






1
Jan
SPACES:“抽取-生成”式长文本摘要(法研杯总结)
By 苏剑林 | 2021-01-01 | 348403位读者 |“法研杯”算是近年来比较知名的NLP赛事之一,今年是第三届,包含四个赛道,其中有一个“司法摘要”赛道引起了我们的兴趣。经过了解,这是面向法律领域裁判文书的长文本摘要生成,这应该是国内第一个公开的长文本生成任务和数据集。过去一年多以来,我们在文本生成方面都有持续的投入和探索,所以决定选择该赛道作为检验我们研究成果的“试金石”。很幸运,我们最终以微弱的优势获得了该赛道的第一名。在此,我们对我们的比赛模型做一个总结和分享。

比赛榜单截图
在该比赛中,我们跳出了纯粹炼丹的过程,通过新型的Copy机制、Sparse Softmax等颇具通用性的新方法提升了模型的性能。整体而言,我们的模型比较简洁有效,而且可以做到端到端运行。窃以为我们的结果对工程和研究都有一定的参考价值。
赛题分析 #
观察、分析任务数据是NLP的第一步,也是相当重要的一步,它关系到我们后面的模型选择,也关系到后面的提升方向。
统计信息 #
这次比赛官方共提供了9484个标注样本,以“(原文, 摘要)”这样的数据对形式出现,原训练数据还附带了其他的一些辅助标注信息,但为了模型的通用性,我们没有用这些辅助信息,所以我们的模型原则上适用于所有单条样本格式为“(原文, 摘要)”的监督式摘要任务。
下面是训练数据的一些统计信息:
1、总量:9484;
2、输入:平均字数 2568,字数标准差 1122,最大字数 13064,最小数字 866;
3、输出:平均字数 283,字数标准差 36,最大字数 474,最小数字 66;
4、指标:以词为单位的加权Rouge。
因此,简单来说这大概就是一个“输入3000字、输出300字”的文本生成任务,其难度在于两千多的平均长度远远超出了我们平时处理的文本长度。9484是全部发布的数据集,网上目前可以下载到的第一阶段的数据是4047条,其实也可以直接跑出还不错的效果,整个模型对数据量的依赖不是特别严重,读者不用太纠结数据量的问题。
样本预览 #

法研杯2020司法摘要赛道样本演示
上图演示的是训练集的某个样本,其中上面是输入(裁判文书原文),下面是输出(人工标注的摘要),其中绿色部分标注的是两者的“最长公共子序列”。可以看到,输出跟输入是高度重合的。
建模思路 #
综合上述数据特性,我们不难想到应该采取“抽取+生成”相结合的方式进行摘要,并配合一些新方法来保证摘要的忠实程度与提升最终的效果。最终的模型笔者我们命名为SPACES:
S:Sparse Softmax(新设计的Softmax替代品);
P:Pretrained Language Model(预训练模型);
A:Abstractive(抽象式,即生成式);
C:Copy Mechanism(新设计的Copy机制);
E:Extractive(抽取式);
S:Special Words(将特殊词添加到预训练模型)。
很显然,这是笔者“煞费苦心”强行拼凑的(捂脸),对应于本博客的域名之一“spaces.ac.cn”。不过,上述缩写确实已经把我们的模型的主要技术点都罗列出来了。下面我们将仔细介绍SPACES为何物。
