






22
Aug
【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
By 苏剑林 | 2016-08-22 | 591285位读者 |关于字标注法 #
上一篇文章谈到了分词的字标注法。要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了。在我看来,字标注法有效有两个主要的原因,第一个原因是它将分词问题变成了一个序列标注问题,而且这个标注是对齐的,也就是输入的字跟输出的标签是一一对应的,这在序列标注中是一个比较成熟的问题;第二个原因是这个标注法实际上已经是一个总结语义规律的过程,以4tag标注为为例,我们知道,“李”字是常用的姓氏,一半作为多字词(人名)的首字,即标记为b;而“想”由于“理想”之类的词语,也有比较高的比例标记为e,这样一来,要是“李想”两字放在一起时,即便原来词表没有“李想”一词,我们也能正确输出be,也就是识别出“李想”为一个词,也正是因为这个原因,即便是常被视为最不精确的HMM模型也能起到不错的效果。
关于标注,还有一个值得讨论的内容,就是标注的数目。常用的是4tag,事实上还有6tag和2tag,而标记分词结果最简单的方法应该是2tag,即标记“切分/不切分”就够了,但效果不好。为什么反而更多数目的tag效果更好呢?因为更多的tag实际上更全面概括了语义规律。比如,用4tag标注,我们能总结出哪些字单字成词、哪些字经常用作开头、哪些字用作末尾,但仅仅用2tag,就只能总结出哪些字经常用作开头,从归纳的角度来看,是不够全面的。但6tag跟4tag比较呢?我觉得不一定更好,6tag的意思是还要总结出哪些字作第二字、第三字,但这个总结角度是不是对的?我觉得,似乎并没有哪些字固定用于第二字或者第三字的,这个规律的总结性比首字和末字的规律弱多了(不过从新词发现的角度来看,6tag更容易发现长词。)。
双向LSTM #
关于双向LSTM,理解的思路是:双向LSTM是LSTM的改进版,LSTM是RNN的改进版。因此,首先需要理解RNN。
笔者曾在拙作《从Boosting学习到神经网络:看山是山?》说到过,模型的输出结果,事实上也是一种特征,也可以作为模型的输入来用,RNN正是这样的网络结构。普通的多层神经网络,是一个输入到输出的单向传播过程。如果涉及到高维输入,也可以这样做,但节点太多,不容易训练,也容易过拟合。比如图像输入是1000x1000的,难以直接处理,这就有了CNN;又或者1000词的句子,每个词用100维的词向量,那么输入维度也不小,这时候,解决这个问题的一个方案是RNN(CNN也可以用,但RNN更适合用于序列问题。)。
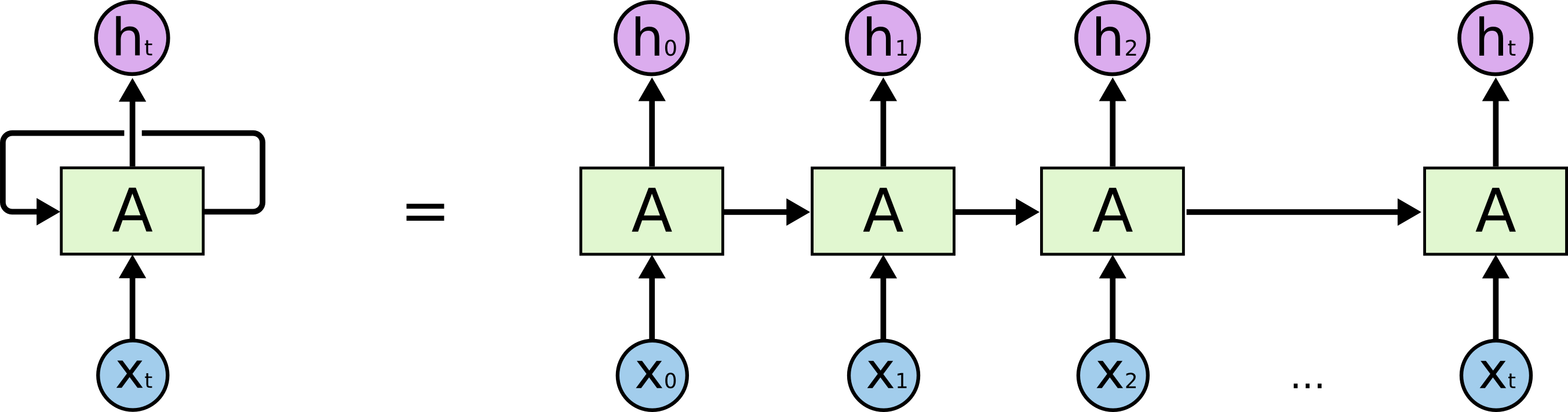
RNN的过程
RNN的意思是,为了预测最后的结果,我先用第一个词预测,当然,只用第一个预测的预测结果肯定不精确,我把这个结果作为特征,跟第二词一起,来预测结果;接着,我用这个新的预测结果结合第三词,来作新的预测;然后重复这个过程;直到最后一个词。这样,如果输入有n个词,那么我们事实上对结果作了n次预测,给出了n个预测序列。整个过程中,模型共享一组参数。因此,RNN降低了模型的参数数目,防止了过拟合,同时,它生来就是为处理序列问题而设计的,因此,特别适合处理序列问题。
LSTM对RNN做了改进,使得能够捕捉更长距离的信息。但是不管是LSTM还是RNN,都有一个问题,它是从左往右推进的,因此后面的词会比前面的词更重要,但是对于分词这个任务来说是不妥的,因为句子各个字应该是平权的。因此出现了双向LSTM,它从左到右做一次LSTM,然后从右到左做一次LSTM,然后把两次结果组合起来。
在分词任务中的应用 #
关于深度学习与分词,很早就有人尝试过了,比如下列文章:
http://blog.csdn.net/itplus/article/details/13616045
https://github.com/xccds/chinese_wordseg_keras
http://www.leiphone.com/news/201608/IWvc75oJglAIsDvJ.html
