






7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 176413位读者 |前段时间刷Arixv的时候,发现清华大学开源了一个大规模的中文闲聊语料库LCCC(论文链接,项目地址),从开源的文件上来看,这可能是目前开源的数量最大、质量最好的闲聊语料库了,而且还包含了部分多轮对话聊天,总的来说可玩性还是蛮强的。笔者也被它吸引到了,尝试着用它来训练了一个闲聊对话模型,结果看上去还是不错的,在此分享一下自己的经验。
语料简介 #
这里简单介绍一下LCCC这个数据集(Large-scale Cleaned Chinese Conversation),具体细节大家可以去Github上看,下载链接也在上面。LCCC分base和large两个版本,base主要是来源于微博对话,large则是在base的基础上融合了其他开源对话语料,按照作者的说法,LCCC经过了严格的清洗过程,所以整体质量看上去还是很不错的。
\begin{array}{c|c|c}
\hline
\text{LCCC-base} & \text{单轮对话} & \text{多轮对话} \\
\hline
\text{总对话轮次} & \text{3,354,382} & \text{3,466,607}\\
\hline
\text{总对话语句} & \text{6,708,554} & \text{13,365,268}\\
\hline
\end{array}\begin{array}{c|c|c}
\hline
\text{LCCC-large} & \text{单轮对话} & \text{多轮对话} \\
\hline
\text{总对话轮次} & \text{7,273,804} & \text{4,733,955}\\
\hline
\text{总对话语句} & \text{14,547,608} & \text{18,341,167}\\
\hline
\end{array}
为了简化任务,所有样本都被处理成双人对话。下面是一些样本示例:
A: 等过年咱们回去买点兔头好好吃顿火锅
B: 太原就没看见有好吃的兔头
A: 我从虹桥给你带个回去那天瞅到一正宗的
B: 最爱你了
A: 那是必须A: 嗯嗯,我再等等!你现在在上海吧?上海风好像比南京还大呢,少出门吧
B: 对啊,我在家,没事儿。一定要小心啊!A: 我去年也去转了一圈,还碰见以前的体育老师了,合了个影
B: 哈哈我还去找高一时侯的英语老师没找到她刚好有事情没在学校~
A: 你也是真心找回忆了哦
B: 哈哈毕业了没去过想去看看啊
模型设计 #
知道了数据长什么样之后,我们接下来就要去设计模型了。显然,我们需要做的就是训练一个模型,预测下一个该回复什么。既然语料里包含了多轮对话,那么我们还要求这个模型支持多轮对话。考虑对话历史的最简单的方式,就是把直到当前句的所有历史对话都拼接成单句文本,来作为模型的输入信息了。
给定一些输入,预测一个输出,从形式上来看我们应该用Seq2Seq模型。直接用Seq2Seq其实问题也不大,但标准的Seq2Seq一般用于形式比较固定的输入输出,比如输入的文本长度应该是集中在某个范围内,不宜变化太大,但考虑多轮对话的话,理论上我们也不知道前面有多少轮对话,因此原则上输入文本长度是无限制的。用Seq2Seq的话还有训练效率低的问题,就是我们每轮对话每次我们只能训练一句回复,如果一个多轮对话有$n$句回复,那么那么就要拆分为$n$个样本来训练了。