抽取模型 #
这一节我们将对抽取模型部分做一个简要介绍。抽取模型的思路是先通过规则将原始的生成式语料转化为序列标注式语料,然后用笔者常用的DGCNN模型来建模。
语料转换 #
首先,我们需要记住的是,抽取模型只是过程而不是结果,我们还要把抽取的结果送入到Seq2Seq模型优化。因此,抽取模型的原则是“求全”,即尽量把最终摘要所需要的信息覆盖到。为此,我们按照如下规则将原始训练语料转换为抽取式语料:
1、自行构建分句函数,使得句子的颗粒度更细;
2、人工摘要的每个句子,都在原文中匹配与之相似度最高的那个句子(可以重复匹配);
3、将所有匹配到的原文句子作为抽取句子标签;
4、删掉部分匹配出来的句子,使得与人工摘要的Rouge得分最高。
注意,我们在最终模型中删掉了第4点,而它本来是我们最初版模型的默认选择。事实上,加上第4点有利于提高抽取模型的指标,但是综合生成模型后最终得分反而下降了。这不难理解,生成模型本来有删改功能,而且比抽取模型做得更好;如果抽取模型意外地把本应该抽取的关键句子删掉了的话,那么生成模型就很难把它恢复出来了,从而导致性能下降。也就是说,第4点不满足抽取模型的“求全”原则,我们应该把删改工作教程生成模型来做,不应该放到抽取模型中。
指标问题 #
上述转换流程涉及到一个“相似度”的选择,根据前面的介绍,本次比赛选择“以词为单位的加权Rouge”作为评测指标,因此我们可以直接选择这个加权Rouge作为相似度指标。事实上,我们一开始确实是这样做的,但是后来在调试的时候发现,这样并不是一个好的选择,我们最终选择的是“以字为单位的加权Rouge”。
这两者有什么区别呢?对于官方以词为单位来算评测指标的做法,我们也不难理解其目的,就是为了使得专有名词能够完全匹配上,比如本来是“中国人民共和国未成年人保护法”,你预测成了“中国人民共和国文物保护法”,如果以字为单位的话,最长公共子序列为“中国人民共和国...保护法”,至少还是算对了大部分,但是如果以词为单位的话,两者就是不同的词,因此算全错。因此,以词为单位有利于专有名词匹配得更精准。
然而,以词为单位会带来一个严重的副作用,那就是降低了长词的权重。比如“根据 《 中国人民共和国未成年人保护法 》 的 有关 规定”中,核心词“中国人民共和国未成年人保护法”的权重仅为1,剩下的“根据”、“《”、“》”、“的”等我们认为无关紧要的词权重分别都为1,占了大部分,这样一来,模型宁愿去匹配“根据”、“《”、“》”、“的”等词,也不愿意去拟合核心词“中国人民共和国未成年人保护法”了。说白了,以词为单位的话,得分高的摘要未必是有什么关键信息的摘要。
那怎么调和两者呢?事实上,最好的方案应该还是以词为单位,但是算指标的时候,按照字数跟每个词加权,比如“中国人民共和国未成年人保护法”,匹配不上就给0分,匹配对了就给14分(因为有14个字)而不是1分才好。不过,这需要自己来实现Rouge计算函数,有点麻烦,我们最终是直接选择以字为单位来算加权Rouge,这也勉强够用,因为在转换语料的时候,我们知道摘要和原文都是在描述同一件案子,因此基本不会出现“中国人民共和国未成年人保护法”预测成“中国人民共和国文物保护法”的情况。
模型结构 #
