






14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 154000位读者 |从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作 #
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
思路细节 #
Conditional Layer Normalization的想法来源于图像中流行的条件GAN的思路——条件BN(Conditional Batch Normalization),相关内容可以参考《从DCGAN到SELF-MOD:GAN的模型架构发展一览》。条件BN还有一个变种,称之为AdaIN(Adaptive Instance Normalization)。条件BN、AdaIN都是将已有的Normalization方法中的$\beta$和$\gamma$变成输入条件的函数,从而可以通过条件来控制生成的行为。
在Bert等Transformer模型中,主要的Normalization方法是Layer Normalization,所以很自然就能想到将对应的$\beta$和$\gamma$变成输入条件的函数,来控制Transformer模型的生成行为,这就是Conditional Layer Normalization的线索思路。(但目前还没有看到同样思路的工作出现,所以这算是笔者闭门造车出来的新鲜玩意了。)
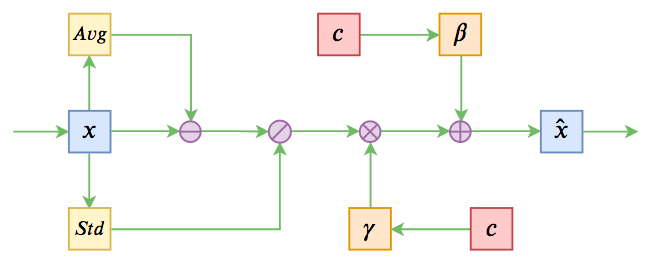
条件Normalization示意图
对于已经预训练好的模型来说,已经有现成的、无条件的$\beta$和$\gamma$了,它们都是长度固定的向量。我们可以通过两个不同的变换矩阵,将输入条件变换到跟$\beta,\gamma$一样的维度,然后将两个变换结果分别加到$\beta$和$\gamma$上去。为了防止扰乱原来的预训练权重,两个变换矩阵可以全零初始化(单层神经网络可以用全零初始化,连续的多层神经网络才不应当用全零初始化),这样在初始状态,模型依然保持跟原来的预训练模型一致。
代码实现 #
直觉上,这种以文本生成为目的的finetune应该要用GPT等自回归预训练模型才能提升效果,但事实上,之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》已经表明,哪怕你加载Bert的预训练权重来做生成任务,表现依然良好。所以不管哪种Transformer-based的预训练模型,都可以考虑用来finetune做文本生成模型来。而本文还是以预训练Bert为基础模型进行实验。
至于代码,本文所描述的Conditional Layer Normalization技巧,也已经被集成到笔者所开发的bert4keras中了,现在基础函数build_transformer_model新增了如下参数:
1、layer_norm_cond:如果该参数非None,则意味着它是一个张量,shape=[batch_size, cond_size],用来作为Layer Normalization的条件;
2、layer_norm_cond_size:如果该参数非None且layer_norm_cond为None,则意味着它是一个整数,自行构建一个shape=[batch_size, layer_norm_cond_size]的输入层作为Layer Normalization的条件;
3、layer_norm_cond_hidden_size:如果该参数非None,则意味着它是一个整数,用于先将输入条件投影到更低维空间,这是因为输入的条件可能维度很高,直接投影到hidden_size(比如768)的话,参数可能过多,所以可以先投影到更低维空间,然后升维;
4、layer_norm_cond_hidden_act:投影到更低维空间时的激活函数,如果为None,则不加激活函数(线性激活);
5、additional_input_layers:额外的输入层,如果外部传入了张量作为条件,则需要把条件张量所依赖的所有输入层都添加进来,作为输入层,才能构建最终的模型。
实验效果 #
介绍再多,其实还不如看例子来得实际。笔者做了两个实验来验证Conditional Layer Normalization的效果。一个是通过情感极性来控制文本生成,也就是情感分类的反问题,这直接通过类的Embedding来作为Layer Normalization的条件;另一个是图像描述生成(Image Caption),通过预训练的imagenet模型将图片编码为一个固定长度的向量作为Layer Normalization的条件。
这两个代码分别放在task_conditional_language_model.py和task_image_caption.py中。
情感文本生成 #
情感文本生成就是用的训练集是笔者之前收集整理的情感分类语料,将输入文本和标签反过来用即可。最后生成的时候按概率随机采样,从而能生成不同的文本。
部分输出:
正面采样:
[u'外观时尚、漂亮、性价比高。', u'外观漂亮,配置均衡,比较满意,性价比高,外观漂亮,性能较高。', u'我是在大学的时候看到这本书的,所以一直在买。书中的作者是林静蕾,她用自己的口吻写出了一个孩子成长中的心路历程,让我看到了她们成长中的不同之处,以及她们成长过程中的不同境界。让我很欣赏!', u'我想这是一本能够告诉读者什么是坏的,而不是教你怎样说话,告诉我什么是错。这里我推荐了《我要讲故事》,这本书是我很喜欢的一本书,我认为它的理由很多,但是,我相信我。如果你从中得到一些改进,或者你已经有了一个明智的决定。', u'我们一家五口住的是标间,大床房,大床的床很舒服;而我们在携程网上订了两套大床房,这个酒店的价格还是比较合理的;但是房间的隔音效果不太理想,有点响的声音;酒店门口的地铁在施工中,不方便;但是酒店的门口的出租车不知道是哪个车的,打车不是很方便;酒店外面的停']负面采样:
