






7
Nov
WGAN-div:一个默默无闻的WGAN填坑者
By 苏剑林 | 2018-11-07 | 201585位读者 |今天我们来谈一下Wasserstein散度,简称“W散度”。注意,这跟Wasserstein距离(Wasserstein distance,简称“W距离”,又叫Wasserstein度量、Wasserstein metric)是不同的两个东西。
本文源于论文《Wasserstein Divergence for GANs》,论文中提出了称为WGAN-div的GAN训练方案。这是一篇我很是欣赏却默默无闻的paper,我只是找文献时偶然碰到了它。不管英文还是中文界,它似乎都没有流行起来,但是我感觉它是一个相当漂亮的结果。
如果读者需要入门一下WGAN的相关知识,不妨请阅读拙作《互怼的艺术:从零直达WGAN-GP》。
WGAN #
我们知道原始的GAN(SGAN)会有可能存在梯度消失的问题,因此WGAN横空出世了。
W距离 #
WGAN引入了最优传输里边的W距离来度量两个分布的距离:
\begin{equation}W_c[\tilde{p}(x), q(x)] = \inf_{\gamma\in \Pi(\tilde{p}(x), q(x))} \mathbb{E}_{(x,y)\sim \gamma}[c(x,y)] \end{equation}
这里的$\tilde{p}(x)$是真实样本的分布,$q(x)$是伪造分布,$c(x,y)$是传输成本,论文中用的是$c(x,y)=\Vert x-y\Vert$;而$\gamma\in \Pi(\tilde{p}(x), q(x))$的意思是说:$\gamma$是任意关于$x, y$的二元分布,其边缘分布则为$\tilde{p}(x)$和$q(y)$。直观来看,$\gamma$描述了一个运输方案,而$c(x,y)$则是运输成本,$W_c[\tilde{p}(x), q(x)]$就是说要找到成本最低的那个运输方案所对应的成本作为分布度量。
对偶问题 #
W距离确实是一个很好的度量,但显然不好算。当$c(x,y)=\Vert x-y\Vert$时,我们可以将其转化为对偶问题:
\begin{equation}W(\tilde{p}(x), q(x)) = \sup_{\Vert T\Vert_L\leq 1} \mathbb{E}_{x\sim \tilde{p}(x)}[T(x)] - \mathbb{E}_{x\sim q(x)}[T(x)]\label{eq:wgan-d}\end{equation}
其中$T(x)$是一个标量函数,$\Vert T\Vert_L$则是Lipschitz范数:
\begin{equation}\Vert T\Vert_L = \max_{x\neq y} \frac{|T(x)-T(y)|}{\Vert x - y\Vert}\end{equation}
说白了,$T(x)$要满足:
\begin{equation}|T(x)-T(y)| \leq \Vert x - y\Vert\end{equation}
生成模型 #
这样一来,生成模型的训练,可以作为W距离下的一个最小-最大问题:
\begin{equation}\mathop{\text{argmin}}_{G}\mathop{\text{argmax}}_{T,\Vert T\Vert_L\leq 1} \mathbb{E}_{x\sim \tilde{p}(x)}[T(x)] - \mathbb{E}_{x\sim q(z)}[T(G(z))]\end{equation}
第一个$\text{argmax}$试图获得W距离的近似表达式,而第二个$\text{argmin}$则试图最小化W距离。
然而,$T$不是任意的,需要满足$\Vert T\Vert_L\leq 1$,这称为Lipschitz约束(L约束),该怎么施加这个约束呢?因此,一方面,WGAN开创了GAN的一个新流派,使得GAN的理论上了一个新高度,另一方面,WGAN也挖了一个关于L约束的大坑,这个坑也引得不少研究者前仆后继地...(跳坑?)
