






10
Oct
变分自编码器 = 最小化先验分布 + 最大化互信息
By 苏剑林 | 2018-10-10 | 155660位读者 | 引用这篇文章很简短,主要描述的是一个很有用、也不复杂、但是我居然这么久才发现的事实~
在《深度学习的互信息:无监督提取特征》一文中,我们通过先验分布和最大化互信息两个loss的加权组合来得到Deep INFOMAX模型最后的loss。在那篇文章中,虽然把故事讲完了,但是某种意义上来说,那只是个拼凑的loss。而本文则要证明那个loss可以由变分自编码器自然地导出来。
过程
不厌其烦地重复一下,变分自编码器(VAE)需要优化的loss是
\begin{equation}\begin{aligned}&KL(\tilde{p}(x)p(z|x)\Vert q(z)q(x|z))\\
=&\iint \tilde{p}(x)p(z|x)\log \frac{\tilde{p}(x)p(z|x)}{q(x|z)q(z)} dzdx\end{aligned}\end{equation}
相关的论述在本博客已经出现多次了。VAE中既包含编码器,又包含解码器,如果我们只需要编码特征,那么再训练一个解码器就显得很累赘了。所以重点是怎么将解码器去掉。
其实再简单不过了,把VAE的loss分开两部分
29
Sep
f-GAN简介:GAN模型的生产车间
By 苏剑林 | 2018-09-29 | 223134位读者 | 引用今天介绍一篇比较经典的工作,作者命名为f-GAN,他在文章中给出了通过一般的$f$散度来构造一般的GAN的方案。可以毫不夸张地说,这论文就是一个GAN模型的“生产车间”,它一般化的囊括了很多GAN变种,并且可以启发我们快速地构建新的GAN变种(当然有没有价值是另一回事,但理论上是这样)。
局部变分
整篇文章对$f$散度的处理事实上在机器学习中被称为“局部变分方法”,它是一种非常经典且有用的估算技巧。事实上本文将会花大部分篇幅介绍这种估算技巧在$f$散度中的应用结果。至于GAN,只不过是这个结果的基本应用而已。
f散度
首先我们还是对$f$散度进行基本的介绍。所谓$f$散度,是KL散度的一般化:
$$\begin{equation}\mathcal{D}_f(P\Vert Q) = \int q(x) f\left(\frac{p(x)}{q(x)}\right)dx\label{eq:f-div}\end{equation}$$
注意,按照通用的约定写法,括号内是$p/q$而不是$q/p$,大家不要自然而言地根据KL散度的形式以为是$q/p$。
18
Jul
用变分推断统一理解生成模型(VAE、GAN、AAE、ALI)
By 苏剑林 | 2018-07-18 | 457653位读者 | 引用前言:我小学开始就喜欢纯数学,后来也喜欢上物理,还学习过一段时间的理论物理,直到本科毕业时,我才慢慢进入机器学习领域。所以,哪怕在机器学习领域中,我的研究习惯还保留着数学和物理的风格:企图从最少的原理出发,理解、推导尽可能多的东西。这篇文章是我这个理念的结果之一,试图以变分推断作为出发点,来统一地理解深度学习中的各种模型,尤其是各种让人眼花缭乱的GAN。本文已经挂到arxiv上,需要读英文原稿的可以移步到《Variational Inference: A Unified Framework of Generative Models and Some Revelations》。
下面是文章的介绍。其实,中文版的信息可能还比英文版要稍微丰富一些,原谅我这蹩脚的英语...
摘要:本文从一种新的视角阐述了变分推断,并证明了EM算法、VAE、GAN、AAE、ALI(BiGAN)都可以作为变分推断的某个特例。其中,论文也表明了标准的GAN的优化目标是不完备的,这可以解释为什么GAN的训练需要谨慎地选择各个超参数。最后,文中给出了一个可以改善这种不完备性的正则项,实验表明该正则项能增强GAN训练的稳定性。
近年来,深度生成模型,尤其是GAN,取得了巨大的成功。现在我们已经可以找到数十个乃至上百个GAN的变种。然而,其中的大部分都是凭着经验改进的,鲜有比较完备的理论指导。
本文的目标是通过变分推断来给这些生成模型建立一个统一的框架。首先,本文先介绍了变分推断的一个新形式,这个新形式其实在博客以前的文章中就已经介绍过,它可以让我们在几行字之内导出变分自编码器(VAE)和EM算法。然后,利用这个新形式,我们能直接导出GAN,并且发现标准GAN的loss实则是不完备的,缺少了一个正则项。如果没有这个正则项,我们就需要谨慎地调整超参数,才能使得模型收敛。
18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 1380252位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量$Z$生成目标数据$X$的模型,但是实现上有所不同。更准确地讲,它们是假设了$Z$服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型$X=g(Z)$,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
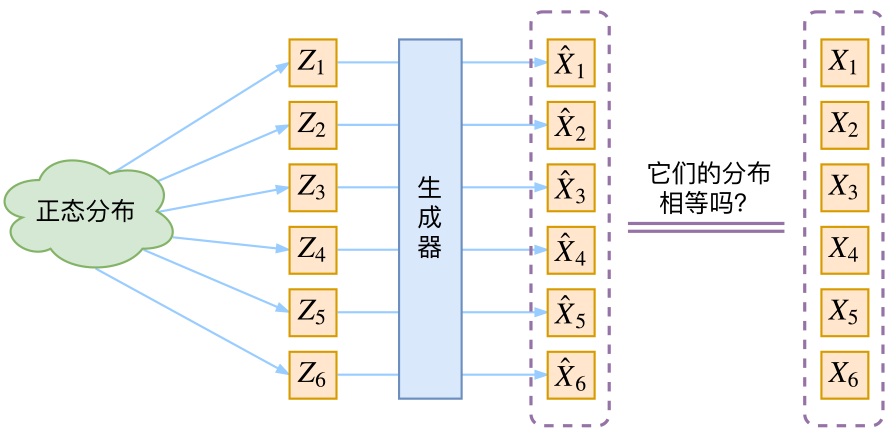