[u'不知道是不是因为电池不太好,不是我不喜欢。', u'看了评论才买的. 结果发现不是那么便宜, 价格也不便宜.', u'1、外壳不容易沾手印,不容易洗洗2、屏幕有点旧,不能下载铃声', u'我是7月6日订购了《杜拉拉升职记》并已通过银行付款,为什么订单下了两周多至今还未到货?是收货时间太快了,可能就这么过去了吧?', u'这本书我是在网上先看了一遍,后来我再看了一遍。感觉作者的文笔实在太烂了,特别是在写他的博客时特别别扭,写得很不专业,特别是他写股票时那个情绪调节的小男孩,简直就是自作聪明的样子,简直就是自作聪明的一种表现!']
Image Caption #
Image Caption以COCO数据集为例,这个数据集的图片场景比较丰富一些。另外2017年的challenger.ai也举办过一个图像中文描述生成竞赛,里边也包含了一个不错的数据集(读者自己自行想办法收集),不过图片的场景相对来说单调一些。
部分输出:

模型预测: a baseball game in progress with the batter up to plate.

模型预测: a train that is sitting on the tracks.
image_id: COCO_val2014_000000524611.jpg
url: http://images.cocodataset.org/val2014/COCO_val2014_000000524611.jpg
predict: a train that is sitting on the tracks.
references: [u'A train carrying chemical tanks traveling past a water tower.', u'Dual train tracks with a train on one of them and a water tower in the background.', u'a train some trees and a water tower ', u'Train on tracks with water tower for Davis Junction in the rear.', u'A train on a train track going through a bunch of trees.']image_id: COCO_val2014_000000202923.jpg
url: http://images.cocodataset.org/val2014/COCO_val2014_000000202923.jpg
predict: a baseball game in progress with the batter up to plate.
references: [u'Batter, catcher, and umpire anticipating the next pitch.', u'A baseball player holding a baseball bat in the game.', u'A baseball player stands ready at the plate.', u'Baseball players on the field ready for the pitch.', u'A view from behind a mesh fence of a baseball game.']
文章小结 #
提出了利用Conditional Layer Normalization来将外部条件融入到预训练模型中的思路,其直接应用就是条件文本生成,但其实也不单单可以用于生成模型,也可以用于分类模型等场景(外部条件可能是其他模态的信息,来辅助分类)。最后基于bert4keras给出了代码实现以及两个例子。
转载到请包括本文地址:https://kexue.fm/archives/7124
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Dec. 14, 2019). 《基于Conditional Layer Normalization的条件文本生成 》[Blog post]. Retrieved from https://kexue.fm/archives/7124
@online{kexuefm-7124,
title={基于Conditional Layer Normalization的条件文本生成},
author={苏剑林},
year={2019},
month={Dec},
url={\url{https://kexue.fm/archives/7124}},
}

January 14th, 2020
您好,我在使用本文的条件文本生成时使用了 albert 的预训练模型,但是在示例数据上经过多轮训练后没有结果输出,而换用其他数据时会直接梯度爆炸,但是使用 bert 的预训练权重则没有该问题。已经调整过学习率并换用了几个不同版本的 albert 模型,但还是没能解决。请问一下出现这种现象是什么原因导致的,是与Transformer的共享结构有关吗?
你用什么框架加载的?如果你用bert4keras,那直觉来看是因为使用不当导致的,别着急找模型的问题,好好看看README.md以及自己的代码~
June 29th, 2020
博主写的所有博客都非常好,太厉害了。看了这篇之后,有个疑问,最近在研究生成模型,比如说生成文本小说之类。可以直接用transformer传统的模型吗?还是说只能用其中的encoder或者是decoder呢?
什么叫做“transformer传统的模型”?
