






5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 145089位读者 |最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
模型概览 #
整个模型的思路,其实就是之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》所介绍的PET(Pattern-Exploiting Training)的变体,用一个MLM模型来完成所有,示意图如下:
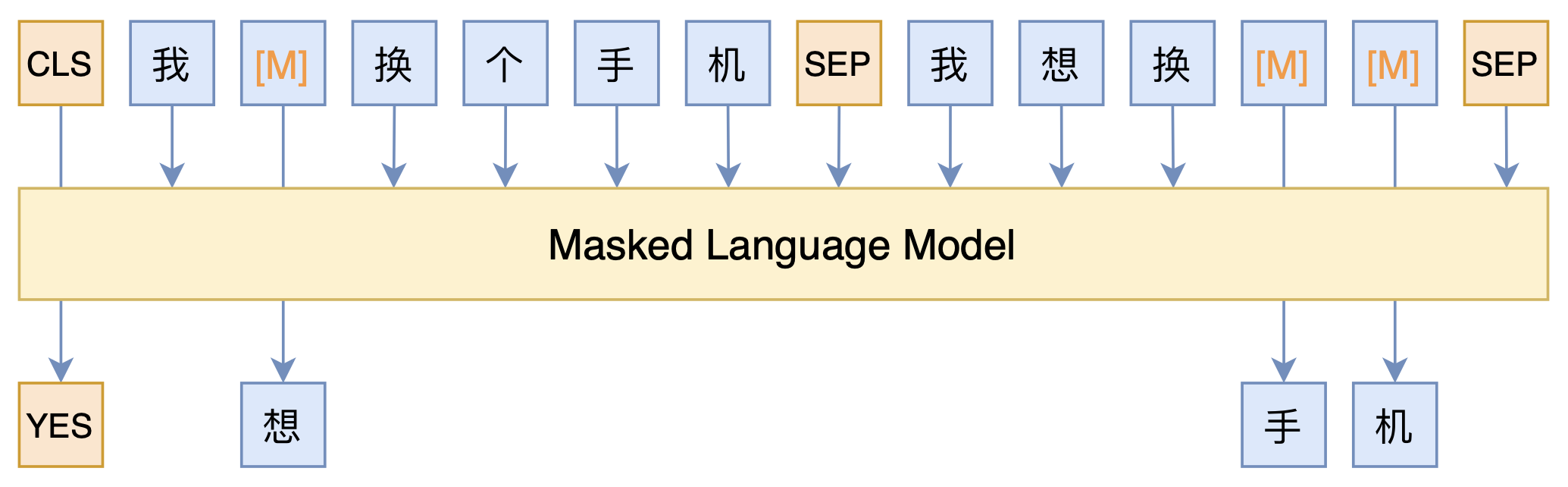
本文模型示意图
可以看到,全模型就只是一个MLM模型。具体来说,我们在词表里边添加了[YES]和[NO]两个标记,用来表示句子之间的相似性,通过[CLS]对应的输出向量来预测句子对的标签([YES]或[NO]),然后构建语料的方式,就是常规的把句子对拼接起来,两个句子随机mask掉一些token,然后在对应的输出位置预测这个token。
这样一来,我们同时做了句子对的分类任务([CLS]的预测结果),也做了MLM的预训练任务(其他被mask掉的token),而且没有标签的样本(比如测试集)也可以扔进去训练,只要不预测[CLS]就行了。于是我们通过MLM模型,把分类、预训练和半监督都结合起来了~
重用BERT #
脱敏数据还可以用BERT吗?当然是可以的,脱敏数据对于BERT来说,其实就是Embedding层不一样而已,其他层还是很有价值的。所以重用BERT主要还是通过预训练重新对齐Embedding层。
在这个过程中,初始化很重要。首先,我们把BERT的Embedding层中的[UNK]、[CLS]、[SEP]等特殊标记拿出来,这部分不变;然后,我们分别统计密文数据和明文数据的字频,明文数据指的是任意的开源通用语料,不一定要密文数据对应的明文数据;接着按照频率简单对齐明文字表和密文字表。这样一来,我们就可以按照明文的字来取出BERT的Embedding层来作为相应的初始化。
简单来说,就是我用最高频的明文字对应的BERT Embedding,来初始化最高频的密文字,依此类推来做一个基本的字表对齐。个人的对比实验表明,这个操作可以明显加快模型的收敛速度。
代码分享 #
说到这里,模型就基本介绍完了,这样的操作我目前使用base版本的bert,在排行榜上的分数是0.866,线下则已经是0.952了(单模型,没做K-fold融合,大家的线上线下差距貌似都蛮大)。这里分享自己的bert4keras实现:
关于明文数据的词频,我已经实现统计好一份,也同步在Github了,大家直接用就好。建议大家训练完100个epoch,在3090上大概要6小时。
对了,如果你想用Large版本的BERT,不建议用哈工大开源的RoBERTa-wwm-ext-large,理由在《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》已经说过了,该版本不知道为啥随机初始化了MLM部分的权重,而我们需要用到MLM权重。需要用Large版本的,推荐用腾讯UER开源的BERT Large。
文本小结 #
也没啥,就是分享了个比赛的简单baseline,顺便水了篇博客而已,希望对大家有所帮助~
转载到请包括本文地址:https://kexue.fm/archives/8213
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Mar. 05, 2021). 《短文本匹配Baseline:脱敏数据使用预训练模型的尝试 》[Blog post]. Retrieved from https://kexue.fm/archives/8213
@online{kexuefm-8213,
title={短文本匹配Baseline:脱敏数据使用预训练模型的尝试},
author={苏剑林},
year={2021},
month={Mar},
url={\url{https://kexue.fm/archives/8213}},
}

March 5th, 2021
> 个人的对比实验表明,这个操作可以明显加快模型的收敛速度。
请问苏老师,这个对比是对比的随机初始化的bert还是加载了以前预训练权重的bert。
对比的是不这样对齐(即随机初始化Embedding层)的bert。
用bert的话,肯定要加载预训练权重的,除了Embedding层之外,剩下的权重也很有用。从零训练bert是一件非常困难的事情,这点比赛语料还不够。
March 5th, 2021
苏师兄太强了!(我是来自华师软院NLP团队的小师弟)
March 5th, 2021
牛逼啊
