缺点,比如训练速度慢(BPE算法)、占用内存大等,同时也正因为它是C++写的,对于多数用户来说它就是黑箱,也不方便研究和二次开发。
事实上,Tokenizer的训练就相当于以往的“新词发现”,而笔者之前也写过中文分词和最小熵系列文章,对新词发现也有一定的积累,所以很早之前就有自己写一版Tokenizer的想法。这几天总算腾出了时间初步完成了这件事情,东施效颦SentencePiece,命名为“BytePiece”。
14
Jun
通向概率分布之路:盘点Softmax及其替代品
By 苏剑林 | 2024-06-14 | 36689位读者 | 引用不论是在基础的分类任务中,还是如今无处不在的注意力机制中,概率分布的构建都是一个关键步骤。具体来说,就是将一个$n$维的任意向量,转换为一个$n$元的离散型概率分布。众所周知,这个问题的标准答案是Softmax,它是指数归一化的形式,相对来说比较简单直观,同时也伴有很多优良性质,从而成为大部分场景下的“标配”。
尽管如此,Softmax在某些场景下也有一些不如人意之处,比如不够稀疏、无法绝对等于零等,因此很多替代品也应运而生。在这篇文章中,我们将简单总结一下Softmax的相关性质,并盘点和对比一下它的部分替代方案。
Softmax回顾
首先引入一些通用记号:$\boldsymbol{x} = (x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$是需要转为概率分布的$n$维向量,它的分量可正可负,也没有限定的上下界。$\Delta^{n-1}$定义为全体$n$元离散概率分布的集合,即
\begin{equation}\Delta^{n-1} = \left\{\boldsymbol{p}=(p_1,p_2,\cdots,p_n)\left|\, p_1,p_2,\cdots,p_n\geq 0,\sum_{i=1}^n p_i = 1\right.\right\}\end{equation}
之所以标注$n-1$而不是$n$,是因为约束$\sum\limits_{i=1}^n p_i = 1$定义了$n$维空间中的一个$n-1$维子平面,再加上$p_i\geq 0$的约束,$(p_1,p_2,\cdots,p_n)$的集合就只是该平面的一个子集,即实际维度只有$n-1$。
30
Oct
低秩近似之路(四):ID
By 苏剑林 | 2024-10-30 | 23140位读者 | 引用这篇文章的主角是ID(Interpolative Decomposition),中文可以称之为“插值分解”,它同样可以理解为是一种具有特定结构的低秩分解,其中的一侧是该矩阵的若干列(当然如果你偏好于行,那么选择行也没什么问题),换句话说,ID试图从一个矩阵中找出若干关键列作为“骨架”(通常也称作“草图”)来逼近原始矩阵。
可能很多读者都未曾听说过ID,即便维基百科也只有几句语焉不详的介绍(链接),但事实上,ID跟SVD一样早已内置在SciPy之中(参考scipy.linalg.interpolative),这侧面印证了ID的实用价值。
基本定义
前三篇文章我们分别介绍了伪逆、SVD、CR近似,它们都可以视为寻找特定结构的低秩近似:
\begin{equation}\mathop{\text{argmin}}_{\text{rank}(\tilde{\boldsymbol{M}})\leq r}\Vert \tilde{\boldsymbol{M}} - \boldsymbol{M}\Vert_F^2\end{equation}
4
Apr
数值方法解方程之终极算法
By 苏剑林 | 2010-04-04 | 49335位读者 | 引用呵呵,做了一回标题党,可能说得夸张了一点。说是“终极算法”,主要是因为它可以任意提高精度、而且几乎可以应付任何非线性方程(至少理论上是这样),提高精度是已知的迭代式上添加一些项,而不是完全改变迭代式的形式,当然在提高精度的同时,计算量也会随之增大。其理论基础依旧是泰勒级数。
我们考虑方程$x=f(y)$,已知y求x是很容易的,但是已知x求y并不容易。我们考虑把y在$(x_0,y_0)$处展开成x的的泰勒级数。关键是求出y的n阶导数$\frac{d^n y}{dx^n}$。我们记$f^{(n)}(y)=\frac{d^n x}{dy^n}$,并且有
$$\frac{dy}{dx}=\frac{1}{(\frac{dx}{dy})}=f'(y)^{-1}$$

最近评论