






29
Mar
【备忘】电脑远程控制手机的解决方案
By 苏剑林 | 2016-03-29 | 47556位读者 | 引用最近由于数据挖掘上的研究,需要想办法通过电脑远程控制手机(主要是安卓),遂查找了网络上的一些工具,这里记录一下结果,纯粹做备忘。有同样需要的读者可以参考。
之前在阿里云的服务器和树莓派上都做过远程控制的,记得Linux下的远程控制工具叫做VNC,于是我google和百度了vnc server android、vnc server apk等,发现这类工具确实不少,比如最知名的当属droid vnc server。但是同类的几个软件我都测试了,它确实是VNC软件,但是在我的几个安卓4.x上,显示都不正常(花屏),无奈抛弃了。再看一下日期,发现原来这些软件基本到2013年就停止更新了,一般支持到安卓2.3而已,怪不得。
15
Apr
斯特灵(stirling)公式与渐近级数
By 苏剑林 | 2016-04-15 | 59859位读者 | 引用斯特灵近似,或者称斯特灵公式,最开始是作为阶乘的近似提出
$$n!\sim \sqrt{2\pi n}\left(\frac{n}{e}\right)^n$$
符号$\sim$意味着
$$\lim_{n\to\infty}\frac{\sqrt{2\pi n}\left(\frac{n}{e}\right)^n}{n!}=1$$
将斯特灵公式进一步提高精度,就得到所谓的斯特灵级数
$$n!=\sqrt{2\pi n}\left(\frac{n}{e}\right)^n\left(1+\frac{1}{12n}+\frac{1}{288n^2}\dots\right)$$
很遗憾,这个是渐近级数。
相关资料有:
https://zh.wikipedia.org/zh-cn/斯特灵公式
https://en.wikipedia.org/wiki/Stirling%27s_approximation
本文将会谈到斯特灵公式及其渐近级数的一个改进的推导,并解释渐近级数为什么渐近。
30
May
路径积分系列:1.我的毕业论文
By 苏剑林 | 2016-05-30 | 28502位读者 | 引用之前承诺过会把毕业论文共享出来,让大家批评指正,却一直偷懒没动。事实上,毕业论文的主要内容就是路径积分的一些入门级别的内容,标题为《随机游走、随机微分方程与偏微分方程的路径积分方法》。我的摘要是这样写的:
本文从随机游走模型出发,得到了关于随机游走模型的一般结果;然后基于随机游走模型引入了路径积分,并且通过路径积分方法,实现了随机游走、随机微分方程与抛物型微分方程的相互转化,并给出了一些计算案例.
路径积分方法是量子理论的一种形式,但实际上它可以抽象为一个有用的数学工具,本文的主要方法正是抽象后的路径积分;其次,量子力学中有一个相当典型的抛物型偏微分方程——薛定谔方程,物理学家已经对它进行了大量的研究,有众多的成果;而随机微分方程是一个微分方程的拓展,在物理、工程、金融等很多方面都有重要应用,这个领域中也有很多研究方法;最后,随机游走是一个简单而重要的模型,它是很多扩散模型的基础,而且具有容易使用计算机模拟的特性. 因此,实现三者的转化是很有意义的.
本文有一些新的内容,比如现有文献比较少研究的不对称随机游走方面、以及现有文献比较含糊的对路径积分的介绍等,可以供同好参考,希望借此方式,能够让一些读者以更简洁明了的方式理解路径积分. 但是本文主要是陈述性的,旨在在国内推广路径积分方法. 在国外,路径积分方法得到了相当的重视,它源于量子力学,但应用已经不仅仅限于量子力学,如著作[1],因此,推广路径积分方法、增加路径积分的中文资料,是很有意义和很有必要的事情.
本文所有推导和例子均以一维为例,相应的多维问题可以类似地计算。
17
Jun
OCR技术浅探:2. 背景与假设
By 苏剑林 | 2016-06-17 | 38444位读者 | 引用研究背景
关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不少成熟的OCR技术和产品产生,比如汉王OCR、ABBYY FineReader、Tesseract OCR等. 值得一提的是,ABBYY FineReader不仅正确率高(包括对中文的识别),而且还能保留大部分的排版效果,是一个非常强大的OCR商业软件.
然而,在诸多的OCR成品中,除了Tesseract OCR外,其他的都是闭源的、甚至是商业的软件,我们既无法将它们嵌入到我们自己的程序中,也无法对其进行改进. 开源的唯一选择是Google的Tesseract OCR,但它的识别效果不算很好,而且中文识别正确率偏低,有待进一步改进.
综上所述,不管是为了学术研究还是实际应用,都有必要对OCR技术进行探究和改进. 我们队伍将完整的OCR系统分为“特征提取”、“文字定位”、“光学识别”、“语言模型”四个方面,逐步进行解决,最终完成了一个可用的、完整的、用于印刷文字的OCR系统. 该系统可以初步用于电商、微信等平台的图片文字识别,以判断上面信息的真伪.
研究假设
在本文中,我们假设图像的文字部分有以下的特征:
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 55979位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
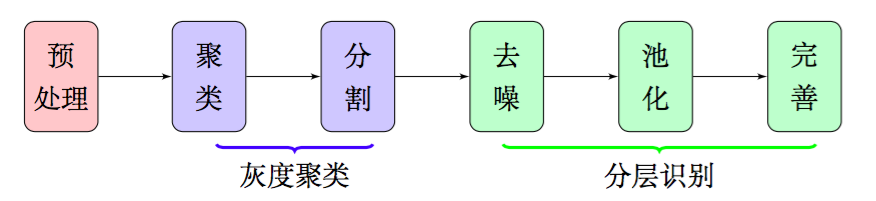
图2:特征提取大概流程
29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 408740位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
26
Jun
OCR技术浅探:9. 代码共享(完)
By 苏剑林 | 2016-06-26 | 68662位读者 | 引用
13
Aug
两个惊艳的python库:tqdm和retry
By 苏剑林 | 2016-08-13 | 66472位读者 | 引用Python基本是我目前工作、计算、数据挖掘的唯一编程语言(除了符号计算用Mathematica外)。当然,基本的Python功能并不是很强大,但它胜在有巨量的第三方扩展库。在选用Python的第三方库时,我都会经过仔细考虑,希望能挑选出最简单的、最直观的一个(因为本人比较笨,太复杂用不了)。在数据处理方面,我用得最多的是Numpy和Pandas,这两个绝对称得上王者级别的库,当然不能不提的是Scipy,但我很少直接用它,一般会通过Pandas间接调用了;可视化方面不用说是Matplotlib了;在建模方面,我会用Keras,直接上深度学习模型,Keras已经成为相当流行的深度学习框架了,如果做文本挖掘,通常还会用到jieba(分词)、Gensim(主题建模,包含了诸如word2vec之类的模型),机器学习库还有流行的Scikit Learn,但我很少用;网络方面,写爬虫我用requests,这是个人性化的网络库,如果写网站,我会用bottle,这是个单文件版的迷你框架,一切由自己定义,当然,我也不会去写什么大型网站,我就写一个简单的的接口那样而已;最后如果要并行的话,一般直接用multiprocessing。
不过,以上都不是本文要推荐的,本文要推荐的是两个可以渗透到日常写代码的库,它实现了我们平时很多时候都需要的功能,但是不用增加什么代码,绝对让人眼前一亮。

最近评论