回到模型方面,我们使用的是以句为单位的序列标注模型作为抽取模型,句向量部分用“BERT+平均池化”来生成,并固定不变,标注模型主体方面则用DGCNN模型构建。关于DGCNN模型,请参考《基于CNN的阅读理解式问答模型:DGCNN》、《开源一版DGCNN阅读理解问答模型(Keras版)》、《基于DGCNN和概率图的轻量级信息抽取模型》等。
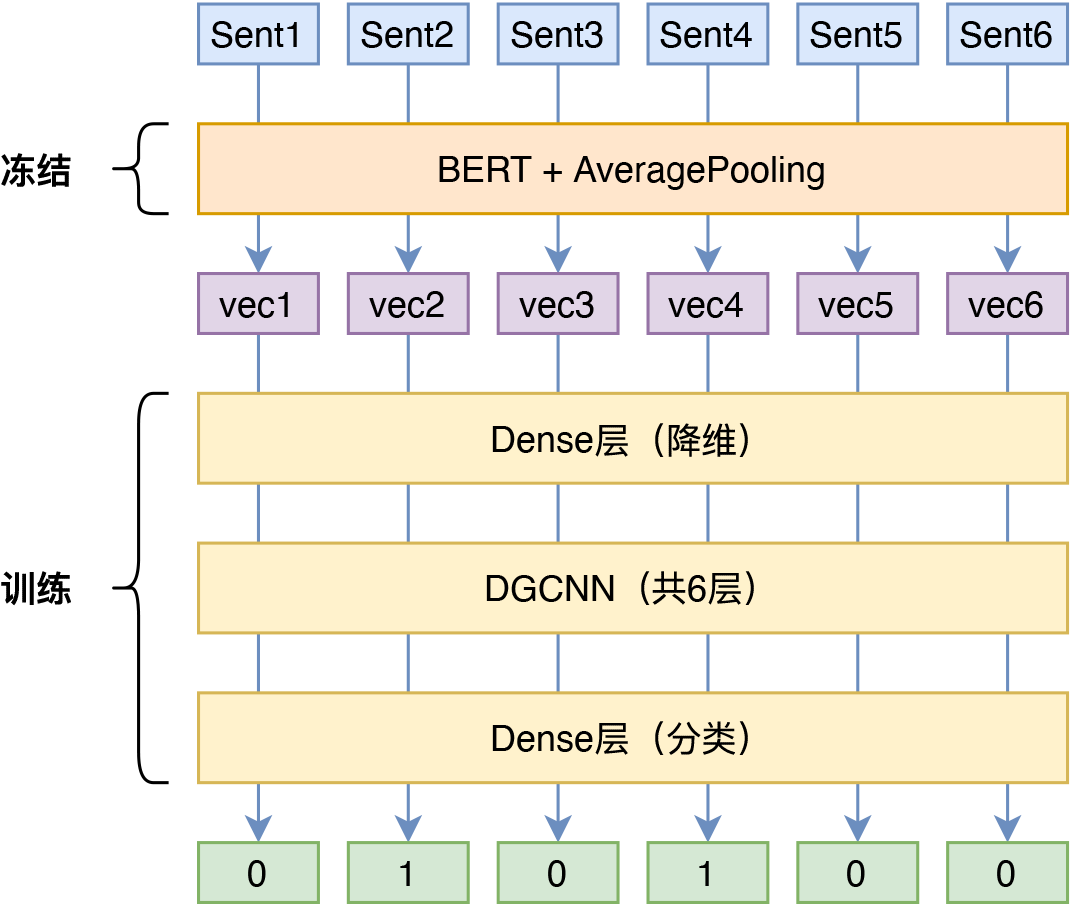
SPACES的抽取模型示意图
值得指出的一个细节是,在训练抽取模型的时候,我们是以0.3为阈值做EarlyStop的,但最终以0.2为阈值构建生成模型的数据,依据还是前面说的抽取模型的原则是要“求全”。
输出数据 #
我们需要将原文作为输入,通过抽取模型输出抽取摘要,然后把抽取摘要作为生成模型的输入,来输出最终摘要。但是,这有一个问题,训练的数据我们都是见过的,但我们真正预测的是未见过的数据,如果直接训练一个抽取模型,然后用该模型抽取训练集的摘要,那么很明显由于都被训练过了,抽取出来的摘要分数肯定会偏高,而新样本的效果则会偏低,造成训练预测的不一致性。
这时候的解决方案就是交叉验证了。具体来说,我们将标注数据分为$n$份,其中$n-1$份训练抽取模型,然后用这个抽取模型预测剩下的那份数据的抽取摘要,如此重复$n$遍,就得到全部数据的抽取摘要,并且尽可能地减少了训练和预测阶段的不一致性。
生成模型 #
生成模型是我们投入主要时间的部分,也是我们的主要贡献点。生成模型就是一个Seq2Seq模型,以抽取模型的输出结果作为输入、人工标注的摘要作为输出进行训练,我们可以理解为是对抽取结果做进一步的“润色”。
模型总览 #
如果用一张图概括我们的生成模型,那么大概如下:
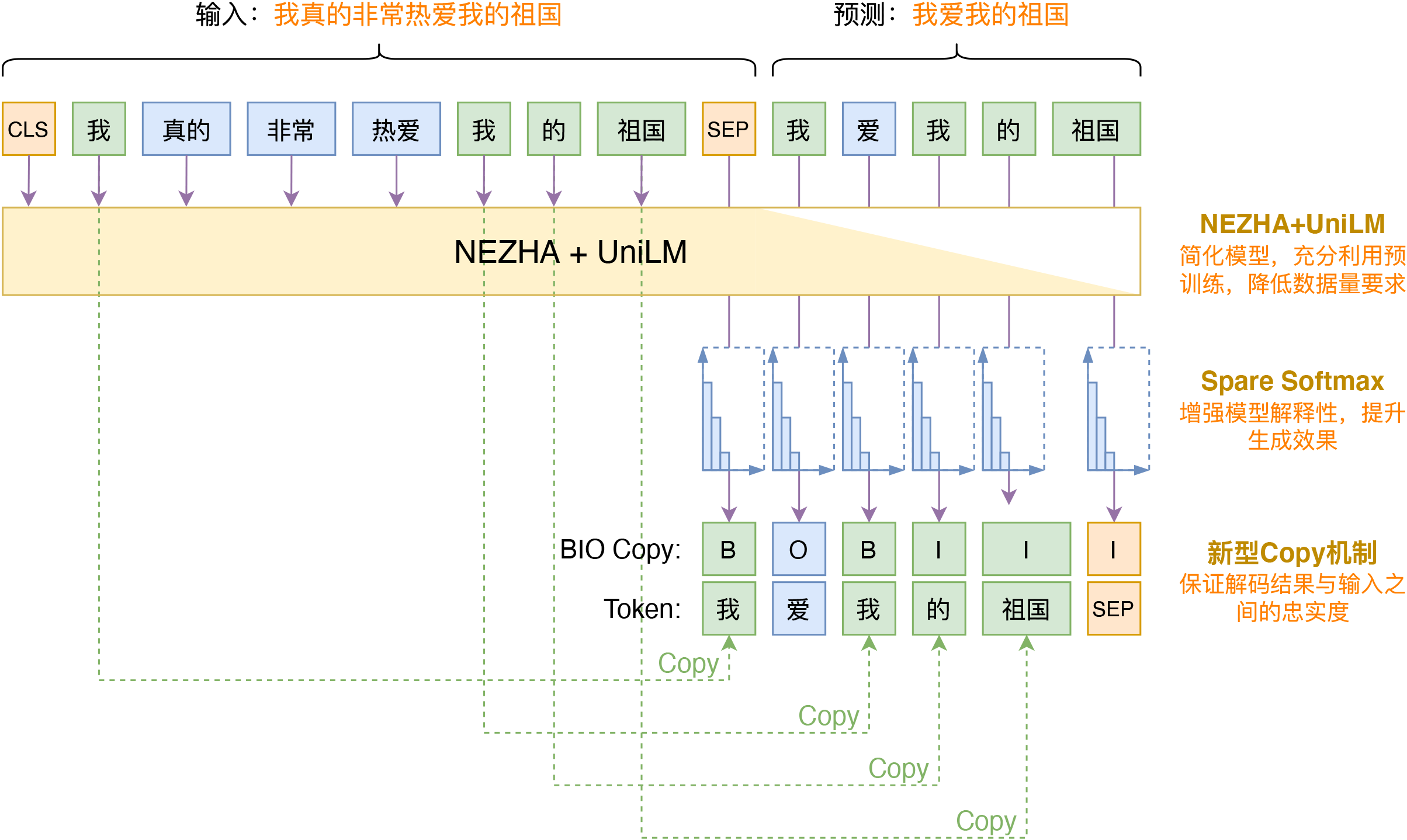
SPACES的生成模型示意图
接下来我们会介绍模型的各个模块。
基础架构 #
Seq2Seq模型依然选择了经典的UniLM(参考《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》),并且考虑到“输入+输出”的总长度基本上都超过512了,所以选择华为的NEZHA模型作为基础模型架构,因为NEZHA使用了相对位置编码,不限长度。
当然,这是当时的选择,现在的话我们至少还有如下两个选择:
1、参考《层次分解位置编码,让BERT可以处理超长文本》中的直接延拓绝对位置编码的做法,使得BERT有能力直接处理更长序列(理论上可达26万),自然也可以用于“BERT+UniLM”中;
2、使用《那个屠榜的T5模型,现在可以在中文上玩玩了》介绍的多国语言版T5模型(mT5),它用的也是相对位置编码,不限长度,但要注意T5用的tokenizer会将全角逗号转为半角逗号,这会导致评测分数下降。
此外,在使用预训练模型方面,我们首创地将部分词语加入到了NEZHA模型中,改变了中文预训练模型以字为单位的通用选择,这使得模型的效果和速度都有一定的提升。这部分结果已经发布在之前的文章《提速不掉点:基于词颗粒度的中文WoBERT》之中,读者可以移步参考。
BIO Copy #
