






10
Jun
【翻译】巨型望远镜:要继续,就得有牺牲!
By 苏剑林 | 2015-06-10 | 28194位读者 | 引用
2007年末公布的30米望远镜效果图
文章来自:新科学家,这是一篇关于30米望远镜(Thirty Meter Telescope,TMT)的新闻,起因是望远镜的制造遭到当地人的不满,当然背后的原因是很深远的,难以说清楚。更多有关TMT的新闻,可以阅读:http://www.ctmt.org/
夏威夷的巨型望远镜:要继续,就得有牺牲!
四分之一必须离开!在停止了两个月之后,夏威夷的巨型30米望远镜(Thirty Meter Telescope,TMT)重新回归到建设进程——但要牺牲其他望远镜。
由于夏威夷当地居民的抗议声越来越大,早在四月望远镜的建设工作就被迫暂停。与该望远镜相比,目前世界上所有的望远镜都相形见绌——它让能够让天文学家们凝视可见的宇宙的边缘。它位于许多夏威夷人认为是“神圣之地”的死火山莫纳克亚山,因此被夏威夷人认为是一种侮辱——尤其是在山顶已经有十多个望远镜了。
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 233640位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
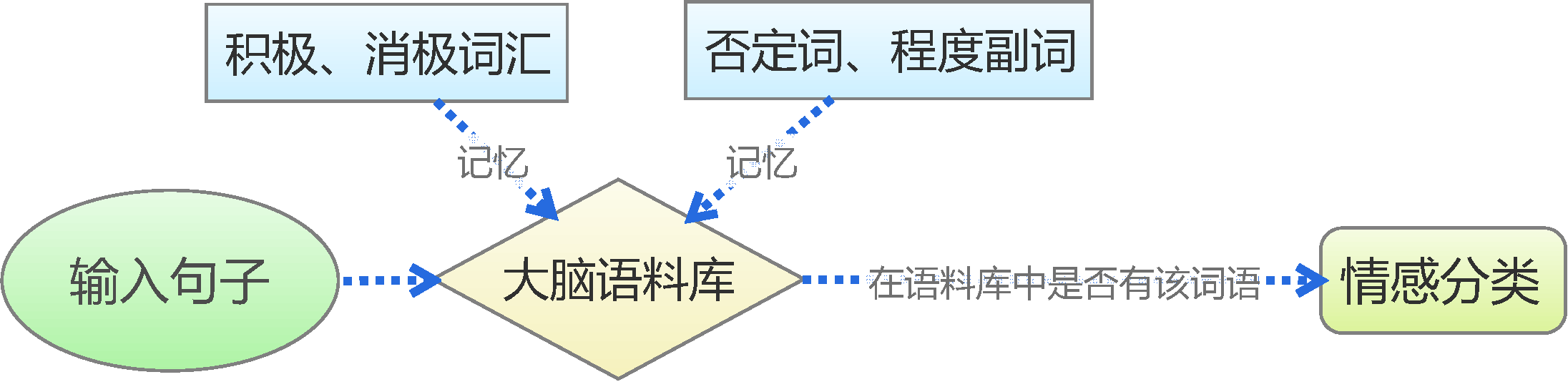
人的最简单的判断思维
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 624910位读者 | 引用
最近一直在考虑一些自然语言处理问题和一些非线性分析问题,无暇总结发文,在此表示抱歉。本文要说的是对于一阶非线性差分方程(当然高阶也可以类似地做)的一种摄动格式,理论上来说,本方法可以得到任意一阶非线性差分方程的显式渐近解。
非线性差分方程
对于一般的一阶非线性差分方程
$$\begin{equation}\label{chafenfangcheng}x_{n+1}-x_n = f(x_n)\end{equation}$$
通常来说,差分方程很少有解析解,因此要通过渐近分析等手段来分析非线性差分方程的性质。很多时候,我们首先会考虑将差分替换为求导,得到微分方程
$$\begin{equation}\label{weifenfangcheng}\frac{dx}{dn}=f(x)\end{equation}$$
作为差分方程$\eqref{chafenfangcheng}$的近似。其中的原因,除了微分方程有比较简单的显式解之外,另一重要原因是微分方程$\eqref{weifenfangcheng}$近似保留了差分方程$\eqref{chafenfangcheng}$的一些比较重要的性质,如渐近性。例如,考虑离散的阻滞增长模型:
$$\begin{equation}\label{zuzhizengzhang}x_{n+1}=(1+\alpha)x_n -\beta x_n^2\end{equation}$$
对应的微分方程为(差分替换为求导):
$$\begin{equation}\frac{dx}{dn}=\alpha x -\beta x^2\end{equation}$$
此方程解得
$$\begin{equation}x_n = \frac{\alpha}{\beta+c e^{-\alpha n}}\end{equation}$$
其中$c$是任意常数。上述结果已经大概给出了原差分方程$\eqref{zuzhizengzhang}$的解的变化趋势,并且成功给出了最终的渐近极限$x_n \to \frac{\alpha}{\beta}$。下图是当$\alpha=\beta=1$且$c=1$(即$x_0=\frac{1}{2}$)时,微分方程的解与差分方程的解的值比较。
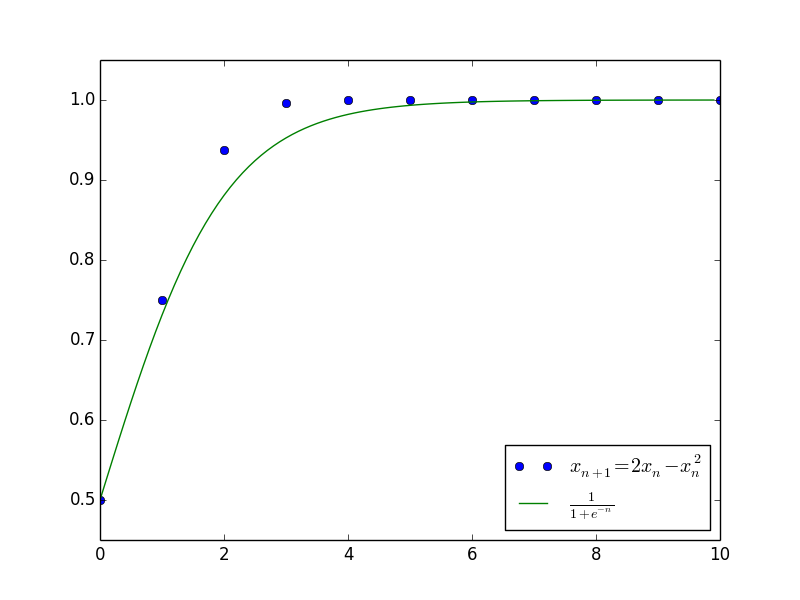
差分方程的摄动法1
现在的问题是,既然微分方程的解可以作为一个形态良好的近似解了,那么是否可以在微分方程的解的基础上,进一步加入修正项提高精度?
