






17
May
变分自编码器(七):球面上的VAE(vMF-VAE)
By 苏剑林 | 2021-05-17 | 147423位读者 | 引用在《变分自编码器(五):VAE + BN = 更好的VAE》中,我们讲到了NLP中训练VAE时常见的KL散度消失现象,并且提到了通过BN来使得KL散度项有一个正的下界,从而保证KL散度项不会消失。事实上,早在2018年的时候,就有类似思想的工作就被提出了,它们是通过在VAE中改用新的先验分布和后验分布,来使得KL散度项有一个正的下界。
该思路出现在2018年的两篇相近的论文中,分别是《Hyperspherical Variational Auto-Encoders》和《Spherical Latent Spaces for Stable Variational Autoencoders》,它们都是用定义在超球面的von Mises–Fisher(vMF)分布来构建先后验分布。某种程度上来说,该分布比我们常用的高斯分布还更简单和有趣~
KL散度消失
我们知道,VAE的训练目标是
\begin{equation}\mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)} \Big[\mathbb{E}_{z\sim p(z|x)}\big[-\log q(x|z)\big]+KL\big(p(z|x)\big\Vert q(z)\big)\Big]
\end{equation}
27
Sep
关于维度公式“n > 8.33 log N”的可用性分析
By 苏剑林 | 2021-09-27 | 43266位读者 | 引用在之前的文章《最小熵原理(六):词向量的维度应该怎么选择?》中,我们基于最小熵思想推导出了一个词向量维度公式“$n > 8.33\log N$”,然后在《让人惊叹的Johnson-Lindenstrauss引理:应用篇》中我们进一步指出,该结果与JL引理所给出的$\mathcal{O}(\log N)$是吻合的。
既然理论上看上去很完美,那么自然就有读者发问了:实验结果如何呢?8.33这个系数是最优的吗?本文就对此问题的相关内容做一个简单汇总。
词向量
首先,我们可以直接,当$N$为10万时,$8.33\log N\approx 96$,当$N$为500万时,$8.33\log N\approx 128$。这说明,至少在数量级上,该公式给出的结果是很符合我们实际所用维度的,因为在词向量时代,我们自行训练的词向量维度也就是100维左右。可能有读者会质疑,目前开源的词向量多数是300维的,像BERT的Embedding层都达到了768维,这不是明显偏离了你的结果了?
10
Oct
用狄拉克函数来构造非光滑函数的光滑近似
By 苏剑林 | 2021-10-10 | 81515位读者 | 引用在机器学习中,我们经常会碰到不光滑的函数,但我们的优化方法通常是基于梯度的,这意味着光滑的模型可能更利于优化(梯度是连续的),所以就有了寻找非光滑函数的光滑近似的需求。事实上,本博客已经多次讨论过相关主题,比如《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等,但以往的讨论在方法上并没有什么通用性。
不过,笔者从最近的一篇论文《SAU: Smooth activation function using convolution with approximate identities》学习到了一种比较通用的思路:用狄拉克函数来构造光滑近似。通用到什么程度呢?理论上有可数个间断点的函数都可以用它来构造光滑近似!个人感觉还是非常有意思的。
24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 64969位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
5
Jun
从一个单位向量变换到另一个单位向量的正交矩阵
By 苏剑林 | 2021-06-05 | 46701位读者 | 引用这篇文章我们来讨论一个比较实用的线性代数问题:
给定两个$d$维单位(列)向量$\boldsymbol{a},\boldsymbol{b}$,求一个正交矩阵$\boldsymbol{T}$,使得$\boldsymbol{b}=\boldsymbol{T}\boldsymbol{a}$。
由于两个向量模长相同,所以很显然这样的正交矩阵必然存在,那么,我们怎么把它找出来呢?