因此,我们需要一个长度能相当自由地变化的、同时能预测整一个多轮对话的模型,实现这个需求的比较适当的选择就是单向语言模型(LM、GPT),做法如下图:
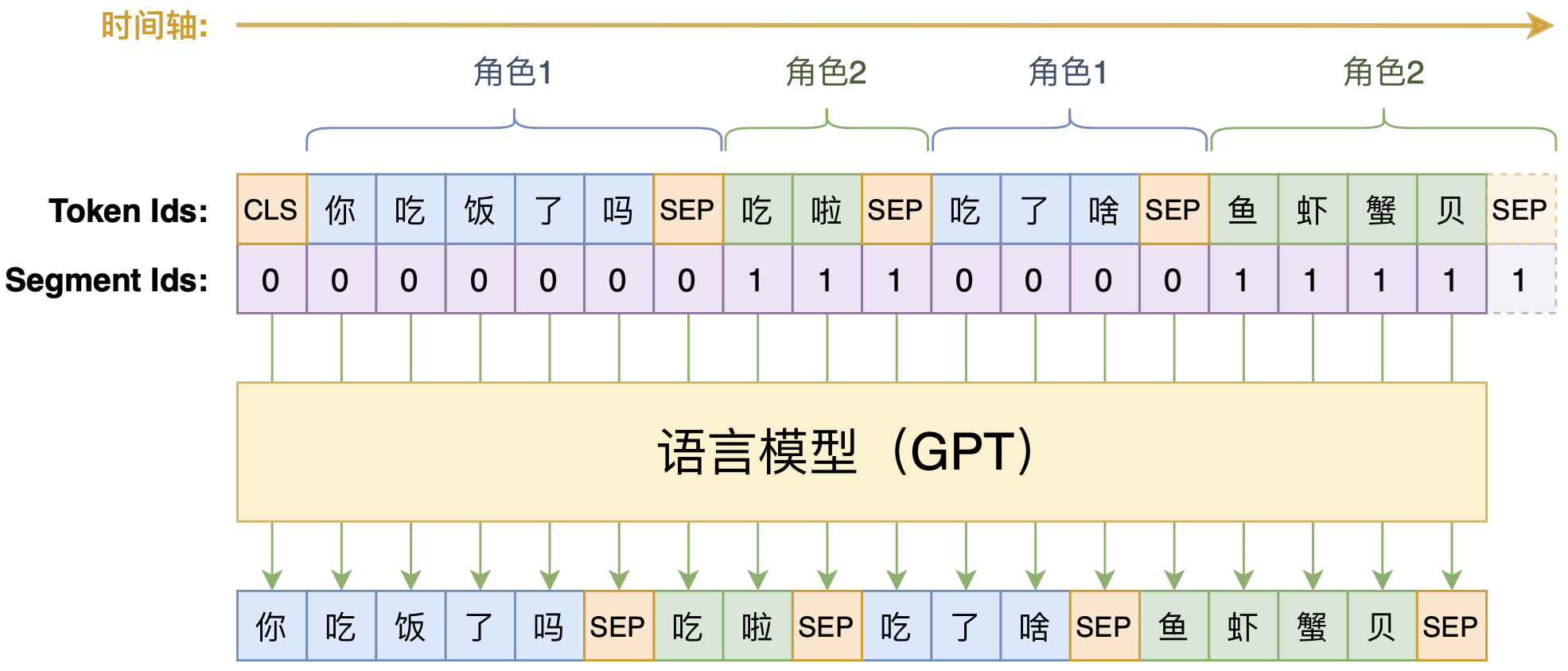
利用单向语言模型做多轮对话示意图
如图所示,我们选择当前主流的Transformer模型,按照BERT的常规输入格式,将每句对话用[SEP]拼接起来,然后就训练一个从左往右的单向语言模型。为了区分不同的说话角色,我们对不同的说话者用不同的Segment Id区分。此外,考虑到BERT和GPT都是用了绝对位置编码,可处理的文本长度存在一个上限,而对话轮数理论上是无限的,所以这里我们采用了相对位置编码的NEZHA作为基本结构,并使用NEZHA的预训练权重作为模型的初始化权重。
说白了,就是往NEZHA里边加入了下三角形式的Attention Mask,使其变为一个语言模型,相关介绍请参考《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。
训练细节 #
首先,给出笔者的参考实现以及训练好的模型:
代码基于bert4keras实现,基本结构是NEZHA Base。为了使得训练更加“平民化”,笔者只用了一张卡(22G的RTX)配合梯度累积来训练,显存不够大的读者可以缩小batch_size。开源的模型是用$2\times 10^{-5}$的学习率、$0.01$的权重衰减率的Adam优化器进行训练的,训练了1000万步(20多天),单步batch_size为16,累积梯度步数为16,所以相当于以256的batch_size训练了62.5万步,最终的loss大概是2.83(平均每token的交叉熵)。
我们来测试一下我们的训练结果。
>>> print(chatbot.response([u'我最近天天吃火锅']))
火锅好吃啊
>>> print(chatbot.response([u'我最近天天吃火锅']))
我也是
>>> print(chatbot.response([u'我最近天天吃火锅']))
哈哈哈哈哈哈我最近一周吃了两顿火锅
>>> print(chatbot.response([u'我最近天天吃火锅']))
我也是,每次都吃的撑
>>> print(chatbot.response([u'我最近天天吃火锅']))
吃火锅不长胖
>>> print(chatbot.response([u'我最近天天吃火锅']))
火锅好啊
>>> print(chatbot.response([u'我最近天天吃火锅']))
你们那边有这种火锅?
>>> print(chatbot.response([u'我最近天天吃火锅']))
火锅好吃吗?我也想吃
>>> print(chatbot.response([u'我最近天天吃火锅']))
吃吧,吃了就开心了
>>> print(chatbot.response([u'我最近天天吃火锅']))
我也想天天吃火锅!