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
ODE的坐标变换
熟悉理论力学的读者应该能够领略到变分法在变换坐标系中的作用。比如,如果要将下面的平面二体问题方程
$$\left\{\begin{aligned}\frac{d^2 x}{dt^t}=\frac{-\mu x}{(x^2+y^2)^{3/2}}\\
\frac{d^2 y}{dt^t}=\frac{-\mu y}{(x^2+y^2)^{3/2}}\end{aligned}\right.\tag{1}$$
变换到极坐标系下,如果直接代入计算,将会是一道十分繁琐的计算题。但是,我们知道,上述方程只不过是作用量
$$S=\int \left[\frac{1}{2}\left(\dot{x}^2+\dot{y}^2\right)+\frac{\mu}{\sqrt{x^2+y^2}}\right]dt\tag{2}$$
变分之后的拉格朗日方程,那么我们就可以直接对作用量进行坐标变换。而由于作用量一般只涉及到了一阶导数,因此作用量的变换一般来说比较简单。比如,很容易写出,$(2)$在极坐标下的形式为
$$S=\int \left[\frac{1}{2}\left(\dot{r}^2+r^2\dot{\theta}^2\right)+\frac{\mu}{r}\right]dt\tag{3}$$
对$(3)$进行变分,得到的拉格朗日方程为
$$\left\{\begin{aligned}&\ddot{r}=r\dot{\theta}^2-\frac{\mu}{r^2}\\
&\frac{d}{dt}\left(r^2\dot{\theta}\right)=0\end{aligned}\right.\tag{4}$$
就这样完成了坐标系的变换。如果想直接代入$(1)$暴力计算,那么请参考《方程与宇宙》:二体问题的来来去去(一)
15
Nov
力学系统及其对偶性(三)
By 苏剑林 | 2013-11-15 | 20935位读者 | 引用在上一篇文章中,我已经初步地从最小作用量原理的角度来观察对偶定律的表现。虽然那是一种便捷有效的方法,但是还是给我们流下了一些遗憾。上一节是从几何形式的作用量原理出发的,而没有在一般形式的作用量框架下讨论。因为如果在$S=\int Ldt=\int (T-U)dt$的形式下讨论坐标变换问题会出现困难,困难源于我们进行了变换$d\tau=|z|^2 dt$,这导致了时间和空间的耦合,变分不能简单地进行。但是,这并非无法解决的问题。我们还是可以在基本的作用量原理之下讨论变换问题。下面将对此问题进行讨论。
变分中的变量代换
考虑一个一般的保守系统的作用量:
$$S=\int_{t_1}^{t_2} L(q,\frac{dq}{dt})dt$$
本文我们来探讨下列积分的极值曲线:
$$S=\int f(x,y)\sqrt{dx^2+dy^2}=\int f(x,y)ds$$
这本质上也是一个短程线问题。但是它形式比较简答,物理含义也更加明显。比如,如果$f(x,y)$是势函数的话,那么这就是一个求势能最小的二维问题;如果$f(x,y)$是摩擦力函数,那么这就是寻找摩擦力最小的路径问题。不管是哪一种,该问题都有相当的实用价值。下面将其变分:
$$\begin{aligned} \delta S =&\int \delta[f(x,y)\sqrt{dx^2+dy^2}] \\ =&\int [ds\delta f(x,y)+f(x,y)\frac{\delta (dx^2+dy^2)}{2ds}]\\ =&\int ds(\frac{\partial f}{\partial x}\delta x+\frac{\partial}{\partial y}\delta y)+f \frac{dx d(\delta x)+dy d(\delta y)}{ds} \\=&\int ds(\frac{\partial f}{\partial x}\delta x+\frac{\partial}{\partial y}\delta y)+f \frac{dx}{ds} d(\delta x)+\frac{dy}{ds} d(\delta y) \end{aligned}$$
30
Jul
变分法的一个技巧及其“误用”
By 苏剑林 | 2013-07-30 | 46367位读者 | 引用不可否认,变分法是非常有用而绝妙的一个数学工具,它“自动地”为我们在众多函数中选出了最优的一个,而免除了具体的分析过程。物理中的最小作用量原理则让变分法有了巨大的用武之地,并反过来也推动了变分法的发展。但是变分法的一个很明显的特点就是在大多数情况下计算相当复杂,甚至如果“蛮干”的话我们几乎连微分方程组都列不出来。因此,一些有用的技巧是很受欢迎的。本文就打算介绍这样的一个小技巧,来让某些变分问题得到一定的化简。
我是怎么得到这个技巧的呢?事实上,那是几个月前我在阅读《引力与时空》时,读到变分原理那一块时我怎么也读不懂,想不明白。明明我觉得是错误的东西,为什么可以得到正确的结果?我的数学直觉告诉我绝对是作者的错,可是我又想不出作者哪里错了,所以就一直把这个问题搁置着。最近我终于得到了自己比较满意的答案,并且窃认为是本文所要讲的这个技巧却被物理学家“误用”了。
技巧
首先来看通常我们是怎么处理变分问题的,以一元函数为例,对于求
$$S=\int L(x,\dot{x},t)dt$$

最近评论