二维
不难想象,这本质上就是$\boldsymbol{a},\boldsymbol{b}$构成的二维子平面下的向量变换(比如旋转或者镜面反射)问题,所以我们先考虑$d=2$的情形。
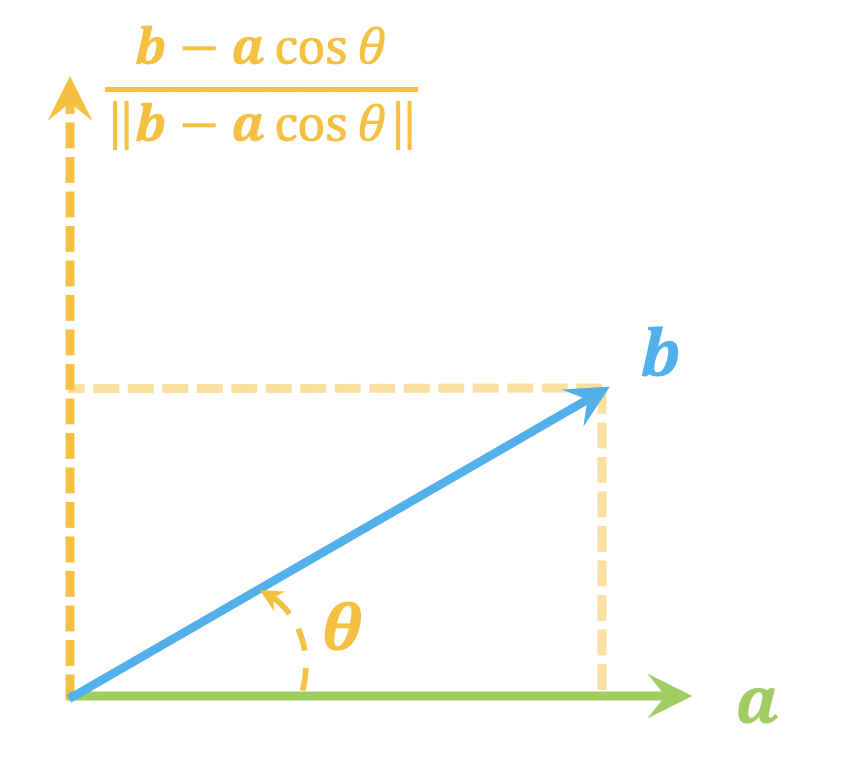
正交分解示意图
31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 83412位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
19
Jul
用开源的人工标注数据来增强RoFormer-Sim
By 苏剑林 | 2021-07-19 | 150111位读者 | 引用大家知道,从SimBERT到SimBERTv2(RoFormer-Sim),我们算是为中文文本相似度任务建立了一个还算不错的基准模型。然而,SimBERT和RoFormer-Sim本质上都只是“弱监督”模型,跟“无监督”类似,我们不能指望纯弱监督的模型能达到完美符合人的认知效果。所以,为了进一步提升RoFormer-Sim的效果,我们尝试了使用开源的一些标注数据来辅助训练。本文就来介绍我们的探索过程。
有的读者可能想:有监督有啥好讲的?不就是直接训练么?说是这么说,但其实并没有那么“显然易得”,还是有些“雷区”的,所以本文也算是一份简单的“扫雷指南”吧。
前情回顾
笔者发现,自从SimBERT发布后,读者问得最多的问题大概是:
为什么“我喜欢北京”跟“我不喜欢北京”相似度这么高?它们不是意思相反吗?
22
Jul
概率视角下的线性模型:逻辑回归有解析解吗?
By 苏剑林 | 2021-07-22 | 83510位读者 | 引用我们知道,线性回归是比较简单的问题,它存在解析解,而它的变体逻辑回归(Logistic Regression)却没有解析解,这不能不说是一个遗憾。因为逻辑回归虽然也叫“回归”,但它实际上是用于分类问题的,而对于很多读者来说分类比回归更加常见。准确来说,我们说逻辑回归没有解析解,说的是“最大似然估计下逻辑回归没有解析解”。那么,这是否意味着,如果我们不用最大似然估计,是否能找到一个可用的解析解呢?
逻辑回归示意图
本文将会从非最大似然的角度,推导逻辑回归的一个解析解,简单的实验表明它效果不逊色于梯度下降求出来的最大似然解。此外,这个解析解还易于推广到单层Softmax多分类模型。

最近评论