>>> print(chatbot.response([u'我最近天天吃火锅']))
火锅吃不了多久的。>>> print(chatbot.response([u'你那天气好吗']))
还好,不热,有点冷
>>> print(chatbot.response([u'你那天气好吗', u'还好,不热,有点冷', u'那你得穿多厚的衣服']))
我穿了两件
对比分析 #
CDial-GPT也开源了自己训练的预训练模型,笔者也将它转换为bert4keras能加载的格式了(CDial-GPT-tf),读者也可以测试比对一下。从训练上来看,CDial-GPT使用pytorch实现的模型,基本结构是GPT Base,使用了4张2080Ti,总batch_size为32,累积梯度64步,论文说训练了30个epoch,总步数约2100万步(笔者的两倍),因此大概相当于batch_size为2048训练了33万步。
在输入设计上,CDial-GPT也有所不同,如下图:
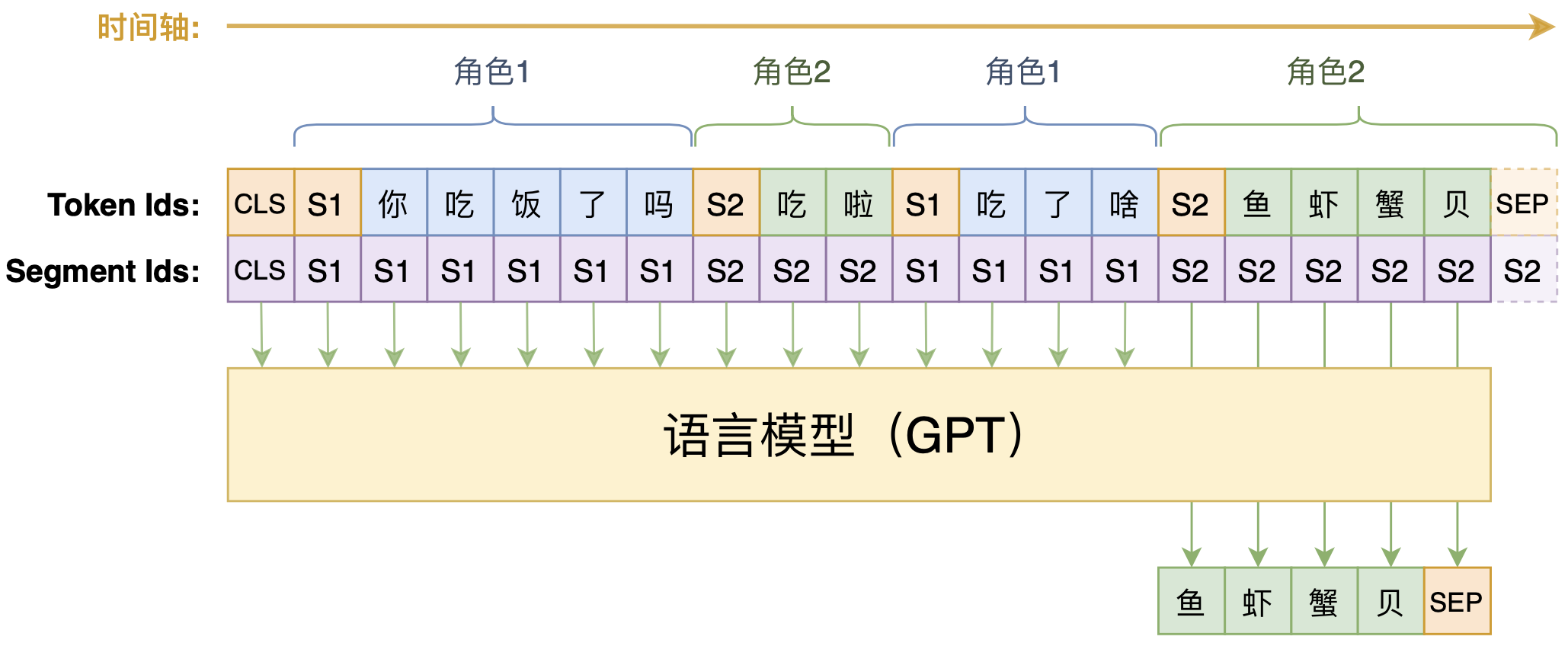
CDial-GPT模型示意图
如图所示,CDial-GPT跟我们前述设计的主要不同是多轮对话之间的拼接方式,我们之前是直接用[SEP]连接,它是用[speaker1]、[speaker2](图中简记为S1、S2)这样的角色标记来连接,最后才用一个[SEP]表示回复结束。这样一来,由于预测部分的格式跟历史的格式不一样,因此每次只能训练一句回复,多轮对话要拆分为多个样本来训练,理论上是增加了训练复杂性的(要训练多步才能把一个多轮对话样本训练完)。
至于效果上,个人测试的感觉是两者没什么明显差别。有兴趣的读者也可以自行比较测试。
文章总结 #
本文主要分享了一次对话模型实践,基于CDial-GPT开源的LCCC闲聊语料库,利用语言模型(GPT)对多轮对话进行生成式建模,得到了一个相对通用的闲聊对话模型,最后将本文的思路与CDial-GPT本身开源的模型进行了比较。
转载到请包括本文地址:https://kexue.fm/archives/7718
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 07, 2020). 《动手做个DialoGPT:基于LM的生成式多轮对话模型 》[Blog post]. Retrieved from https://kexue.fm/archives/7718
@online{kexuefm-7718,
title={动手做个DialoGPT:基于LM的生成式多轮对话模型},
author={苏剑林},
year={2020},
month={Sep},
url={\url{https://kexue.fm/archives/7718}},
}

May 8th, 2021
你好,请问为什么github上的LCCD-Large-shuf.json文件那么小呢,只有3KB大小,请问是放错文件了吗?还是说这个文件并不是拿来训练的语料库?求解答,谢谢
因为github的LCCD-Large-shuf.json只是数据示例,我只是分享代码,并不负责分享数据。
June 25th, 2021
苏神,有对话背景的多轮对话,还能用这种方式吗?要怎么mask怎么拼接才行得通?