这些文章中,不管是用简单的神经网络还是LSTM,它们的做法都跟传统模型是一样的,都是通过上下文来预测当前字的标签,这里的上下文是固定窗口的,比如用前后5个字加上当前字来预测当前字的标签。这种做法没有什么不妥之处,但仅仅是把以往估计概率的方法,如HMM、ME、CRF等,换为了神经网络而已,整个框架是没变的,本质上还是n-gram模型。而有了LSTM,LSTM本身可以做序列到序列(seq2seq)的输出,因此,为什么不直接输出原始句子的序列呢?这样不就真正利用了全文信息了吗?这就是本文的尝试。
LSTM可以根据输入序列输出一个序列,这个序列考虑了上下文的联系,因此,可以给每个输出序列接一个softmax分类器,来预测每个标签的概率。基于这个序列到序列的思路,我们就可以直接预测句子的标签。
Keras实现 #
事不宜迟,动手最重要。词向量维度用了128,句子长度截断为32(抛弃了多于32字的样本,这部分样本很少,事实上,用逗号、句号等天然分隔符分开后,句子很少有多于32字的。)。这次我用了5tag,在原来的4tag的基础上,加上了一个x标签,用来表示不够32字的部分,比如句子是20字的,那么第21~32个标签均为x。
在数据方面,我用了Bakeoff 2005的语料中微软亚洲研究院(Microsoft Research)提供的部分。代码如下,如果有什么不清晰的地方,欢迎留言。
# -*- coding:utf-8 -*-
import re
import numpy as np
import pandas as pd
s = open('msr_train.txt').read().decode('gbk')
s = s.split('\r\n')
def clean(s): #整理一下数据,有些不规范的地方
if u'“/s' not in s:
return s.replace(u' ”/s', '')
elif u'”/s' not in s:
return s.replace(u'“/s ', '')
elif u'‘/s' not in s:
return s.replace(u' ’/s', '')
elif u'’/s' not in s:
return s.replace(u'‘/s ', '')
else:
return s
s = u''.join(map(clean, s))
s = re.split(u'[,。!?、]/[bems]', s)
data = [] #生成训练样本
label = []
def get_xy(s):
s = re.findall('(.)/(.)', s)
if s:
s = np.array(s)
return list(s[:,0]), list(s[:,1])
for i in s:
x = get_xy(i)
if x:
data.append(x[0])
label.append(x[1])
d = pd.DataFrame(index=range(len(data)))
d['data'] = data
d['label'] = label
d = d[d['data'].apply(len) <= maxlen]
d.index = range(len(d))
tag = pd.Series({'s':0, 'b':1, 'm':2, 'e':3, 'x':4})
chars = [] #统计所有字,跟每个字编号
for i in data:
chars.extend(i)
chars = pd.Series(chars).value_counts()
chars[:] = range(1, len(chars)+1)
#生成适合模型输入的格式
from keras.utils import np_utils
d['x'] = d['data'].apply(lambda x: np.array(list(chars[x])+[0]*(maxlen-len(x))))
def trans_one(x):
_ = map(lambda y: np_utils.to_categorical(y,5), tag[x].reshape((-1,1)))