7
Feb
年三十折腾极路由之SSH反向代理
By 苏剑林 | 2016-02-07 | 62799位读者 | 引用
猴年快乐!
今天是年三十了,这里简单祝大家除夕快乐,新年快乐!愿大家在新的一年里都晋升为学神。^_^
这两天主要在折腾家里的路由器。平时家里只有爸妈两人,所以为了节省,家里只是通过中继隔壁家的网络来上网。本来家里用小米路由器mini,可是小米mini中继模式下功能限制非常多,我又不想刷第三方固件(因为这样会失去app控制功能,不是很方便),所以干脆换了个极路由3。极路由在中继模式下仍然保留了大部分功能(我觉得这样才是正常的,我不理解小米mini在中继之后就没了那么多功能究竟是什么逻辑)。
作为折腾派,一个新路由到手,总有很多东西要配置,极路由本身是基于openwrt的,因此可玩性也很强。首先要完成中继,然后上网,这个很简单就不多说了。其次是获得ssh权限,在极路由那里叫做“申请开发者模式”,或者叫root(感觉极路由想做路由界的苹果,但是在如今这个时代,苹果当初那种发展模式估计很难发展起来了),这个步骤也不难,不过申请之后就会失去极路由的保修资格(不理解这是什么逻辑)。
本文主要介绍了怎么在openwrt(极路由)上安装python,以及建立SSH反向代理(实现内网穿透)。
17
Jun
OCR技术浅探:1. 全文简述
By 苏剑林 | 2016-06-17 | 45722位读者 | 引用写在前面:前面的博文已经提过,在上个月我参加了第四届泰迪杯数据挖掘竞赛,做的是A题,跟OCR系统有些联系,还承诺过会把最终的结果开源。最近忙于毕业、搬东西,一直没空整理这些内容,现在抽空整理一下。
把结果发出来,并不是因为结果有多厉害、多先进(相反,当我对比了百度的这篇论文《基于深度学习的图像识别进展:百度的若干实践》之后,才发现论文的内容本质上还是传统那一套,远远还跟不上时代的潮流),而是因为虽然OCR技术可以说比较成熟了,但网络上根本就没有对OCR系统进行较为详细讲解的文章,而本文就权当补充这部分内容吧。我一直认为,技术应该要开源才能得到发展(当然,在中国这一点也确实值得商榷,因为开源很容易造成山寨),不管是数学物理研究还是数据挖掘,我大多数都会发表到博客中,与大家交流。
29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 426433位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
22
Aug
【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
By 苏剑林 | 2016-08-22 | 482698位读者 | 引用关于字标注法
上一篇文章谈到了分词的字标注法。要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了。在我看来,字标注法有效有两个主要的原因,第一个原因是它将分词问题变成了一个序列标注问题,而且这个标注是对齐的,也就是输入的字跟输出的标签是一一对应的,这在序列标注中是一个比较成熟的问题;第二个原因是这个标注法实际上已经是一个总结语义规律的过程,以4tag标注为为例,我们知道,“李”字是常用的姓氏,一半作为多字词(人名)的首字,即标记为b;而“想”由于“理想”之类的词语,也有比较高的比例标记为e,这样一来,要是“李想”两字放在一起时,即便原来词表没有“李想”一词,我们也能正确输出be,也就是识别出“李想”为一个词,也正是因为这个原因,即便是常被视为最不精确的HMM模型也能起到不错的效果。
关于标注,还有一个值得讨论的内容,就是标注的数目。常用的是4tag,事实上还有6tag和2tag,而标记分词结果最简单的方法应该是2tag,即标记“切分/不切分”就够了,但效果不好。为什么反而更多数目的tag效果更好呢?因为更多的tag实际上更全面概括了语义规律。比如,用4tag标注,我们能总结出哪些字单字成词、哪些字经常用作开头、哪些字用作末尾,但仅仅用2tag,就只能总结出哪些字经常用作开头,从归纳的角度来看,是不够全面的。但6tag跟4tag比较呢?我觉得不一定更好,6tag的意思是还要总结出哪些字作第二字、第三字,但这个总结角度是不是对的?我觉得,似乎并没有哪些字固定用于第二字或者第三字的,这个规律的总结性比首字和末字的规律弱多了(不过从新词发现的角度来看,6tag更容易发现长词。)。

最近评论