可以考虑用seq2seq结构,然后把decoder做成本文的格式。
August 30th, 2021
你好,请问能否在Transformers中使用这个预训练模型呢?
August 16th, 2022
苏神,请问文章里面的模型示意图是用什么软件画的
draw.io
March 9th, 2023
你好,看segment_ids也是用了0进行了padding,在后续的训练中,请问下是怎么区分segment的0和padding的0?
token_ids的0一定会被mask掉,所以segment_ids不管用什么进行padding,都不会有影响。
April 10th, 2023
您好, 虽然看了您之前的回复,但还是不太理解CDial-GPT中的“由于预测部分的格式跟历史的格式不一样,因此每次只能训练一句回复,多轮对话要拆分为多个样本来训练”。一直以为language modeling只要右移一位就都能训练,不太懂语料拼接格式产生的影响,能否给出更详细一点的解释呢?
主要的问题是:CDial-GPT是通过[SEP]为终止标记,但是通过[S1]、[S2]分隔。那么以图上这个例子为例,S1说“你吃饭了吗”,模型就会回答“吃啦[S1]”,那我们是不是又要以[S1]为终止标记才行?所以这有点矛盾,因此CDial-GPT的做法是目标只预测最后一轮回复,以[SEP]为终止标记。
June 13th, 2023
您好,请问训练对话数据使用不同的拼接格式是否也取决于预训练模型?比如说,您使用NEZHA的词表中包含了[CLS]和[SEP],所以拼接中也可使用。而CDial-GPT基础预训练中除了[CLS]和[SEP],也使用了对话训练中有的[speaker1]和[speaker2]吗?(因为提到的GPT Novel未公开,所以不确定)我使用openai原本的GPT2去训练对话,由于词表中没有[CLS]和[SEP],却使用了的话,是不是因为模型没有对应的信息,所以才造成loss一直比较大?
不好意思,重新表述一下,就是在一个基础预训练模型上如GPT2或NEZHA,用对话数据集进一步预训练时,如果加入了新的special tokens作为分隔符,如[CLS]、[SEP](GPT词表中没有);[speaker1]、[speaker2](词表中都没有),那么这些special tokens的信息是在这个阶段学习吗?如果数据集比较小的话,模型是不是学习不到它们的作用?目前使用了GPT2和一个小数据集dailydialog,用了[CLS]utter1[SEP]utter2[SEP]这样的数据格式,但是训练loss一直比较大,不知道是否是上述的猜想原因?
不至于吧,本质还是个teacher forcing的语言模型,新增一两个token应该不会有啥致命影响。
是的,这几天改了新的数据载入方式,结果就好了,发现换special token根本不影响。但是目前还没找出来原来的哪里有bug...(评论可以增加删除功能吗?有时候想把原来说错的删了重发。)
抱歉,评论不支持自行删除,需要更正的在后面回复更正就好,整个思考过程应该也是值得大家参考的。
October 27th, 2023
请问训练的时候要怎么保存checkpoint 文件模型
mode.save_weights