March 5th, 2021
我试了下在你的代码里,加了
sample_tokends = [i for i in range(0,21128,3)]
keep_tokens = [keep_tokens[i] for i in sample_tokends]
这两行,就是没有使用最高频的预训练词表,替代的是均匀分散开,对这两种收敛速度没有明显区别,一会儿试试随机选的结果。
验证了,也没有明显区别,效果应该是其它层的参数,怎么选词对齐不太重要。。
你这不是也是按词频对齐的吗?只不过筛掉了部分词而已。
我这里的收敛速度会有明显差别,尤其是如果你不用预训练,concat后做Dense二分类的场景。
不是这个意思,我说是采用预训练的参数,但是对齐没用最高频部分,就随便安插进去。还有你开源的代码似乎没有启动MLM的预训练任务,
train_generator = data_generator(train_data, batch_size)
valid_generator = data_generator(valid_data, batch_size)
test_generator = data_generator(test_data, batch_size)
全都是False,相当于只用PET硬怼了相似性。
有预训练的,forfit()里边就是True了。可能上了PET之后差别不大,我早期直接用concat+Dense二分类的时候,差别很大的,后来上PET我就没改了。
好吧,搞错了。这个封装有点奇怪,不好意思。
March 5th, 2021
苏神,请教几个问题啊~
问题1
由于训练数据中混合了测试数据,因此在计算损失函数的时候,需要过滤非预测部分,在代码中
y_mask = K.cast(K.greater(y_true, 0.5), K.floatx())
这里y_true是不是就是5(YES)跟6(NO)啊,所以这里的0.5取个其他值(只需小于5,如1,2,3)是不是也是可以的呢?
问题2
损失函数中,除以mask的一阶范数是为了消除什么影响呢?
loss = K.sum(loss * y_mask) / K.sum(y_mask)
y_true其实就是传入的batch_output_ids,它是MLM模型的目标,y_mask=K.cast(K.greater(y_true, 0.5), K.floatx())得到一个0/1矩阵,标记哪些位置的token是被随机替换过的,这部分token需要用模型预测,剩下的0表示没有被随机替换掉的,因此不需要预测。loss=K.sum(loss * y_mask) / K.sum(y_mask)就是通过y_mask来排除掉不需要预测的部分(85%的token都不需要预测,只有15%的需要预测)。
其实各种mask是nlp的常规操作吧,经常自己写模型的,以及熟悉bert的mlm训练流程的,应该不难看懂这部分代码。
March 6th, 2021
苏神,请问116行的segment_id为什么只有0,不是0,1呢?不是两句的SEP吗?
这个基本不会有影响,你可以自行切换试试。
March 6th, 2021
你好,请问最终loss大概可以降到多少
0.5以下
March 11th, 2021
我比較好奇的是,這種"脫敏"有意義嗎?如果每個字都變成數字ID,但字與ID基本上是一對一對應的,那麼甚至不需要用到甚麼高級的解密技巧,只要用統計詞頻就可以把ID 還原成單字了。甚至我覺得還可以訓練一個 mapping 層,直接讓ID 轉回單字,再把單字輸入 bert 預測結果,這樣完全不需要對齊,也不需要動到bert,唯一訓練到的是 mapping 層,訓練完後,還可以順便把ID 轉成原始的句子。這樣敏感資料還是可以還原,所以根本也不能算是"脫敏"了。
要注意,我们得不到脱敏后的数据所对应的明文数据,所以单纯根据词频对齐,只是一种粗糙的初始化,并没有精准对齐。
March 14th, 2021
感谢苏神分享,请问MLM权重是指哪一部分?或编那个 hiddendim(比如768)到词表个数的映射全连接层吗?
bert的mlm模型,可以大致表示为encoder + dense1 + layernorm + dense2,其中dense2的kernel是直接重用Embedding层的,这部分没问题,是dense1和layernorm部分的权重不对劲。
March 24th, 2021
dense2是指feed forward network部分的权重?似乎后面也应该跟着一个layernorm?
认真读这段话@苏剑林|comment-15761,看不懂就去读bert源码。
哈哈,错把encoder当multihead attention了,encoder输出到mlm输出部分确实需要看下源码。