Copy机制在摘要生成模型中并不新鲜,甚至可以说已经成为了生成式摘要的标配了。常规的Copy机制一般就是《Pointer Networks》的做法,但这种做法有两个不足之处:1、每次只能Copy一个token,不能保证Copy一个连续片段(n-gram)出来;2、实现起来比较复杂,不够即插即用。为此,我们构思了一种新型的Copy机制,暂时称为BIO Copy,它实现起来非常简单,而且具有Copy连续片段的能力。
其实前面的图示已经展示了这种Copy机制,它其实就是在Decoder部分多加一个序列预测任务,即原来Decoder建模的是每个Token的分布$p(y_t|y_{< t}, x)$,现在多预测一个标签分布,变为
\begin{equation}p(y_t, z_t|y_{< t}, x) = p(y_t|y_{< t}, x) p(z_t|y_{< t}, x)\end{equation}
其中$z_t\in\{\text{B},\text{I},\text{O}\}$,含义如下:
B:表示该token复制而来;
I:表示该token复制而来且跟前面Token组成连续片段;
O:表示该token不是复制而来的。
那么,训练时$z$的标签哪里来呢?这里直接采用一种比较简单的方法:算摘要与原文的“最长公共子序列”,只要是出现在最长公共子序列的token,都算是Copy过来的,根据BIO的具体含义设置不同的标签。比如前面图片中的例子,“我 真的 非常 热爱 我 的 祖国”与“我 爱 我 的 祖国”的最长公共子序列“我 我 的 祖国”,其中第一个“我”是单字,标签为B,后面“我 的 祖国”是一个连续片段,标签为“B I I”,其他标签为O,所以总的标签为“B O B I I”。
所以,在训练阶段,其实就是多了一个序列预测任务,并且标签都是已知的,实现起来很容易,也不增加什么计算成本。至于预测阶段,对于每一步,我们先预测标签$z_t$,如果$z_t$是O,那么不用改变,如果$z_t$是B,那么在token的分布中mask掉所有不在原文中的token,如果$z_t$是I,那么在token的分布中mask掉所有不能组成原文中对应的n-gram的token。也就是说,解码的时候还是一步步解码,并不是一次性生成一个片段,但可以通过mask的方式,保证BI部分位置对应的token是原文中的一个片段。
需要指出的是,Copy机制的引入未必能明显提高分数,印象中好像只提升了0.5%左右,但是Copy机制可以保证摘要与原始文本的忠实程度,避免出现专业性错误,这在实际使用中是相当必要的。
稀疏Softmax #
在这次比赛中,我们还发现了一个Softmax及交叉熵代替品,我们称之为Sparse Softmax,我们发现Sparse Softmax可以在相当多的分类问题(包括常规分类问题和文本生成等)中替换掉Softmax,并且效果能得到一定的提升。
Sparse Softmax的思想源于《From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification》、《Sparse Sequence-to-Sequence Models》等文章,里边作者提出了将Softmax稀疏化的做法来增强其解释性乃至提升效果。但笔者嫌里边的设计太麻烦,于是自己想了一个更简单的版本:
