






27
Mar
海伦公式的一个别致的物理推导
By 苏剑林 | 2015-03-27 | 51454位读者 | 引用海伦公式是已知三角形三边的长度$a,b,c$来求面积$S$的公式,是一个相当漂亮的公式,它不算复杂,同时它关于$a,b,c$是对称的,充分体现了三边的同等地位。可是,这样具有对称美的公式推导,往往要经过一个不对称的过程,比如维基百科上的证明,这未免有点美中不足。本文的目的,就是想为此补充一个对称的推导。本文题目为“物理推导”,关键在于“推导”而不是“证明”,同时这里的“物理”并非是通过物理类比而来,而是推导的思想和方法很具有“物理味道”。
$$\sqrt{p(p-a)(p-b)(p-c)}$$
在推导开始之前,笔者给出一个评论:海伦公式似乎是由三边长求三角形面积的所有可能的公式之中最简单的一个。
27
Feb
从Knotsevich在黑板上写的级数题目谈起
By 苏剑林 | 2015-02-27 | 29581位读者 | 引用
13
Aug
exp(1/2 t^2+xt)级数展开的图解技术
By 苏剑林 | 2015-08-13 | 31280位读者 | 引用本文要研究的是关于$t$的函数
$$\exp\left(\frac{1}{2}t^2+xt\right)$$
在$t=0$处的泰勒展开式。显然,它并不困难,手算或者软件都可以做出来,答案是:
$$1+x t+\frac{1}{2} \left(x^2+1\right) t^2+\frac{1}{6}\left(x^3+3 x\right) t^3 +\frac{1}{24} \left(x^4+6 x^2+3\right) t^4 + \dots$$
不过,本文将会给出笔者构造的该级数的一个图解方法。通过这个图解方法比较比较直观而方便地手算出展开式的前面一些项。后面我们再来谈谈这种图解技术的起源以及进一步的应用。
级数的图解方法:说明
首先,很明显要写出这个级数,关键是写出展开式的每一项,也就是要求出
$$f_k (x) = \left.\frac{d^k}{dt^k}\exp\left(\frac{1}{2}t^2+xt\right)\right|_{t=0}$$
$f_k (x)$是一个关于$x$的$k$次整系数多项式,$k$是展开式的阶,也是求导的阶数。
这里,我们用一个“点”表示一个$x$,用“两点之间的一条直线”表示“相乘”,那么,$x^2$就可以表示成

x^2项
5
Oct
2015诺贝尔医学奖:中国人在内
By 苏剑林 | 2015-10-05 | 24065位读者 | 引用
3
Aug
运动相机测试:家乡的星空
By 苏剑林 | 2016-08-03 | 38307位读者 | 引用记得很早之前就想尝试一下拍星空,无奈一直都没有设备。以前只知道单反可以拍星空,因此,一直以来的想法就是有钱了就去买台单反。因为各种原因一拖再拖,最后慢慢觉得,对于我这种三分钟热度的人来说,单反的意义还真的不是很大。
这两年,在小米的鼓吹下,小蚁运动相机在国内算是慢慢掀起了一股运动相机潮。这种相机的特点是小巧、灵活,价格也不贵(相比单反)。灵活不仅仅是说它便于携带,而且还是功能上的灵活,比如一代小蚁还支持编程拍摄!(写程序控制快门、ISO、拍摄间隔,并实现定时拍摄等)这样当然很快就吸引了我,在小蚁2代众筹之时,我也咬咬牙,入了一台。
前两天回到家,刚好晴夜,马上就试了一下拍星空的效果。下面是在我家楼顶拍的,用ISO400曝光30秒的效果:

家乡的星空
12
Apr
【备忘】用树莓派3做无线路由器
By 苏剑林 | 2016-04-12 | 65245位读者 | 引用3月初发布的树莓派3自带了WiFi和蓝牙,再加上它本来就有一个网口,因此俨然就是一台无线路由器了。我也忍不住入手了一个,打算用来做路由器和NAS。树莓派做路由器的教程已经有很多了,当然,基本都是基于树莓派2的,3之前的版本都没有自带WiFi,因此需要自己配无线网卡,而3自带了无线网卡,配置就方便多了。参考了两篇外文教程,成功配置,在这里记录一下。
参考教程:
https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
https://gist.github.com/Lewiscowles1986/fecd4de0b45b2029c390#file-rpi3-ap-setup-sh
18
Jun
OCR技术浅探:3. 特征提取(2)
By 苏剑林 | 2016-06-18 | 38864位读者 | 引用
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 56081位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
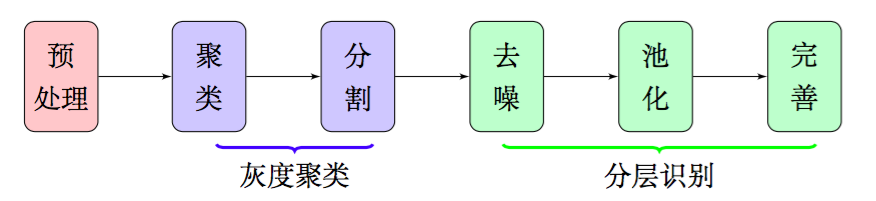
图2:特征提取大概流程

最近评论