






最近一直在考虑一些自然语言处理问题和一些非线性分析问题,无暇总结发文,在此表示抱歉。本文要说的是对于一阶非线性差分方程(当然高阶也可以类似地做)的一种摄动格式,理论上来说,本方法可以得到任意一阶非线性差分方程的显式渐近解。
非线性差分方程
对于一般的一阶非线性差分方程
$$\begin{equation}\label{chafenfangcheng}x_{n+1}-x_n = f(x_n)\end{equation}$$
通常来说,差分方程很少有解析解,因此要通过渐近分析等手段来分析非线性差分方程的性质。很多时候,我们首先会考虑将差分替换为求导,得到微分方程
$$\begin{equation}\label{weifenfangcheng}\frac{dx}{dn}=f(x)\end{equation}$$
作为差分方程$\eqref{chafenfangcheng}$的近似。其中的原因,除了微分方程有比较简单的显式解之外,另一重要原因是微分方程$\eqref{weifenfangcheng}$近似保留了差分方程$\eqref{chafenfangcheng}$的一些比较重要的性质,如渐近性。例如,考虑离散的阻滞增长模型:
$$\begin{equation}\label{zuzhizengzhang}x_{n+1}=(1+\alpha)x_n -\beta x_n^2\end{equation}$$
对应的微分方程为(差分替换为求导):
$$\begin{equation}\frac{dx}{dn}=\alpha x -\beta x^2\end{equation}$$
此方程解得
$$\begin{equation}x_n = \frac{\alpha}{\beta+c e^{-\alpha n}}\end{equation}$$
其中$c$是任意常数。上述结果已经大概给出了原差分方程$\eqref{zuzhizengzhang}$的解的变化趋势,并且成功给出了最终的渐近极限$x_n \to \frac{\alpha}{\beta}$。下图是当$\alpha=\beta=1$且$c=1$(即$x_0=\frac{1}{2}$)时,微分方程的解与差分方程的解的值比较。
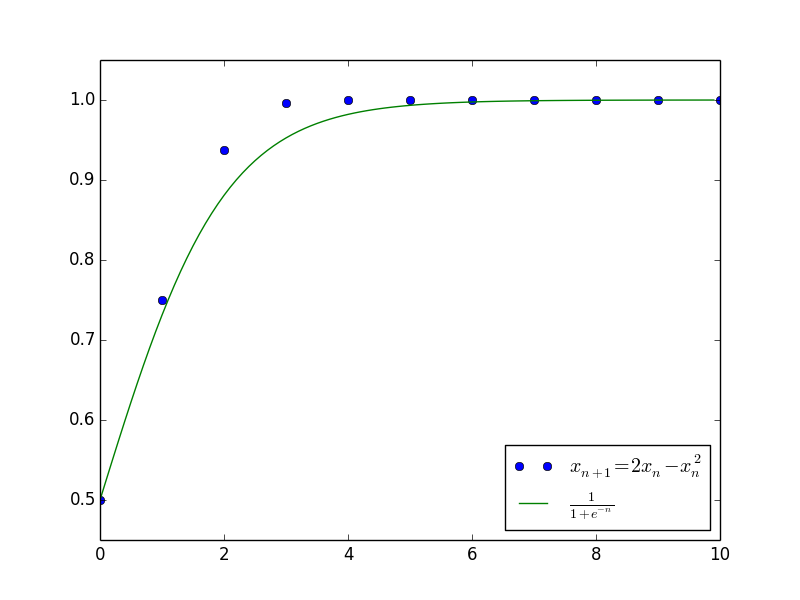
差分方程的摄动法1
现在的问题是,既然微分方程的解可以作为一个形态良好的近似解了,那么是否可以在微分方程的解的基础上,进一步加入修正项提高精度?
9
Jun
路径积分系列:5.例子和综述
By 苏剑林 | 2016-06-09 | 23967位读者 | 引用路径积分方法为解决某些随机问题带来了新视角.
一个例子:股票价格模型
考虑有风险资产(如股票),在$t$时刻其价格为$S_t$,考虑的时间区间为$[0,T]$,0表示初始时间,$T$表示为到期日. $S_t$看作是随时间变化的连续时间变量,并服从下列随机微分方程:
$$dS_t^0=rS_t^0 dt;\quad dS_t=S_t(\mu dt+\sigma dW_t).\tag{70}$$
其中,$\mu$和$\sigma$是两个常量,$W_t$是一个标准布朗运动.