\begin{array}{c|c|c}
\hline
& \text{原版} & \text{稀疏版} \\
\hline
softmax & p_i = \frac{e^{s_i}}{\sum\limits_{j=1}^{n} e^{s_j}} & p_i=\left\{\begin{aligned}&\frac{e^{s_i}}{\sum\limits_{j\in\Omega_k} e^{s_j}},\,i\in\Omega_k\\ &\quad 0,\,i\not\in\Omega_k\end{aligned}\right.\\
\hline
交叉熵 & \log\left(\sum\limits_{i=1}^n e^{s_i}\right) - s_t & \log\left(\sum\limits_{i\in\Omega_k} e^{s_i}\right) - s_t\\
\hline
\end{array}
其中$\Omega_k$是将$s_1, s_2, \dots, s_n$从大到小排列后前$k$个元素的下标集合。说白了,我们提出的Sparse Softmax就是在计算概率的时候,只保留前$k$个,后面的直接置零,$k$是人为选择的超参数,这次比赛中我们选择了$k=10$。在算交叉熵的时候,则将原来的对全体类别$\text{logsumexp}$操作,改为只对最大的$k$个类别进行,其中$t$代表目标类别。
为什么稀疏化之后会有效呢?我们认为这是因为避免了Softmax的过度学习问题。假设已经成功分类,那么我们有$s_{\max}=s_t$(目标类别的分数最大),此时我们可以推导原始交叉熵的一个不等式:
\begin{equation}\begin{aligned}
\log\left(\sum\limits_{i=1}^n e^{s_i}\right)-s_{\max} &= \log\left(1+\sum\limits_{i\neq t} e^{s_i-s_{\max}}\right)\\
&\geq \log\left(1+(n-1) e^{s_{\min}-s_{\max}}\right)
\end{aligned}\end{equation}
假设当前交叉熵值为$\varepsilon$,那么解得
\begin{equation}s_{\max} - s_{\min}\geq \log (n-1) - \log \left(e^{\varepsilon} - 1\right)
\end{equation}
我们以$\varepsilon=\ln 2=0.69...$为例,这时候$\log \left(e^{\varepsilon} - 1\right)=0$,那么$s_{\max} - s_{\min}\geq \log (n-1)$。也就是说,为了要loss降到0.69,那么最大的logit和最小的logit的差就必须大于$\log (n-1)$,当$n$比较大的时候,对于分类问题来说这是一个没有必要的过大的间隔,因为我们只希望目标类的logit比所有非目标类都要大一点就行,但是并不一定需要大$\log (n-1)$那么多,因此常规的交叉熵容易造成过度学习而导致过拟合,而截断之后就不会有这个问题。
