







24
Nov
力的无穷分解与格林函数法
By 苏剑林 | 2014-11-24 | 37273位读者 | 引用我小时候一直有个疑问:
直升机上的螺旋桨能不能用来挡雨?
一般的螺旋桨是若干个“条状”物通过旋转对称而形成的,也就是说,它并非一个面,按常理来说,它是没办法用来挡雨的。但是,如果在高速旋转的情况下,甚至假设旋转速度可以任意大,那么我们任意时刻都没有办法穿过它了,这种情况下,它似乎与一个实在的面无异?
力的无穷分解
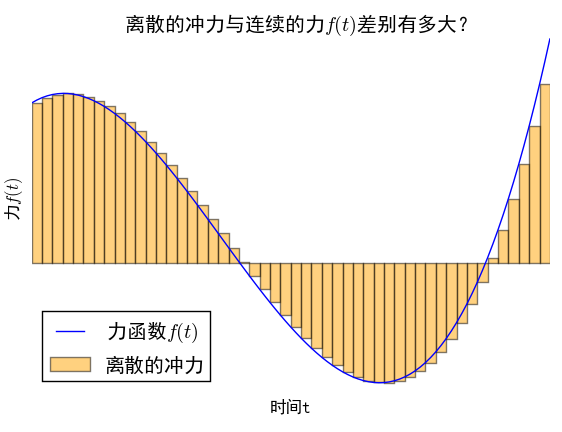
力的离散化
而让人惊喜的是,在通常的物理系统中,将力分段为无数个小区间内的恒力的做法,能够导致正确的答案,而且,这恰好是线性常微分方程的格林函数法。下面我们来分析这一做法。
26
Aug
fashion-mnist的gan玩具
By 苏剑林 | 2017-08-26 | 60315位读者 | 引用
fashion_mnist_demo
mnist的手写数字识别数据集一直是各种机器学习算法的试金石之一,最近有个新的数据集要向它叫板,称为fashion-mnist,内容是衣服鞋帽等分类。为了便于用户往fashion-mnist迁移,作者把数据集做成了几乎跟mnist手写数字识别数据集一模一样——同样数量、尺寸的图片,同样是10分类,甚至连数据打包和命名都跟mnist一样。看来fashion mnist为了取代mnist,也是拼了,下足了功夫,一切都做得一模一样,最大限度降低了使用成本~这叫板的心很坚定呀。
叫板的原因很简单——很多人吐槽,如果一个算法在mnist没用,那就一定没用了,但如果一个算法在mnist上有效,那它也不见得在真实问题中有效~也就是说,这个数据集太简单,没啥代表性。
fashion-mnist的github:https://github.com/zalandoresearch/fashion-mnist/
ODE的坐标变换
熟悉理论力学的读者应该能够领略到变分法在变换坐标系中的作用。比如,如果要将下面的平面二体问题方程
$$\left\{\begin{aligned}\frac{d^2 x}{dt^t}=\frac{-\mu x}{(x^2+y^2)^{3/2}}\\
\frac{d^2 y}{dt^t}=\frac{-\mu y}{(x^2+y^2)^{3/2}}\end{aligned}\right.\tag{1}$$
变换到极坐标系下,如果直接代入计算,将会是一道十分繁琐的计算题。但是,我们知道,上述方程只不过是作用量
$$S=\int \left[\frac{1}{2}\left(\dot{x}^2+\dot{y}^2\right)+\frac{\mu}{\sqrt{x^2+y^2}}\right]dt\tag{2}$$
变分之后的拉格朗日方程,那么我们就可以直接对作用量进行坐标变换。而由于作用量一般只涉及到了一阶导数,因此作用量的变换一般来说比较简单。比如,很容易写出,$(2)$在极坐标下的形式为
$$S=\int \left[\frac{1}{2}\left(\dot{r}^2+r^2\dot{\theta}^2\right)+\frac{\mu}{r}\right]dt\tag{3}$$
对$(3)$进行变分,得到的拉格朗日方程为
$$\left\{\begin{aligned}&\ddot{r}=r\dot{\theta}^2-\frac{\mu}{r^2}\\
&\frac{d}{dt}\left(r^2\dot{\theta}\right)=0\end{aligned}\right.\tag{4}$$
就这样完成了坐标系的变换。如果想直接代入$(1)$暴力计算,那么请参考《方程与宇宙》:二体问题的来来去去(一)
13
Jan
当概率遇上复变:从二项分布到泊松分布
By 苏剑林 | 2015-01-13 | 25320位读者 | 引用泊松分布,适合于描述单位时间内随机事件发生的次数的概率分布,如某一服务设施在一定时间内受到的服务请求的次数、汽车站台的候客人数等。[维基百科]泊松分布也可以作为小概率的二项分布的近似,其推导过程在一般的概率论教材都会讲到。可是一般教材上给出的证明并不是那么让人赏心悦目,如《概率论与数理统计教程》(第二版,茆诗松等编)的第98页就给出的证明过程。那么,哪个证明过程才更让人点赞呢?我认为是利用母函数的证明。
