






8
Aug
【备忘】谈谈dropout
By 苏剑林 | 2017-08-08 | 35393位读者 | 引用其实这只是一篇备忘...
dropout是深度学习中防止过拟合的一项有效措施,当然,就其思想而言,dropout其实也不仅仅可以用在深度学习中,还可以用在传统的机器学习方法中,只不过在深度学习的神经网络框架下,dropout显得更为自然罢了。
做了什么
dropout是怎么操作的?一般来做,对于输入的张量$x$,dropout就是将部分元素置零,然后将置零后的结果做一个尺度变换。具体来说,以Keras的Dropout(0.6)(x)为例,实际上等价于numpy做的这件事情
import numpy as np
x = np.random.random((10,100)) #模拟一个batch_size=10、维度为100的输入
def Dropout(x, drop_proba):
return x*np.random.choice(
[0,1],
x.shape,
p=[drop_proba,1-drop_proba]
)/(1.-drop_proba)
print Dropout(x, 0.6)
29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 78924位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
1
Jul
又是Dropout两次!这次它做到了有监督任务的SOTA
By 苏剑林 | 2021-07-01 | 225994位读者 | 引用关注NLP新进展的读者,想必对四月份发布的SimCSE印象颇深,它通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA。无独有偶,最近的论文《R-Drop: Regularized Dropout for Neural Networks》提出了R-Drop,它将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升。此外,笔者在自己的实验还发现,它在半监督任务上也能有不俗的表现。
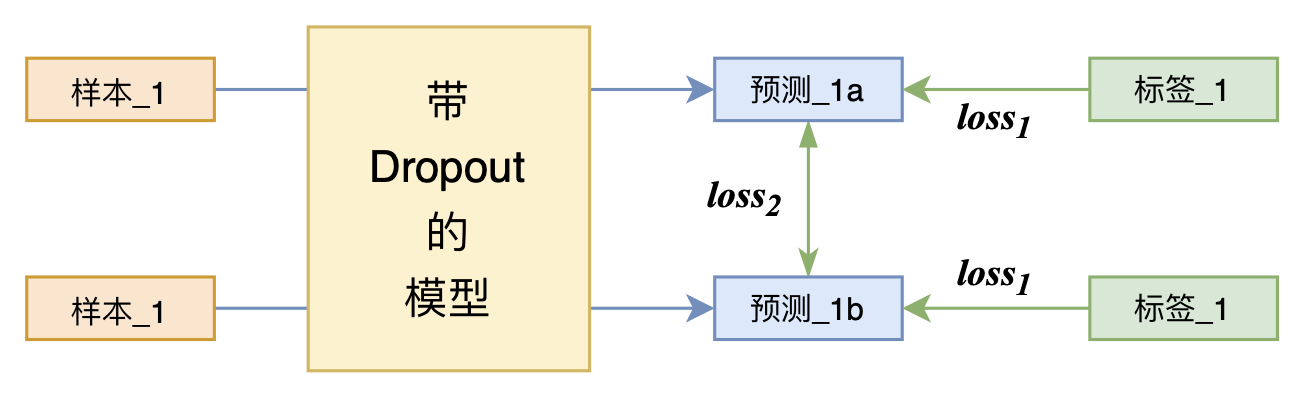
R-Drop示意图
小小的“Dropout两次”,居然跑出了“五项全能”的感觉,不得不令人惊讶。本文来介绍一下R-Drop,并分享一下笔者对它背后原理的思考。
22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 69172位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。
8
Jul
百科翻译:氢氧化钠(NaOH)的详细介绍
By 苏剑林 | 2009-07-08 | 67729位读者 | 引用对于我们来说,维基百科是一个难得的资料库,但是与其英文版相比,中文版就相形见绌了,就好像本文中所讲的氢氧化钠,在中文版的资料为http://zh.wikipedia.org/w/index.php?title=NaOH&variant=zh-cn;而在英文版的资料为http://en.wikipedia.org/wiki/NaOH 可见英文版本是多么丰富。为了使大家能够更多地了解到科学,笔者特地翻译了一些英文版的维基百科中一些资料。

8
Jul
百科翻译:盐酸的历史(氯化氢,HCl)
By 苏剑林 | 2009-07-08 | 38473位读者 | 引用
9
Jul
天文马拉松:观测国际空间站
By 苏剑林 | 2009-07-09 | 24261位读者 | 引用
9
Jul


最近评论