






25
Mar
一本对称闯物理:相对论力学(二)
By 苏剑林 | 2014-03-25 | 19195位读者 | 引用从这个系列的第一篇文章到本文,已经隔了好多天。其实本文的内容是跟第一篇的内容同时完成的,为什么这么久才更新呢?原因有二,其一是随着春天的到来人也开始懒起来了,颓废呀~;其二,我在思考着规范变换的问题。按照朗道《场论》的逻辑,发展完质点力学理论后,下一步就是发展场论,诸如电磁场、引力场等。但是场论中有个让我比较困惑的东西,即场论存在着“规范不变性”。按照一般观点,我们是将规范不变性看作是电磁场方程的一个结果,即推导出电磁场的方程后,“发现”它具有规范不变性。但是如果用本文的方法,即假定场有这种对称性,然后就可以构建出场方程了。可是,为什么场存在着规范不变性,我还未能思考清楚。据我阅读到的资料来看,这个不变性似乎跟广义不变性有关(电磁场也是,这似乎说明即使在平直时空的电磁场理论中也暗示了广义不变性?)。还有,似乎这个不变性需要在量子场论中才能得到比较满意的解释,可是这样的话,就离我还很远了。
好吧,我们还是先回到相对论力学的推导中。
“无”中生有
上一篇文章我们已经构建了相对论力学的无穷小生成元,并进行了延拓。我已经说过,仅需要无穷小的变换形式,就可以构建出完成的相对论力学定律出来(当然这需要一些比较“显然”的假设)。这是个几乎从“无”到有的过程,也是本文标题的含义所在。另一方面,这种从局部到整体的可能性,也给我们带来一些启示:假如方法是普适的,那么可以由此构造出我们需要的物理定律来,包括电磁场、引力场方程等。(当然,我离这个目标还有点远。)
23
Dec
鬼斧神工:求n维球的体积
By 苏剑林 | 2014-12-23 | 118912位读者 | 引用今天早上同学问了我有关伽马函数和$n$维空间的球体积之间的关系,我记得我以前想要研究,但是并没有落实。既然她提问了,那么就完成这未完成的计划吧。
标准思路
简单来说,$n$维球体积就是如下$n$重积分
$$V_n(r)=\int_{x_1^2+x_2^2+\dots+x_n^2\leq r^2}dx_1 dx_2\dots dx_n$$
用更加几何的思路,我们通过一组平行面($n-1$维的平行面)分割,使得$n$维球分解为一系列近似小柱体,因此,可以得到递推公式
$$V_n (r)=\int_{-r}^r V_{n-1} \left(\sqrt{r^2-t^2}\right)dt$$
设$t=r\sin\theta_1$,就有
$$V_n (r)=r\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} V_{n-1} \left(r\cos\theta_1\right)\cos\theta_1 d\theta_1$$
6
Jun
闲聊:神经网络与深度学习
By 苏剑林 | 2015-06-06 | 77227位读者 | 引用
神经网络
在所有机器学习模型之中,也许最有趣、最深刻的便是神经网络模型了。笔者也想献丑一番,说一次神经网络。当然,本文并不打算从头开始介绍神经网络,只是谈谈我对神经网络的个人理解。如果希望进一步了解神经网络与深度学习的朋友,请移步阅读下面的教程:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
http://blog.csdn.net/zouxy09/article/details/8775360
机器分类
这里以分类工作为例,数据挖掘或机器学习中,有很多分类的问题,比如讲一句话的情况进行分类,粗略点可以分类为“积极”或“消极”,精细点分为开心、生气、忧伤等;另外一个典型的分类问题是手写数字识别,也就是将图片分为10类(0,1,2,3,4,5,6,7,8,9)。因此,也产生了很多分类的模型。
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 651764位读者 | 引用
6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 174820位读者 | 引用暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
2
Apr
【不可思议的Word2Vec】 1.数学原理
By 苏剑林 | 2017-04-02 | 60693位读者 | 引用对于了解深度学习、自然语言处理NLP的读者来说,Word2Vec可以说是家喻户晓的工具,尽管不是每一个人都用到了它,但应该大家都会听说过它——Google出品的高效率的获取词向量的工具。
Word2Vec不可思议?
大多数人都是将Word2Vec作为词向量的等价名词,也就是说,纯粹作为一个用来获取词向量的工具,关心模型本身的读者并不多。可能是因为模型过于简化了,所以大家觉得这样简化的模型肯定很不准确,所以没法用,但它的副产品词向量的质量反而还不错。没错,如果是作为语言模型来说,Word2Vec实在是太粗糙了。
但是,为什么要将它作为语言模型来看呢?抛开语言模型的思维约束,只看模型本身,我们就会发现,Word2Vec的两个模型 —— CBOW和Skip-Gram —— 实际上大有用途,它们从不同角度来描述了周围词与当前词的关系,而很多基本的NLP任务,都是建立在这个关系之上,如关键词抽取、逻辑推理等。这几篇文章就是希望能够抛砖引玉,通过介绍Word2Vec模型本身,以及几个看上去“不可思议”的用法,来提供一些研究此类问题的新思路。
24
Apr
最小熵原理(二):“当机立断”之词库构建
By 苏剑林 | 2018-04-24 | 90101位读者 | 引用在本文,我们介绍“套路宝典”第一式——“当机立断”:1、导出平均字信息熵的概念,然后基于最小熵原理推导出互信息公式;2、并且完成词库的无监督构建、给出一元分词模型的信息熵诠释,从而展示有关生成套路、识别套路的基本方法和技巧。
这既是最小熵原理的第一个使用案例,也是整个“套路宝典”的总纲。
你练或者不练,套路就在那里,不增不减。
为什么需要词语
从上一篇文章可以看到,假设我们根本不懂中文,那么我们一开始会将中文看成是一系列“字”随机组合的字符串,但是慢慢地我们会发现上下文是有联系的,它并不是“字”的随机组合,它应该是“套路”的随机组合。于是为了减轻我们的记忆成本,我们会去挖掘一些语言的“套路”。第一个“套路”,是相邻的字之间的组合定式,这些组合定式,也就是我们理解的“词”。
平均字信息熵
假如有一批语料,我们将它分好词,以词作为中文的单位,那么每个词的信息量是$-\log p_w$,因此我们就可以计算记忆这批语料所要花费的时间为
$$-\sum_{w\in \text{语料}}\log p_w\tag{2.1}$$
这里$w\in \text{语料}$是对语料逐词求和,不用去重。如果不分词,按照字来理解,那么需要的时间为
$$-\sum_{c\in \text{语料}}\log p_c\tag{2.2}$$
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 361422位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
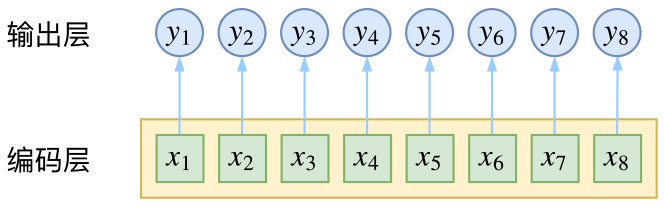
逐帧softmax并没有直接考虑输出的上下文关联

最近评论