_ = list(_)
_.extend([np.array([[0,0,0,0,1]])]*(maxlen-len(x)))
return np.array(_)
d['y'] = d['label'].apply(trans_one)
#设计模型
word_size = 128
maxlen = 32
from keras.layers import Dense, Embedding, LSTM, TimeDistributed, Input, Bidirectional
from keras.models import Model
sequence = Input(shape=(maxlen,), dtype='int32')
embedded = Embedding(len(chars)+1, word_size, input_length=maxlen, mask_zero=True)(sequence)
blstm = Bidirectional(LSTM(64, return_sequences=True), merge_mode='sum')(embedded)
output = TimeDistributed(Dense(5, activation='softmax'))(blstm)
model = Model(input=sequence, output=output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
batch_size = 1024
history = model.fit(np.array(list(d['x'])), np.array(list(d['y'])).reshape((-1,maxlen,5)), batch_size=batch_size, nb_epoch=50)
#转移概率,单纯用了等概率
zy = {'be':0.5,
'bm':0.5,
'eb':0.5,
'es':0.5,
'me':0.5,
'mm':0.5,
'sb':0.5,
'ss':0.5
}
zy = {i:np.log(zy[i]) for i in zy.keys()}
def viterbi(nodes):
paths = {'b':nodes[0]['b'], 's':nodes[0]['s']}
for l in range(1,len(nodes)):
paths_ = paths.copy()
paths = {}
for i in nodes[l].keys():
nows = {}
for j in paths_.keys():
if j[-1]+i in zy.keys():
nows[j+i]= paths_[j]+nodes[l][i]+zy[j[-1]+i]
k = np.argmax(nows.values())
paths[nows.keys()[k]] = nows.values()[k]
return paths.keys()[np.argmax(paths.values())]
def simple_cut(s):
if s:
r = model.predict(np.array([list(chars[list(s)].fillna(0).astype(int))+[0]*(maxlen-len(s))]), verbose=False)[0][:len(s)]
r = np.log(r)
nodes = [dict(zip(['s','b','m','e'], i[:4])) for i in r]
t = viterbi(nodes)
words = []
for i in range(len(s)):
if t[i] in ['s', 'b']:
words.append(s[i])
else:
words[-1] += s[i]
return words
else:
return []
not_cuts = re.compile(u'([\da-zA-Z ]+)|[。,、?!\.\?,!]')