在这次比赛中,Sparse Softmax带来的提升可能(没有细测)有2%左右!同时,我们私下还补充做了很多实验,包括NLP和CV的,发现它在大多数任务上都有1%的提升,所以非常欢迎大家尝试!不过,我们也发现,Sparse Softmax只适用于有预训练的场景,因为预训练模型已经训练得很充分了,因此finetune阶段要防止过拟合;但是如果你是从零训练一个模型,那么Sparse Softmax会造成性能下降,因为每次只有$k$个类别被学习到,反而会存在学习不充分的情况(欠拟合)。
其他细节 #
在训练生成模型的时候,我们加入了EMA(权重滑动平均),这能使得训练过程更加稳定,甚至可能提升模型效果。事实上,EMA基本是笔者打比赛的标配,它能让我们省一些调试训练策略的心。
此外,在谈到BIO Copy机制时,我们说到理论上只需要在Decoder处新增一个BIO预测,不过在实际训练的时候,我们同时在Encoder和Decoder处都加了,我们发现这样能提升模型的最终效果。直观来想的话,起作用的原因应该是同时加的话增强了Encoder和Decoder之间的同步性,能够引导Decoder更精准地Attention到Encoder的合理的位置。
至于其他要补充的,还在想,想到了再补充吧。
代码开源 #
SPACES模型的源码已经发布在Github上:
SPACECS:https://github.com/bojone/SPACES
使用说明在Github上也有介绍,这里就不重复了,有问题可以提issue或者留言。开源是技术进步的动力,在非利益相关的情况下,笔者会尽量做到开源,也鼓励大家开源。
可能有读者想看看当前的自动摘要能生成到什么程度了,这里演示一个例子吧(验证集的样本,无人工修改,第一行是原文,第二行是标准摘要,第三行是模型摘要,绿色部分是标准摘要与模型摘要的最长公共子序列):

最终生成效果演示(一)

最终生成效果演示(二)
文章小结 #
本文总结了我们做法研杯司法摘要任务的经验,提出了一个名为SPACES的长文本摘要模型,它通过“先抽取后生成”的方式,结合了我们自研的BIO Copy机制、Sparse Softmax等方法,最终可以得到比较靠谱的摘要结果,欢迎大家交流使用。
转载到请包括本文地址:https://kexue.fm/archives/8046
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jan. 01, 2021). 《SPACES:“抽取-生成”式长文本摘要(法研杯总结) 》[Blog post]. Retrieved from https://kexue.fm/archives/8046
@online{kexuefm-8046,
title={SPACES:“抽取-生成”式长文本摘要(法研杯总结)},
author={苏剑林},
year={2021},
month={Jan},
url={\url{https://kexue.fm/archives/8046}},
}

January 2nd, 2021
感谢苏神分享,元旦快乐!