L约束 #
目前,往模型中加入L约束,有三种主要的方案。
权重裁剪 #
这是WGAN最原始的论文所提出的一种方案:在每一步的判别器的梯度下降后,将判别器的参数的绝对值裁剪到不超过某个固定常数。
这是一种非常朴素的做法,现在基本上已经不用了。其思想就是:L约束本质上就是要网络的波动程度不能超过一个线性函数,而激活函数通常都满足这个条件,所以只需要考虑网络权重,最简单的一种方案就是直接限制权重范围,这样就不会抖动太剧烈了。
梯度惩罚 #
这种思路非常直接,即$\Vert T\Vert_L\leq 1$可以由$\Vert \nabla T\Vert \leq 1$来保证,所以干脆把判别器的梯度作为一个惩罚项加入到判别器的loss中:
\begin{equation}T=\mathop{\text{argmin}}_{T} -\mathbb{E}_{x\sim \tilde{p}(x)}[T(x)] + \mathbb{E}_{x\sim q(x)}[T(x)] + \lambda \mathbb{E}_{x\sim r(x)}\Big[\big(\Vert \nabla T\Vert - 1\big)^2\Big]\end{equation}
但问题是我们要求$\Vert T\Vert_L\leq 1$是在每一处都成立,所以$r(x)$应该是全空间的均匀分布才行,显然这很难做到。所以作者采用了一个非常机智(也有点流氓)的做法:在真假样本之间随机插值来惩罚,这样保证真假样本之间的过渡区域满足L约束。
这种方案就是WGAN-GP。显然,它比权重裁剪要高明一些,而且通常都work得很好。但是这种方案是一种经验方案,没有更完备的理论支撑。
谱归一化 #
另一种实现L约束的方案就是谱归一化(SN),可以参考我之前写考《深度学习中的Lipschitz约束:泛化与生成模型》。
本质上来说,谱归一化和权重裁剪都是同一类方案,只是谱归一化的理论更完备,结果更加松弛。而且还有一点不同的是:权重裁剪是一种“事后”的处理方案,也就是每次梯度下降后才直接裁剪参数,这种处理方案本身就可能导致优化上的不稳定;谱归一化是一种“事前”的处理方案,它直接将每一层的权重都谱归一化后才进行运算,谱归一化作为了模型的一部分,更加合理一些。
尽管谱归一化更加高明,但是它跟权重裁剪一样存在一个问题:把判别器限制在了一小簇函数之间。也就是说,加了谱归一化的$T$,只是所有满足L约束的函数的一小部分。因为谱归一化事实上要求网络的每一层都满足L约束,但这个条件太死了,也许这一层可以不满足L约束,下一层则满足更强的L约束,两者抵消,整体就满足L约束,但谱归一化不能适应这种情况。
WGAN-div #
在这种情况下,《Wasserstein Divergence for GANs》引入了W散度,它声称:现在我们可以去掉L约束了,并且还保留了W距离的好性质。
论文回顾 #
有这样的好事?我们来看看W散度是什么。一上来,作者先回顾了一些经典的GAN的训练方案,然后随手扔出一篇文献,叫做《Partial differential equations and monge-kantorovich mass transfer》,里边提供了一个方案(下面的出场顺序跟论文有所不同),能直接将$T$训练出来,目标是(跟原文的写法有些不一样)
\begin{equation}T^* = \mathop{\text{argmax}}_{T} \mathbb{E}_{x\sim \tilde{p}(x)}[T(x)] - \mathbb{E}_{x\sim q(x)}[T(x)] - \frac{1}{2}\mathbb{E}_{x\sim r(x)}[\Vert \nabla T\Vert^2]\label{eq:wgan-div-d1}\end{equation}
这里的$r(x)$是一个非常宽松的分布,我们后面再细谈。整个loss的意思是:你只要按照这个公式将$T$训练出来,它就是$\eqref{eq:wgan-d}$式中的$T$的最优解,也就是说,接下来只要把它代进$\eqref{eq:wgan-d}$式,就得到了W距离,最小化它就可以得到生成器了。
\begin{equation}\mathop{\text{argmin}}_{G}\mathbb{E}_{x\sim \tilde{p}(x)}[T^*(x)] - \mathbb{E}_{x\sim q(z)}[T^*(G(z))]\label{eq:wgan-div-g1}\end{equation}
一些注解 #
首先,我为什么说作者“随手”跑出一篇论文呢?因为作者确实是随手啊...
作者直接说“According to [19]”,然后就给出了后面的结果,[19]就是这篇论文,是一篇最优传输和偏微分方程的论文,59页...我翻来翻去,才发现作者引用的应该是36页和40页的结果(不过翻到了也没能进一步看懂,放弃了),也不提供多一点参考资料,尴尬~~还有后面的一些引理,作者也说“直接去看[19]的discussion吧”.....