def cut_word(s):
result = []
j = 0
for i in not_cuts.finditer(s):
result.extend(simple_cut(s[j:i.start()]))
result.append(s[i.start():i.end()])
j = i.end()
result.extend(simple_cut(s[j:]))
return result
我们可以用model.summary()看一下模型的结构。
>>> model.summary()
_______________________________________________________
Layer (type) Output Shape Param # Connected to
=======================================================
input_2 (InputLayer) (None, 32) 0
_______________________________________________________
embedding_2 (Embedding) (None, 32, 128) 660864 input_2[0][0]
_______________________________________________________
bidirectional_1 (Bidirectional) (None, 32, 64) 98816 embedding_2[0][0]
_______________________________________________________
timedistributed_2 (TimeDistribute) (None, 32, 5) 325 bidirectional_1[0][0]
=======================================================
Total params: 760005
_______________________________________________________
最终的模型结果如何?我不打算去对比那些评测结果了,现在的模型在测试上达到90%以上的准确率不是什么难事。我关心的是对新词的识别和对歧义的处理。下面是一些测试结果(随便选的):
RNN 的 意思 是 , 为了 预测 最后 的 结果 , 我 先 用 第一个 词 预测 , 当然 , 只 用 第一个 预测 的 预测 结果 肯定 不 精确 , 我 把 这个 结果 作为 特征 , 跟 第二词 一起 , 来 预测 结果 ; 接着 , 我 用 这个 新 的 预测 结果 结合 第三词 , 来 作 新 的 预测 ; 然后 重复 这个 过程 。
结婚 的 和 尚未 结婚 的
苏剑林 是 科学 空间 的 博主 。
广东省 云浮市 新兴县
魏则西 是 一 名 大学生
这 真是 不堪入目 的 环境
列夫·托尔斯泰 是 俄罗斯 一 位 著名 的 作家
保加利亚 首都 索非亚 是 全国 政治 、 经济 、 文化中心 , 位于 保加利亚 中 西部
罗斯福 是 第二次世界大战 期间 同 盟国 阵营 的 重要 领导人 之一 。 1941 年 珍珠港 事件发生 后 , 罗斯 福力 主对 日本 宣战 , 并 引进 了 价格 管制 和 配给 。 罗斯福 以 租 借 法案 使 美国 转变 为 “ 民主 国家 的 兵工厂 ” , 使 美国 成为 同 盟国 主要 的 军火 供应商 和 融资 者 , 也 使得 美国 国内 产业 大幅 扩张 , 实现 充分 就业 。 二战 后期 同 盟国 逐渐 扭转 形势 后 , 罗斯福 对 塑造 战后 世界 秩序 发挥 了 关键 作用 , 其 影响 力 在 雅尔塔 会议 及 联合国 的 成立 中 尤其 明显 。 后来 , 在 美国 协助 下 , 盟军 击败 德国 、 意大利 和 日本 。
可以发现,测试结果是很乐观的。不论是人名(中国人名或外国人名)还是地名,识别效果都很好。关于这个模型,目前就说到这里,以后会继续深入的。
最后 #
事实上本文是提供了一个框架,能够直接通过双向LSTM对序列进行标注,给出完整的标注序列。这种标注的思路,可以用于很多任务,如词性标注、实体识别,因此,基于双向LSTM的seq2seq标注思路,有很广的应用,值得研究。甚至最近热门的深度学习的机器翻译,都是用这种序列到序列的模型实现的。
转载到请包括本文地址:https://kexue.fm/archives/3924
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Aug. 22, 2016). 《【中文分词系列】 4. 基于双向LSTM的seq2seq字标注 》[Blog post]. Retrieved from https://kexue.fm/archives/3924
@online{kexuefm-3924,
title={【中文分词系列】 4. 基于双向LSTM的seq2seq字标注},
author={苏剑林},
year={2016},
month={Aug},
url={\url{https://kexue.fm/archives/3924}},
}

August 3rd, 2018
苏老师,您好。
[[9.9845850e-01 1.5413527e-03 2.0018293e-08 1.3571930e-07 4.7176268e-08]
[9.9696392e-01 4.4201979e-06 6.0934831e-06 3.0253998e-03 2.1210232e-07]
[1.6475507e-05 9.9986351e-01 1.2002354e-04 3.5679773e-10 2.2068347e-09]
[9.2972536e-05 1.4892615e-08 1.3250505e-04 9.9977452e-01 2.8691925e-08]
[1.6979319e-06 9.9998462e-01 1.3749689e-05 9.7263242e-10 8.7142987e-10]
[1.6224482e-04 4.9591140e-04 7.2497368e-01 2.7436778e-01 4.5879750e-07]
[2.5113603e-01 1.7205605e-06 9.0925908e-04 7.4795258e-01 4.8560918e-07]]
['我', '是', '一', '个', '中', '国', '人']
我看predict的数据是正确的,但是最后预测的结果全部都是单个字?不知道是什么原因?
