






26
Mar
科学空间浏览指南(FAQ)
By 苏剑林 | 2019-03-26 | 138987位读者 | 引用事实上,除了写博客内容,在这几年里,笔者是花了相当一部分时间来做科学空间的“表面功夫”,为此还专门学了一点php、css和js。虽然不敢说精益求精,但总体来说网站的浏览体验应该比前几年要好得多。
考虑到有些读者可能需要的功能,但一时半会未必能留意到,遂来整理一些站内技巧。
文章篇
什么环境阅读文章最佳?
两年前科学空间就已经加入了响应式设计,自动适应不同分辨率的屏幕。因此,不管哪个分辨率的环境应该都能看清文字内容,唯一的问题是,在小屏幕手机下公式可能会显示不全或者错位。为了较好地阅读公式,最好在7寸以上的屏幕上阅读。如果一定要用小屏幕的手机,可以考虑横屏阅读。
28
Mar
分享:用LaTeX+MathJax画一个三维三阶环方
By 苏剑林 | 2019-03-28 | 19650位读者 | 引用昨天看到数学研发论坛在讨论三维三阶幻方,论坛里的各大牛都已经讨论得差不多了,我也没什么好插话的。然后突发奇想,能不能用纯LaTeX画出一个这样的立体幻方出来?
昨天下午折腾了好一会儿,最后只抛出了个半成品,然后经过论坛的mathe大佬继续完善后,终于成功地画出来了:
$$\begin{array}{ccccccccccc}
& & & & 4 & —& —& — & — & 25 & —& —& — & — & 11
\\
& & & \require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|} &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & && &\require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|} &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} && &&\require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|} &|
\\
& & 14 & — & — & —& — & 22 & — & — & — & —& 7 & & |
\\
& \require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}}& &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & &\require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}}& & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}}&&\require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|} & | & & | \\
24 & — & —& —& — & 1 & —& —& — & — & 18 & & | & & |\\
|& & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & &\color{red}{13} &| & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} &\color{red}{27} & | & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} & | &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}&5\\
|& & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & \require{HTML} \style{display: inline-block; transform: rotate(45deg); opacity:0.5;}{\color{red}{\vdots}} &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & | & & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} &\require{HTML} \style{display: inline-block; transform: rotate(45deg); opacity:0.5;}{\color{red}{\vdots}} &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} &| & & |&\require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|} &|\\
|& & \color{red}{8} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}& | &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} & \color{red}{12} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}& | &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}&22&&|\\
|&\require{HTML} \style{display: inline-block; transform: rotate(45deg); opacity:0.5;}{\color{red}{\vdots}} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & | &\require{HTML} \style{display: inline-block; transform: rotate(45deg); opacity:0.5;}{\color{red}{\vdots}} &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}}& | &\require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|} & | &&|\\
15 & — & —& —& — & 3 & — & — & —& —& 21 & & | & &|\\
|& & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & & \color{red}{9} &| &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} & \color{red}{26} &|&\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}&|&\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}&6\\
|& & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}}&\require{HTML} \style{display: inline-block; transform: rotate(45deg); opacity:0.5;}{\color{red}{\vdots}} & &| & &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\vdots}} &\require{HTML} \style{display: inline-block; transform: rotate(45deg); opacity:0.5;}{\color{red}{\vdots}} &&|&&|&\style{display: inline-block; transform: rotate(45deg)}{|}\\
|& &\color{red}{16} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}} &|&\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}& \color{red}{8} &\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}&\require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}& | & \require{HTML} \style{display: inline-block; opacity:0.5;}{\color{red}{\cdots}}&17\\
|& \require{HTML} \style{display: inline-block; transform: rotate(45deg); opacity:0.5;}{\color{red}{\vdots}}& & & &|& \require{HTML} \style{display: inline-block; transform: rotate(45deg); opacity:0.5;}{\color{red}{\vdots}} &&&& | & \require{HTML} \style{display: inline-block; transform: rotate(45deg)}{|}\\
23 & — & — & — & — & 2 & — & — & — & — & 19\\
\end{array}$$
事实上代码里边还内嵌了一些HTML代码,所以不算是严格的纯LaTeX代码,应该说是LaTeX+MathJax的结合。
7
Jun
端午&高考乱弹:怀念的,也许只是怀念本身
By 苏剑林 | 2019-06-07 | 54101位读者 | 引用
9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 102479位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
13
Nov
n维空间下两个随机向量的夹角分布
By 苏剑林 | 2019-11-13 | 149228位读者 | 引用昨天群里大家讨论到了$n$维向量的一些反直觉现象,其中一个话题是“一般$n$维空间下两个随机向量几乎都是垂直的”,这就跟二维/三维空间的认知有明显出入了。要从理论上认识这个结论,我们可以考虑两个随机向量的夹角$\theta$分布,并算算它的均值方差。
概率密度
首先,我们来推导$\theta$的概率密度函数。呃,其实也不用怎么推导,它是$n$维超球坐标的一个直接结论。
要求两个随机向量之间的夹角分布,很显然,由于各向同性,所以我们只需要考虑单位向量,而同样是因为各向同性,我们只需要固定其中一个向量,考虑另一个向量随机变化。不是一般性,考虑随机向量为
\begin{equation}\boldsymbol{x}=(x_1,x_2,\dots,x_n)\end{equation}
而固定向量为
\begin{equation}\boldsymbol{y}=(1,0,\dots,0)\end{equation}
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 98069位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
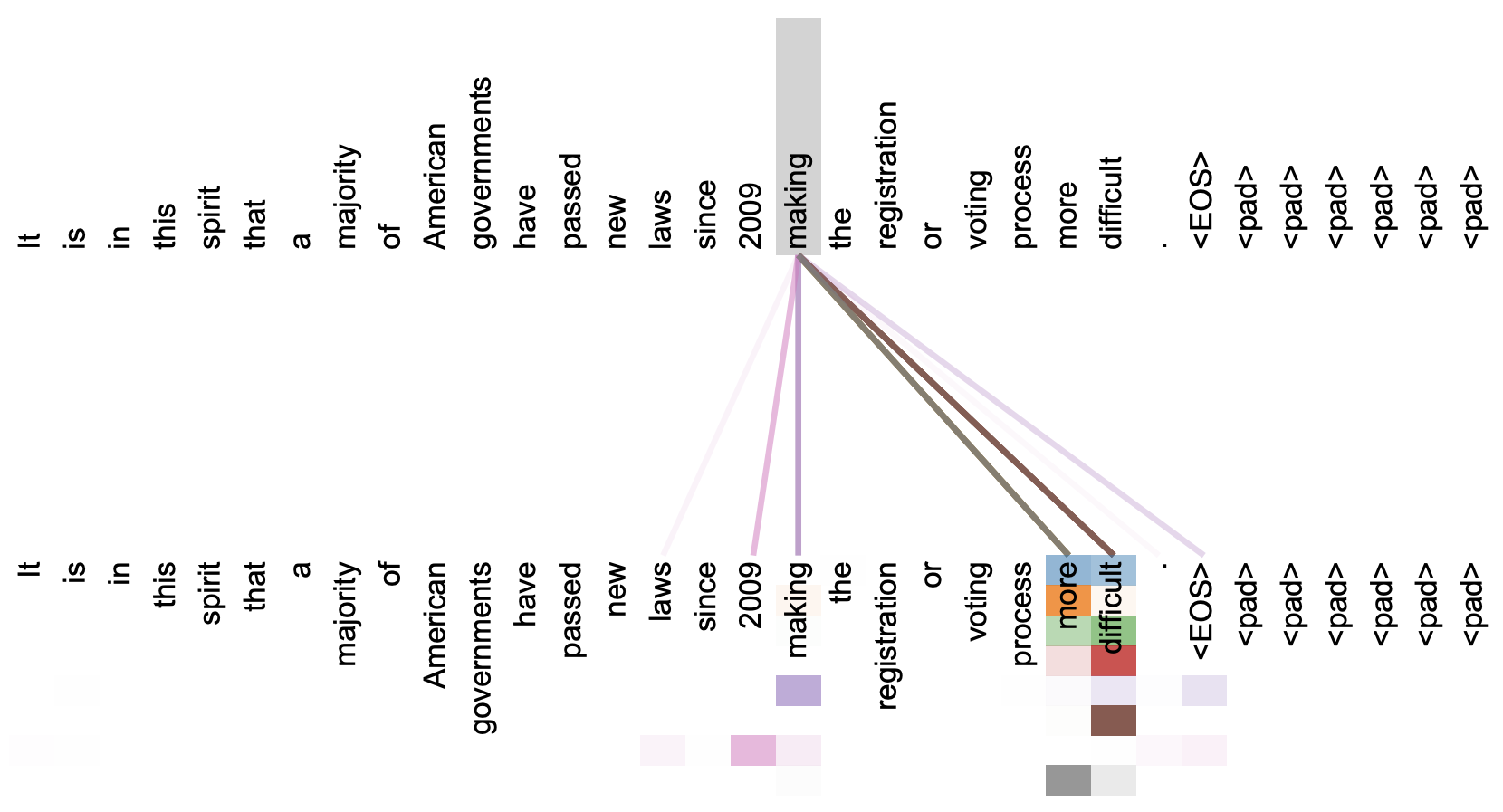
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
7
Dec
【龟鱼记】全陶粒的同程底滤生态缸
By 苏剑林 | 2020-12-07 | 62039位读者 | 引用
21
Dec
从动力学角度看优化算法(七):SGD ≈ SVM?
By 苏剑林 | 2020-12-21 | 38938位读者 | 引用众所周知,在深度学习之前,机器学习是SVM(Support Vector Machine,支持向量机)的天下,曾经的它可谓红遍机器学习的大江南北,迷倒万千研究人员,直至今日,“手撕SVM”仍然是大厂流行的面试题之一。然而,时过境迁,当深度学习流行起来之后,第一个革的就是SVM的命,现在只有在某些特别追求效率的场景以及大厂的面试题里边,才能看到SVM的踪迹了。
峰回路转的是,最近Arxiv上的一篇论文《Every Model Learned by Gradient Descent Is Approximately a Kernel Machine》做了一个非常“霸气”的宣言:
任何由梯度下降算法学出来的模型,都是可以近似看成是一个SVM!
这结论真不可谓不“霸气”,因为它已经不只是针对深度学习了,而是只要你用梯度下降优化的,都不过是一个SVM(的近似)。笔者看了一下原论文的分析,感觉确实挺有意思也挺合理的,有助于加深我们对很多模型的理解,遂跟大家分享一下。

最近评论