然后,读者更多的疑问是:这玩意跟梯度惩罚方案有什么差别,加个负号变成最小化不都是差不多吗?做实验时也许没有多大差别,但是理论上的差别是很大的,因为WGAN-GP的梯度惩罚只能算是一种经验方案,而$\eqref{eq:wgan-div-d1}$式是有理论保证的。后面我们会继续讲完它。
W散度 #
式$\eqref{eq:wgan-div-d1}$是一个理论结果,而不管怎样深度学习还是一门理论和工程结合的学科,所以作者一般化地考虑了下面的目标
\begin{equation}W_{k,p}[\tilde{p}(x), q(x)] = \max_{T} \mathbb{E}_{x\sim \tilde{p}(x)}[T(x)] - \mathbb{E}_{x\sim q(x)}[T(x)] - k\mathbb{E}_{x\sim r(x)}[\Vert \nabla T\Vert^p]\label{eq:wdiv}\end{equation}
其中$k > 0, p > 1$。基于此,作者证明了$W_{k,p}$有非常好的性质:
1、$W_{k,p}$是个对称的散度。散度的意思是:$\mathcal{D}[P,Q]\geq 0$且$\mathcal{D}[P,Q]=0\Leftrightarrow P=Q$,它跟“距离”的差别是它不一定满足三角不等式,也有叫做“半度量”、“半距离”的。$W_{k,p}$是一个散度,这已经非常棒了,因为我们大多数GAN都只是在优化某个散度而已。散度意味着当我们最小化它时,我们真正是在缩小两个分布的距离。
2、$W_{k,p}$的最优解跟W距离有一定的联系。$\eqref{eq:wgan-div-d1}$式就是一个特殊的$W_{1/2,2}$。这说明当我们最大化$W_{k,p}$得到$T$之后,可以去掉梯度项,通过最小化$\eqref{eq:wgan-div-g1}$来训练生成器。这也表明以$W_{k,p}$为目标,性质跟W距离类似,不会有梯度消失的问题。
3、这是我觉得最逗的一点,作者证明了
\begin{equation}\max_{T} \mathbb{E}_{x\sim \tilde{p}(x)}[T(x)] - \mathbb{E}_{x\sim q(x)}[T(x)] - k\mathbb{E}_{x\sim r(x)}[(\Vert \nabla T\Vert - n)^p]\end{equation}
不总是一个散度。当$n=1,p=2$时这就是WGAN-GP的梯度惩罚,作者说它不是一个散度,明摆着要跟WGAN-GP对着干,哈哈哈~~不是散度意味着WGAN-GP在训练判别器的时候,并非总是会在拉大两个分布的距离(鉴别者在偷懒,没有好好提升自己的鉴别技能),从而使得训练生成器时回传的梯度不准。
WGAN-div #
好了,说了这么久,终于可以引入WGAN-div了,其实就是基于$\eqref{eq:wdiv}$的WGAN的训练模式了:
\begin{equation}\begin{aligned}T =& \mathop{\text{argmax}}_{T} \mathbb{E}_{x\sim \tilde{p}(x)}[T(x)] - \mathbb{E}_{x\sim q(x)}[T(x)] - k\mathbb{E}_{x\sim r(x)}[\Vert \nabla T\Vert^p]\\
G =& \mathop{\text{argmin}}_{G} \mathbb{E}_{x\sim \tilde{p}(x)}[T(x)] - \mathbb{E}_{x\sim q(z)}[T(G(z))]\end{aligned}\end{equation}
前者是为了通过W散度$W_{k,p}$找出W距离中最优的$T$,后者就是为了最小化W距离。所以,W散度的角色,就是一个为W距离的默默无闻的填坑者呀,再结合这篇论文本身的鲜有反响,我觉得这种感觉更加强烈了。