应该是说整个transform模型吧,包含encoder和decoder。感觉生成任务的时候,这个encoder会泄露信息吧?
encoder不编码目标序列就不会泄漏
明白了,感谢苏神~
July 29th, 2020
苏老师你的代码写的真好
谢谢
August 5th, 2020
苏神,我尝试阅读并运行了下你的情感文本任务代码.不知道我理解的对不对,文中的意思是通过将外部条件转化为和Normlization参数维度相同的向量并相加参与预测,以达到控制生成的效果.
在代码中推理阶段,通过self.random_sample([[label]], n, topk)将外部条件也就是label传递进去,然后模型进行随机采样,达到条件生成的效果.
显然,这种控制生成显然没有gpt类型的自回归更适合实际场景,也就是给个label,给一段开头,进行条件生成.我正在尝试结合gpt以及文中的方式,请问苏神尝试过吗
如果你真的知道什么叫做语言模型,什么叫做条件语言模型,那自然知道本文的模型是可以实现“是给个label,给一段开头”来进行条件生成的。本文模型就相当于加了label控制的gpt而已..
嗯 我意思是你的具体实现代码里用的是bert吧 然后做的随机采样 我跑了一下4个类别的大概30w条数据,感觉生成的结果不够好,风格不够明显。猜测结合gpt去做有预输入的生成可能会好看一些。想问问你试过没有。还有我没有显示地看到把控制类别的embedding结合到gamma或者beta里,方便的话能讲下在哪里做的吗?
哪里有中文gpt下载?
August 19th, 2020
苏神 我问个问题 假设我有一批数据(64,128,768)也就是经过embedding的lm输入,现在我想使用他们的类别信息也就是(64,1),其中具体类别为0,1,2,3的4个类别,所以我经过一个假设的(4,100)的embedding矩阵得到了 64×1×100的类别信息对应的嵌入 然后 layernorm本质上gamma beta是一个768维度的向量,所以为了对齐,需要经过一个dense层,假设dense层weights为100×768,所以我得到了64×1×768的类别矩阵,也就是说每个样本都有一个对应着他自己的类别的768维的向量,然后应该怎么处理??? 我觉得如果把多个类别的64×1×768强行变为1×768就失去了类别存在的意义了。所以我尝试取消了原来的gamma beta,取而代之用这个64×1×768的去和64×128×768相乘,但是这样没啥效果,ppl一直是500多。
苏神有什么建议吗???谢谢!
bert4keras就是“用这个64×1×768的去和64×128×768相乘”的,但不是直接相乘,就是“64×1×768”这个tensor加上1后再与“64×128×768”相乘。实现请参考这里的LayerNormalization层:https://github.com/bojone/bert4keras/blob/master/bert4keras/layers.py
你说的应该是这里self.gamma = self.add_weight(shape=shape, initializer='ones', name='gamma') 以及 if self.scale: gamma = self.gamma_dense(cond) + self.gamma这两个地方吧 这么做实际上就是给64×1×768 每个位置+1,可能并不会缓解我这个ppl的问题? 甚至因为参数更多了反而更不好收敛? 所以我要做下实验,另外,苏神关于类别控制生成还有什么比较好用的方法介绍吗?
说错了,我那里不是加1,而是把64×1×100到64×1×768的dense层全零初始化,然后将它加到原来的gamma上面去。
你这个问题看上去像是训练不好的问题,而不是模型能力有限,所以我想更重要的是要寻找更好的初始化,让它能训练好。
November 23rd, 2020
Nice work! I have Implement it on news comments generation task. The outcome is outstanding.
November 24th, 2020
请问,additional_input_layers 这个参数的作用是什么呢?在call里的apply_embeddings 和 apply_main_layers 都是只取了tokens和segments(以及position),似乎这个输入层信息好像在这里就断掉了?
April 11th, 2021
“将输入条件变换到跟β,γ一样的维度,然后将两个变换结果分别加到β和γ上去” 请问苏神,在您的情感任务中,若输入为1,那得到的变换结果应该是什么样的呢,不好意思我比较菜,看了半天不知道定位源码哪个位置
如果我在transformers里的代码修改,该如何改呢?非常感谢!
class BertLayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-12):
super(BertLayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size))
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
输入不是1,输入是one hot,比如2维向量[0, 1],然后通过2*d的矩阵变换为d维。
不好意思 请问这块对应您的源码哪块地方呀
bert4keras/layers.py
April 16th, 2021
[...]本文思路来源于苏建林大佬的Conditional Layer Normalization,本人整理消化后写的笔记。[...]
April 28th, 2021
layer_norm_cond_hidden_size:如果该参数为None,则意味着它是一个整数,用于先将输入条件投影到更低维空间
苏神大大,这段话应该是非None吧,打错字了?
谢谢,已经修正。