关于$S_t$的方程是一个随机微分方程,一般解决思路是通过随机微积分. 随机微积分有别于一般的微积分的地方在于,随机微积分在做一阶展开的时候,不能忽略$dS_t^2$项,因为$dW_t^2=dt$. 比如,设$S_t=e^{x_t}$,则$x_t=\ln S_t$
$$\begin{aligned}dx_t=&\ln(S_t+dS_t)-\ln S_t=\frac{dS_t}{S_t}-\frac{dS_t^2}{2S_t^2}\\
=&\frac{S_t(\mu dt+\sigma dW_t)}{S_t}-\frac{[S_t(\mu dt+\sigma dW_t)]^2}{2S_t^2}\\
=&\mu dt+\sigma dW_t-\frac{1}{2}\sigma^2 dW_t^2\quad(\text{其余项均低于}dt\text{阶})\\
=&\left(\mu-\frac{1}{2}\sigma^2\right) dt+\sigma dW_t\end{aligned}
,\tag{71}$$
2
Nov
【理解黎曼几何】8. 处处皆几何 (力学几何化)
By 苏剑林 | 2016-11-02 | 62329位读者 | 引用黎曼几何在广义相对论中的体现和应用,虽然不能说家喻户晓,但想必大部分读者都有所听闻。一谈到黎曼几何在物理学中的应用,估计大家的第一反应就是广义相对论。常见的观点是,广义相对论的发现大大推动了黎曼几何的发展。诚然,这是事实,然而,大多数人不知道的事,哪怕经典的牛顿力学中,也有黎曼几何的身影。
本文要谈及的内容,就是如何将力学几何化,从而使用黎曼几何的概念来描述它们。整个过程事实上是提供了一种框架,它可以将不少其他领域的理论纳入到黎曼几何体系中。
黎曼几何的出发点就是黎曼度量,通过黎曼度量可以通过变分得到测地线。从这个意义上来看,黎曼度量提供了一个变分原理。那反过来,一个变分原理,能不能提供一个黎曼度量呢?众所周知,不少学科的基础原理都可以归结为一个极值原理,而有了极值原理就不难导出变分原理(泛函极值),如物理中就有最小作用量原理、最小势能原理,概率论中有最大熵原理,等等。如果有一个将变分原理导出黎曼度量的方法,那么就可以用几何的方式来描述它。幸运的是,对于二次型的变分原理,是可以做到的。
27
Jun
从动力学角度看优化算法(一):从SGD到动量加速
By 苏剑林 | 2018-06-27 | 173535位读者 | 引用在这个系列中,我们来关心优化算法,而本文的主题则是SGD(stochastic gradient descent,随机梯度下降),包括带Momentum和Nesterov版本的。对于SGD,我们通常会关心的几个问题是:
SGD为什么有效?
SGD的batch size是不是越大越好?
SGD的学习率怎么调?
Momentum是怎么加速的?
Nesterov为什么又比Momentum稍好?
...
这里试图从动力学角度分析SGD,给出上述问题的一些启发性理解。
梯度下降
既然要比较谁好谁差,就需要知道最好是什么样的,也就是说我们的终极目标是什么?
训练目标分析
假设全部训练样本的集合为$\boldsymbol{S}$,损失度量为$L(\boldsymbol{x};\boldsymbol{\theta})$,其中$\boldsymbol{x}$代表单个样本,而$\boldsymbol{\theta}$则是优化参数,那么我们可以构建损失函数
$$L(\boldsymbol{\theta}) = \frac{1}{|\boldsymbol{S}|}\sum_{\boldsymbol{x}\in\boldsymbol{S}} L(\boldsymbol{x};\boldsymbol{\theta})\tag{1}$$
而训练的终极目标,则是找到$L(\boldsymbol{\theta})$的一个全局最优点(这里的最优是“最小”的意思)。
7
Nov
WGAN-div:一个默默无闻的WGAN填坑者
By 苏剑林 | 2018-11-07 | 166898位读者 | 引用今天我们来谈一下Wasserstein散度,简称“W散度”。注意,这跟Wasserstein距离(Wasserstein distance,简称“W距离”,又叫Wasserstein度量、Wasserstein metric)是不同的两个东西。
本文源于论文《Wasserstein Divergence for GANs》,论文中提出了称为WGAN-div的GAN训练方案。这是一篇我很是欣赏却默默无闻的paper,我只是找文献时偶然碰到了它。不管英文还是中文界,它似乎都没有流行起来,但是我感觉它是一个相当漂亮的结果。

WGAN-div的部分样本(2w iter)
如果读者需要入门一下WGAN的相关知识,不妨请阅读拙作《互怼的艺术:从零直达WGAN-GP》。
WGAN
我们知道原始的GAN(SGAN)会有可能存在梯度消失的问题,因此WGAN横空出世了。
W距离
WGAN引入了最优传输里边的W距离来度量两个分布的距离:
\begin{equation}W_c[\tilde{p}(x), q(x)] = \inf_{\gamma\in \Pi(\tilde{p}(x), q(x))} \mathbb{E}_{(x,y)\sim \gamma}[c(x,y)] \end{equation}
这里的$\tilde{p}(x)$是真实样本的分布,$q(x)$是伪造分布,$c(x,y)$是传输成本,论文中用的是$c(x,y)=\Vert x-y\Vert$;而$\gamma\in \Pi(\tilde{p}(x), q(x))$的意思是说:$\gamma$是任意关于$x, y$的二元分布,其边缘分布则为$\tilde{p}(x)$和$q(y)$。直观来看,$\gamma$描述了一个运输方案,而$c(x,y)$则是运输成本,$W_c[\tilde{p}(x), q(x)]$就是说要找到成本最低的那个运输方案所对应的成本作为分布度量。
14
Nov
当Batch Size增大时,学习率该如何随之变化?