January 2nd, 2021
建模思路的预训练方法拼写错了
谢谢,已经修正。
January 4th, 2021
苏神您好,bert直接生成的句向量效果并不理想,也有很多论文提到,请问这里为啥要直接用bert的句向量作为输入呢
你要理解“bert直接生成的句向量效果并不理想”这句话的具体含义。
一般来说,它是指直接把BERT的CLS向量拿出来效果很差,但是“BERT+平均池化”拿出来的向量还是可圈可点的;然后,一般说句向量不理想,指的是直接用它做语义检索(算cos值)不理想,但我这里也不是直接算cos值,而是用来接其他模型做标注,因此句向量本身不是特别重要,我估计直接tf-idf加权平均词向量来构建句向量也不会很差;最后,我还试过用SimBERT来抽这个句向量,发现效果也差不多(但是SimBERT的语义检索能力好很多,所以说明语义检索效果的好坏,不能说明这里的效果的好坏)。
感谢苏神的解答
January 4th, 2021
苏神,我想把你的unilm模型用bert4keras训练后转成ckpt的格式然后用bert源码进行加载,但是我发现好像转换成ckpt后,tensor的name都变了,比如·cls/predictions/transform/dense/bias变成了MLM-Bias/bias,这要怎么才能行得通啊
需要在issue认真搜索答案。
https://github.com/bojone/bert4keras/issues/255
January 5th, 2021
关于BIO copy,在训练时,当为B、I的情况下需不需要mask掉不相关的token
不需要。
January 5th, 2021
苏神你好,我在用你开源的代码训练跑的时候出现了如下错误,
python: can't open file 'seq2seq_words.py': [Errno 2] No such file or directory
在github上也没有找到这个文件,这个文件能方便共享参考一下吗,多谢!
哦哦,不好意思,是我疏忽了,这一句可以不用跑,因为词典我都已经给出了。Github上的这一句已经删掉了。
January 5th, 2021
感谢分享,期待很久了!看了Sparsemax那两篇论文,请问pos_loss和neg_loss - pos_loss这个不为什么要这样计算呢?
猜不出“这个不为什么要这样计算呢”想要表达什么。
不好意思,打错了,“是这个为什么要这样计算呢”。可能我没看太明白原始论文,看了下别的sparsemax实现,不太理解苏神这样化简的道理。
我的实现是按照我的Sparse Softmax来写的,Sparse Softmax是我们提出的一个新的定义,不是Sparsemax的等价形式,跟Sparsemax互不包含。
好的,neg_lose我也用过类似思想的方法,比如纠错的时候,不预测整个词表大小,限制近音和混淆音表里,或者是Online Hard Sample Mining这种。pos_lose就是正常的seq2seq的loss,不太理解二者相减的道理,然后去套sparsemax的解释了。期待论文。
你怕是没看清源码吧?正常的交叉熵loss也是neg_loss-pos_loss的形式的,我这个只是交叉熵的简单变体。
是我看没理解LogSumExp和交叉熵关系(哭笑),懂了懂了, 感谢~!
@平常心|comment-15199
祝贺,哈哈~
January 6th, 2021
苏神您好,我想问下为什么用抽取模型的输出作为生成模型的输入,这种输入不是受抽取模型的影响吗?不是应该用extract_matching中找到的句子作为标准输入吗?
你最终要将两个模型串起来使用的,实际使用的时候,没有extract_matching可用,都是抽取模型出来的结果呀。如果你训练的时候用extract_matching,而抽取模型出来的结果又没有extract_matching那么好,那不就增加了累积误差?
好的 谢谢苏神回复
January 7th, 2021
想请教一下计算交叉熵loss的时候为什么copy_loss需要乘以2 seq2seq_loss + 2 * copy_loss
就是copy_loss的权重为2的意思咯,多个loss加权混合不是很常见的做法么?
多谢解答
January 12th, 2021
你好,想问下运行extract_convert时,在执行covert函数中的parallel_apply操作,显示下面的这个错误,不知道是什么原因呢?
File "F:/python_data/keras-bert研究/SPACES-main-司法长文本摘要/extract_convert.py", line 77, in convert
max_queue_size=10
File "C:\Users\sheji-1\Anaconda2\envs\py3\lib\site-packages\bert4keras\snippets.py", line 159, in parallel_apply
random_seeds = np.random.randint(0, 2**32, workers)
File "mtrand.pyx", line 744, in numpy.random.mtrand.RandomState.randint
File "_bounded_integers.pyx", line 1343, in numpy.random._bounded_integers._rand_int32
ValueError: high is out of bounds for int32
这可能是windows的固有毛病,你有两个选择:
1、使用github上最新版的bert4keras;
2、自己修改bert4keras源码,就是错误信息中的C:\Users\sheji-1\Anaconda2\envs\py3\lib\site-packages\bert4keras\snippets.py的159行,把 random_seeds = np.random.randint(0, 2**32, workers) 改为 random_seeds = [None] * workers 。
谢谢,我试试