二项分布的母函数为
$$\begin{equation}(q+px)^n,\quad q=1-p\end{equation}$$
17
Mar
你所没有思考过的平行线问题
By 苏剑林 | 2015-03-17 | 36355位读者 | 引用
欧几里得
本文的主题是平行线,了解数学的朋友可能会想我会写有关非欧几何的内容。但这次不是,本文的内容纯粹是我们从小就开始学习的欧氏几何,基于“欧几里得第五公设”(又称平行公设)。但即便是从小就学习的欧氏几何中的平行线,也许里边的很多问题我们都没有思考清楚。因为平行是几何中非常基本的情形,因此,在讨论这种基本命题的时候,相当容易会出现循环论证、甚至本末倒置的情况。
我们从初中开始就被灌输“同位角相等,两直线平行”、“内错角相等,两直线平行”之类的平行线判断法则,当然,还少不了的是“过直线外一点只能作一条直线与已知直线平行”。但是,这些内容之中,有多少是基本的公理,有多少是可以证明的,该如何证明,我想很多人都理解不清楚,我自己也没有一个很好的答案。那些在初中教授平行线的老师们,估计也没多少个能够把它说清楚的。后来我发现,我居然不会证明“同位角相等,两直线平行”,“欧几里得第五公设”好像并没有告诉我们这个判定法则呀。于是,我翻看了一下初中的数学教科书,发现原来当初“同位角相等,两直线平行”这一判定法则是不加证明地让我们接受的,无怪乎我怎么也想不到关于这一法则的简单的证明...
于是,我想写这篇文章,为大家理解平行线的整个逻辑提供一点参考。
16
Apr
采样定理:有限个点构建出整个函数
By 苏剑林 | 2015-04-16 | 31571位读者 | 引用假设我们在听一首歌,那么听完这首歌之后,我们实际上在做这样的一个过程:耳朵接受了一段时间内的声波刺激,从而引起了大脑活动的变化。而这首歌,也就是这段时间内的声波,可以用时间$t$的函数$f(t)$描述,这个函数的区间是有限的,比如$t\in[0,T]$。接着假设另外一个场景——我们要用电脑录下我们唱的歌。这又是怎样一个过程呢?要注意电脑的信号是离散化的,而声波是连续的,因此,电脑要把歌曲记录下来,只能对信号进行采样记录。原则上来说,采集的点越多,就能够越逼真地还原我们的歌声。可是有一个问题,采集多少点才足够呢?在信息论中,一个著名的“采样定理”(又称香农采样定理,奈奎斯特采样定理)告诉我们:只需要采集有限个样本点,就能够完整地还原我们的输入信号来!
采集有限个点就能够还原一个连续的函数?这是怎么做到的?下面我们来解释这个定理。
任意给定一个函数,一般来说我们都可以将它做傅里叶变换:
$$F(\omega)=\int_{-\infty}^{+\infty} f(t)e^{i\omega t}dt\tag{1}$$
虽然我们的积分限写了正负无穷,但是由于$f(t)$是有限区间内的函数,所以上述积分区间实际上是有限的。
26
Apr
高斯型积分的微扰展开(三)
By 苏剑林 | 2015-04-26 | 26431位读者 | 引用换一个小参数
比较《高斯型积分的微扰展开(一)》和《高斯型积分的微扰展开(二)》两篇文章,我们可以得出关于积分
$$\int_{-\infty}^{+\infty} e^{-ax^2-\varepsilon x^4} dx\tag{1}$$
的两个结论:第一,我们发现类似$(4)$式的近似结果具有良好的性质,对任意的$\varepsilon$都能得到一个相对靠谱的近似;第二,我们发现在指数中逐阶展开,得到的级数效果会比直接展开为幂级数的效果要好。那么,两者能不能结合起来呢?
我们将$(4)$式改写成
$$\int_{-\infty}^{+\infty} e^{-ax^2-\varepsilon x^4} dx\approx\sqrt{\frac{2\pi}{a+\sqrt{a^2+6 \varepsilon}}}=\sqrt{\frac{\pi}{a+\frac{1}{2}\left(\sqrt{a^2+6 \varepsilon}-a\right)}}\tag{6}$$

最近评论