实验 #
k,p的选择 #
作者通过做了一批搜索实验,发现$k=2,p=6$时效果最好(用FID为指标)。这进一步与WGAN-GP的做法有出入:范数的二次幂并非是最好的选择。
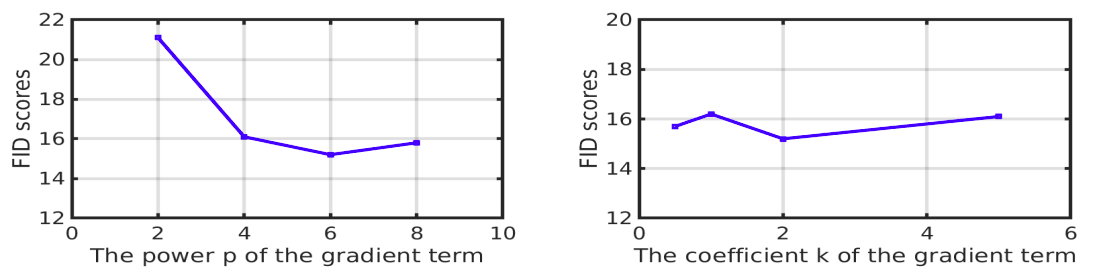
不同的k,p对FID的影响(FID越小越好)
r(x)的选择 #
前面我们就说过,W散度中对$r(x)$的要求非常宽松,论文也做了一组对比实验,对比了常见的做法:
1、真假样本随机插值;
2、真样本之间随机插值、假样本之间随机插值;
3、真假样本混合后,随机选两个样本插值;
4、直接选原始的真假样本混合;
5、直接只选原始的假样本;
6、直接只选原始的真样本。
结果发现,在WGAN-div之下这几种做法表现都差不多(用FID为指标),但是对于WGAN-GP,这几种做法差别比较大,而且WGAN-GP中最好的结果比WGAN-div中最差的结果还要差。这时候WGAN-GP就被彻底虐倒了...
不同的采样方式所导致的不同模型的FID不同差异(FID越小越好)
这里边的差别不难解释,WGAN-GP是凭经验加上梯度惩罚,并且“真假样本随机插值”只是它无法做到全空间采样的一个折衷做法,但是W散度和WGAN-div,从理论的开始,就没对$r(x)$有什么严格的限制。其实,原始W散度的构造(这个需要看参考论文)基本上只要求$r(x)$是一个样本空间跟$\tilde{p}(x)、q(x)$一样的分布,非常弱的要求,而我们一般选择为$\tilde{p}(x)、q(x)$两者共同衍生出来的分布,相对来说收敛快一点。
参考代码 #
自然是用Keras写的~人生苦短,我用Keras
https://github.com/bojone/gan/blob/master/keras/wgan_div_celeba.py
随机样本(自己的实验结果):

WGAN-div的部分样本(2w iter)
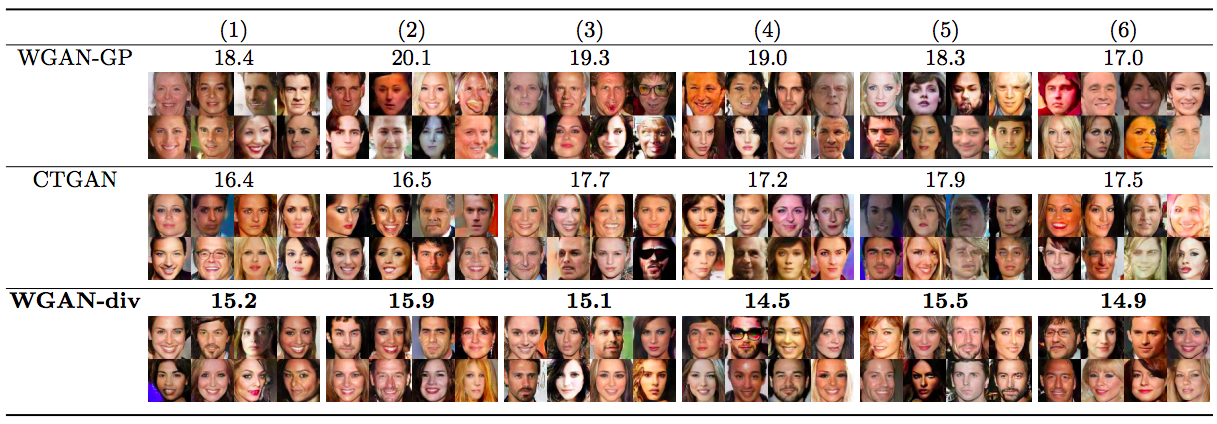
当然,原论文的实验结果也表明WGAN-div是很优秀的:

WGAN-div与不同的模型在不同的数据集效果比较(指标为FID,越小越好)
结语 #
不知道业界是怎么看这篇WGAN-div的,也许是觉得跟WGAN-GP没什么不同,就觉得没有什么意思了。不过我是很佩服这些从理论上推导并且改进原始结果的大牛及其成果。虽然看起来像是随手甩了一篇论文然后说“你看着办吧”的感觉,但这种将理论和实践结合起来的结果仍然是很有美感的。
本来我对WGAN-GP是多少有些芥蒂的,总觉得它太丑,不想用。但是WGAN-div出现了,在我心中已经替代了WGAN-GP,并且它不再丑了~
转载到请包括本文地址:https://kexue.fm/archives/6139
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Nov. 07, 2018). 《WGAN-div:一个默默无闻的WGAN填坑者 》[Blog post]. Retrieved from https://kexue.fm/archives/6139
@online{kexuefm-6139,
title={WGAN-div:一个默默无闻的WGAN填坑者},
author={苏剑林},
year={2018},
month={Nov},
url={\url{https://kexue.fm/archives/6139}},
}

November 7th, 2018
[...]苏剑林. (2018, Nov 07). 《WGAN-div:一个默默无闻的WGAN填坑者 》[Blog post]. Retrieved from https://kexue.fm/archives/6139[...]
November 10th, 2018
小屁林
November 26th, 2018