paths[list(nows.keys())[k]] = list(nows.values())[k]
return list(paths.keys())[np.argmax(paths.values())]
维特比算法的最后两行加了list类型转换,不知道是不是这里错了?但是没有加list也一直报错,我看python2到python3转换需要增加list
版本切换的问题我不负责,实在是没空调试,抱歉...
嗯,还是谢谢您的解答。我自己再调试一下。
我用python3调试通过了,python3里面dict.values()和dict.keys()返回的是一个迭代器,而不是一个列表。所以np.argmax(paths.values())也要改成np.argmax(list(paths.values())),不然np.argmax()会返回一个错误的值。下面是我修改后的viterbi函数:
def viterbi(nodes):
paths = {'b':nodes[0]['b'], 's':nodes[0]['s']}
for l in range(1,len(nodes)):
paths_ = paths.copy()
paths = {}
for i in nodes[l].keys():
nows = {}
for j in paths_.keys():
if j[-1]+i in zy.keys():
nows[j+i]= paths_[j]+nodes[l][i]+zy[j[-1]+i]
k = np.argmax(list(nows.values()))
paths[list(nows.keys())[k]] = list(nows.values())[k]
return list(paths.keys())[np.argmax(list(paths.values()))]
August 14th, 2018
请问苏老师,您这个想法有没有发表论文呢?
October 3rd, 2018
您好,老师,请问你的代码是在python 哪个版本,哪个环境跑的呢?在引入keras之前的代码,在python2.7的IDE上可以跑通,但后面keras不支持,所以我去了python3,虽然支持了keras,但前面的代码就各种提示错误,是python两个版本对于语法的要求不一样导致的。求有什么好的方法跑通程序吗?
好的方法:学好python基础再看本文及本文的代码。可能有些代码已经过时,需要对照keras官方文档自行调整。
December 18th, 2018
学长您好,我想请教一下,您最后用dense(5)将64个单元全连接到5的单元上,在传递中的h(t-1)应该还是64个变量把,还有最后生成结果的方式是不是在每个输出后接softmax函数,维特比在这里的作用是什么呢?谢谢学长。
你前面的理解都没有错,Dense(5)仅仅是对RNN的输出进行运算。
维特比算法仅仅用于解码阶段。
September 24th, 2019
老师您好!想请教一下,simple_cut函数里面的:
r=model.predict(np.array([list(chars[list(s)].fillna(0).astype(int))+[0]*(maxlen-len(s))]), verbose=False)[0][:len(s)]
“chars[list(s)]”如果要预测的字符不在chars内,就会报错,请问是否只能输入字典里已有的字符?
是,当时写得比较简陋,你可以自行修改。
November 6th, 2022
[...]本节来自于苏剑林,《【中文分词系列】 4.基于双向LSTM的seq2seq字标注》[...]
November 6th, 2022
[...]本节来自于苏剑林,《【中文分词系列】 4.基于双向LSTM的seq2seq字标注》[...]
March 13th, 2023
[...]1、【中文分词系列】 4. 基于双向LSTM的seq2seq字标注[...]
January 8th, 2024
[...]基于双向 LSTM 的 seq2seq 字标注[...]