By 苏剑林 | 2024-11-14 | 37762位读者 | 引用随着算力的飞速进步,有越多越多的场景希望能够实现“算力换时间”,即通过堆砌算力来缩短模型训练时间。理想情况下,我们希望投入$n$倍的算力,那么达到同样效果的时间则缩短为$1/n$,此时总的算力成本是一致的。这个“希望”看上去很合理和自然,但实际上并不平凡,即便我们不考虑通信之类的瓶颈,当算力超过一定规模或者模型小于一定规模时,增加算力往往只能增大Batch Size。然而,增大Batch Size一定可以缩短训练时间并保持效果不变吗?
这就是接下来我们要讨论的话题:当Batch Size增大时,各种超参数尤其是学习率该如何调整,才能保持原本的训练效果并最大化训练效率?我们也可以称之为Batch Size与学习率之间的Scaling Law。
方差视角
直觉上,当Batch Size增大时,每个Batch的梯度将会更准,所以步子就可以迈大一点,也就是增大学习率,以求更快达到终点,缩短训练时间,这一点大体上都能想到。问题就是,增大多少才是最合适的呢?
15
Sep
殊途同归的策略梯度与零阶优化
By 苏剑林 | 2020-09-15 | 61671位读者 | 引用深度学习如此成功的一个巨大原因就是基于梯度的优化算法(SGD、Adam等)能有效地求解大多数神经网络模型。然而,既然是基于梯度,那么就要求模型是可导的,但随着研究的深入,我们时常会有求解不可导模型的需求,典型的例子就是直接优化准确率、F1、BLEU等评测指标,或者在神经网络里边加入了不可导模块(比如“跳读”操作)。

Gradient
本文将简单介绍两种求解不可导的模型的有效方法:强化学习的重要方法之一策略梯度(Policy Gradient),以及干脆不需要梯度的零阶优化(Zeroth Order Optimization)。表面上来看,这是两种思路完全不一样的优化方法,但本文将进一步证明,在一大类优化问题中,其实两者基本上是等价的。
8
Apr
生成扩散模型漫谈(二十二):信噪比与大图生成(上)
By 苏剑林 | 2024-04-08 | 58029位读者 | 引用盘点主流的图像扩散模型作品,我们会发现一个特点:当前多数做高分辨率图像生成(下面简称“大图生成”)的工作,都是先通过Encoder变换到Latent空间进行的(即LDM,Latent Diffusion Model),直接在原始Pixel空间训练的扩散模型,大多数分辨率都不超过64*64,而恰好,LDM通过AutoEncoder变换后的Latent,大小通常也不超过64*64。这就自然引出了一系列问题:扩散模型是不是对于高分辨率生成存在固有困难?能否在Pixel空间直接生成高分辨率图像?
论文《Simple diffusion: End-to-end diffusion for high resolution images》尝试回答了这个问题,它通过“信噪比”分析了大图生成的困难,并以此来优化noise schdule,同时提出只需在最低分辨率feature上对架构进行scale up、多尺度Loss等技巧来保证训练效率和效果,这些改动使得原论文成功在Pixel空间上训练了分辨率高达1024*1024的图像扩散模型。

最近评论