苏学长,看了你的文章非常精彩!能不能通俗地解释一下什么叫作对偶问题呢?这个词反复在文章中出现了好多次,如果能得到一个浅显易懂的解释就太好了!
对偶问题的含义很广泛。
通常的情况下,是指通过某种变换,将问题A变成问题B,解决了问题B就等于解决了问题A。然后通过同样的变换,问题B又变成了问题A。也就是说A的对偶是B,B的对偶是A。
在GAN中,对偶问题是指将原始定义的散度,通过对偶变换变换成容易采样的的形式。例子请参考:https://kexue.fm/archives/6016
1式到2式是怎么变化的,苏神能否详细说明一下?
这个我也没有简单的理解。
可以参考:https://vincentherrmann.github.io/blog/wasserstein/
December 15th, 2018
文章里提到$W_{k,p}$是对称的散度,这个对称不是对$P$和$Q$而言的吗?论文里似乎是将$T$换成了$-T$,为什么是这样计算呢?
是对$p(x),q(x)$来说对称。
对于原论文,是将散度的定义反号了(也就是论文中的散度,是这里定义的散度的相反数),我不知道原论文为什么这样处理,我觉得不合理,所以改过来了。
January 27th, 2019
刚看WGAN-div,感觉原论文有些问题,请教一下苏神:
1 原文引用WGAN-GP的目标函数(公式6)的头两项(Wasserstein term)的符号是不是反了?
2 按原文的WGAN-div algorithm(Algorithm 1)在cifar10数据集上进行测试,效果非常差(比WGAN-GP差多了),是不是D(x)和D(G(z))的正负号反了。
3 抛开上述的符号问题,感觉WGAN-div和WGAN-GP的差别主要在惩罚项(p,k取值不同和WGAN-GP多了一个“-1"),这些足以构成WGAN-div和WGAN-GP在本质上的差异吗?原文公式8给出一个WGAN-GP的改造,在高分辨率图像生成上效果很好
1、公式6应该不算写反,或者说正写反写都是等价的;
2、我没有实验过,没法提供参考意见;
3、wgan-div和wgan-gp的主要分歧是梯度惩罚究竟是以1为中心还是以0为中心,而相关探讨有很多,比如《Which Training Methods for GANs do actually Converge?》一文已经做过更充分的动力学分析,表明以0为中心是最好的。你说的公式8的第二项(for other datasets),也正是以0为中心的梯度惩罚。
1 查看wgan-gp的原作,如果保持公式6的Wasserstein term的符号,gradient penalty项应该是负而不为正,优化方向是max。
2 公式11居然是求inf,和W-met的sup正好相反,这点比较难以理解,因此就觉得有些违背直觉。没看过文献[19]妄评之。
1、因为你过于“死记硬背”形式了。比如你说公式6,我记$g = -f$,那么不看$f$而看$g$,是不是就是你想要的“原作”的形式了?可是$f$的最后一层一般不加激活函数,那么$f$跟$-f$有啥差别?这不就是说明正写反写都等价了吗,用得着记住原作的形式么~
2、wgan-div论文中,关于“散度”的定义,实际上是我们通常理解的散度的相反数。这一点你看它的附录A就更明白了。它要证明的“散度”是“非正”的,而我们通常定义的散度是非负的。所以它是inf而不是sup。这一点我也觉得该论文的做法很不合理。
多谢指点,把f当成正函数了。
不过,最近把几个代码的wgan-gp替换成div,fid效果不太显著。或者正如《Are GANs Created Equal? A Large-Scale Study》所说的诸多GAN变体并没有像它们声称的那样优于原始GAN,WGAN-GP和WGAN-div通过精调超参数,都能取得相匹敌的效果。这里又有一个想法,f去掉了约束,是否也增大了找到全局(局部)最优的难度?
《Are GANs Created Equal? A Large-Scale Study》的结论基本上没有意义,因为这篇文章是“在收敛的前提下”,各种GAN都效果都差不多。但是各种GAN的困难就是“收敛”、“稳定”,各种先进的GAN的改进都是在“收敛”、“稳定”下功夫,所以,在收敛的大前提下讨论效果是没意义的。
wgan-div最大的好处是在理论上保证了局部收敛性,这是一个非常大的进步。不过这个收敛性的讨论,不在《Wasserstein Divergence for GANs》这篇文章中,而是在《Which Training Methods for GANs do actually Converge?》这篇文章中。
《Are GANs Created Equal? A Large-Scale Study》的意义在于提出或评估一个新的GAN变种,需要在结果的稳健性和超参数的效果进行更认真的研究,而不能仅仅报告最优的结果。性质良好的“divergence”在问题自身复杂性、复杂的网络结构和超参数面前,其理论“收益“还能保持多少,是否已经被抵消得和其他GAN差不多?理论上的完美应该在实证中得到展现才会具有生命力,尤其是在GAN审美疲劳的今天。我想这才是这篇文章写作的初衷和给我们带来的启示。
March 30th, 2019
苏神,请教以下loss有时为负数,这大概是什么原因呢?
GAN的loss是有可能为负的啊~
May 16th, 2019
看了你代码,里面判别器损失函数中的一项
d_loss = K.mean(x_real_score - x_fake_score)
根据你的公式(11),不应该是
d_loss = K.mean(x_real_score) - K.mean(x_fake_score)吗?
这两个难道不相等?
July 9th, 2019
您好,我想问一下将wgan-div应用到语音增强上时,我的模型本来在wgan-gp上表现的很好,但是当我用wgan-div时,p>1的时候,p越大,grad_loss就越快变成很小的数(10的-16次方量级),当0
当0
当p
?
November 27th, 2019
real_grad = K.gradients(x_real_score, [x_real])[0]
fake_grad = K.gradients(x_fake_score, [x_fake])[0]
real_grad_norm = K.sum(real_grad**2, axis=[1, 2, 3])**(p / 2)
fake_grad_norm = K.sum(fake_grad**2, axis=[1, 2, 3])**(p / 2)
grad_loss = K.mean(real_grad_norm + fake_grad_norm) * k / 2
苏神, 这个代码怎么理解啊。小弟刚接触读不懂啊,想把它改成pytorch的,拜托了!!!
就是梯度惩罚呀,你参考wgan-gp的pytorch实现就是了,我也不懂pytorch
||∇T||p 惩罚项的这个是算二范数吗
是的
我看代码里div的损失是加在鉴别器里的,那么它对生成器有影响吗?
所有的梯度惩罚都是加在判别器上的...简单来说,更好的判别器才能指导生成更好的图片。
苏神,grad_loss = K.mean(real_grad_norm + fake_grad_norm) * k / 2最后一项为啥是k/2,而不是k,有啥特别含义吗?
@tayee|comment-15971
应该是想着总的惩罚量级是$k$,然后因为又有真样本又有假样本,所以共有$2k$,因此就除了个2~
December 13th, 2019
再请问一下,我可以把梯度惩罚加在生成器里吗?