






18
Jan
当大数据进入厨房:让大数据教你做菜!
By 苏剑林 | 2016-01-18 | 44991位读者 | 引用说在前面

美食(图片来源于互联网)
在空间侧边栏的笔者的自我介绍中,有一行是“厨房爱好者”,虽然笔者不怎么会做菜,但确实,厨房是我的一个爱好。当然,笔者的爱好很多,数学、物理、天文、计算机等,都喜欢,都想学,弄到多而不精。在之前的文章中也已经提到过,数据挖掘也是我的一个爱好,而当数据挖掘跟厨房这两个爱好相遇了,会有什么有趣的结果吗?
笔者正是做了这样一个事情:从美食中国的家常菜目录下面,写了个简单的爬虫,抓取了一批菜谱数据下来,进行简单的数据分析。(在此对美食中国表示衷心感谢。选择美食中国的原因是它的数据比较规范。)数据分析在我目前公司的高性能服务器做,分析起来特别舒服~~
这里共收集了18209个菜谱,共包含了9700种食材(包括主料、辅料、调料,部分可能由于命名不规范等原因会重复)。当然,这个数据量相对于很多领域的大数据标准来说,实在不值一提。但是在大数据极少涉及的厨房,应该算是比较多的了。
15
Feb
积分估计的极值原理——变分原理的初级版本
By 苏剑林 | 2016-02-15 | 37441位读者 | 引用如果一直关注科学空间的朋友会发现,笔者一直对极值原理有偏爱。比如,之前曾经写过一系列《自然极值》的文章,介绍一些极值问题和变分法;在物理学中,笔者偏爱最小作用量原理的形式;在数据挖掘中,笔者也因此对基于最大熵原理的最大熵模型有浓厚的兴趣;最近,在做《量子力学与路径积分》的习题中,笔者也对第十一章所说的变分原理产生了很大的兴趣。
对于一样新东西,笔者的学习方法是以一个尽可能简单的例子搞清楚它的原理和思想,然后再逐步复杂化,这样子我就不至于迷失了。对于变分原理,它是估算路径积分的一个很强大的方法,路径积分是泛函积分,或者说,无穷维积分,那么很自然想到,对于有限维的积分估计,比如最简单的一维积分,有没有类似的估算原理呢?事实上是有的,它并不复杂,弄懂它有助于了解变分原理的核心思想。很遗憾,我并没有找到已有的资料描述这个简化版的原理,可能跟我找的资料比较少有关。
从高斯型积分出发
变分原理本质上是Jensen不等式的应用。我们从下述积分出发
$$\begin{equation}\label{jifen}I(\epsilon)=\int_{-\infty}^{\infty}e^{-x^2-\epsilon x^4}dx\end{equation}$$
20
Feb
熵的形象来源与熵的妙用
By 苏剑林 | 2016-02-20 | 32506位读者 | 引用在拙作《“熵”不起:从熵、最大熵原理到最大熵模型(一)》中,笔者从比较“专业”的角度引出了熵,并对熵做了诠释。当然,熵作为不确定性的度量,应该具有更通俗、更形象的来源,本文就是试图补充这一部分,并由此给出一些妙用。
熵的形象来源
我们考虑由0-9这十个数字组成的自然数,如果要求小于10000的话,那么很自然有10000个,如果我们说“某个小于10000的自然数”,那么0~9999都有可能出现,那么10000便是这件事的不确定性的一个度量。类似地,考虑$n$个不同元素(可重复使用)组成的长度为$m$的序列,那么这个序列有$n^m$种情况,这时$n^m$也是这件事情的不确定性的度量。
$n^m$是指数形式的,数字可能异常地大,因此我们取了对数,得到$m\log n$,这也可以作为不确定性的度量,它跟我们原来熵的定义是一致的。因为
$$m\log n=-\sum_{i=1}^{n^m} \frac{1}{n^m}\log \frac{1}{n^m}$$
读者可能会疑惑,$n^m$和$m\log n$都算是不确定性的度量,那么究竟是什么原因决定了我们用$m\log n$而不是用$n^m$呢?答案是可加性。取对数后的度量具有可加性,方便我们运算。当然,可加性只是便利的要求,并不是必然的。如果使用$n^m$形式,那么就相应地具有可乘性。
15
May
Coming Back...
By 苏剑林 | 2016-05-15 | 40102位读者 | 引用上一篇博文的发布时间是4月15日,到今天刚好一个月没更新了,但是科学空间的访问量还在。感谢大家对本空间的支持,BoJone对久未更新表示非常抱歉。在恢复更新之前,请允许笔者记记流水账。
在“消失”的一个月中,笔者主要的事情是毕业论文和数据挖掘竞赛。首先毕业论文方面,论文于4月22日交稿,4月29日答辩,答辩完后就意味着毕业论文的事情结束了。我的毕业论文主要写了路径积分在描述随机游走、偏微分方程、随机微分方程的应用。既然是本科论文,就不能说得太晦涩,因此论文整体来看还是比较易读的,可以作为路径积分的入门教程。后面我会略加修改,分开几部分发布在科学空间中的,到时请大家批评指正。
说到路径积分,不得不说到做《量子力学与路径积分》的习题解答这件事情了。很遗憾,这一个多月来,基本没有时间做习题。不过后面我会继续做下去的,已发布的版本,也请有兴趣的读者指出问题。记得年初的时候,朋友问我今年的愿望是什么,我随意地回答了“希望做完一本书的习题”,这本书,当然就是《量子力学与路径积分》了,我相信今年应该能够完成的。
18
Jun
OCR技术浅探:3. 特征提取(2)
By 苏剑林 | 2016-06-18 | 41572位读者 | 引用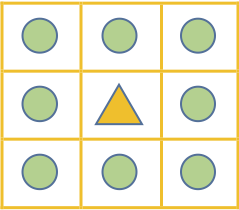
9
Jun
路径积分系列:4.随机微分方程
By 苏剑林 | 2016-06-09 | 31213位读者 | 引用本章将路径积分用于随机微分方程,并且得到了与不对称随机游走一样的结果,从而证明了它与该模型的等价性.
将路径积分用于随机微分方程的研究,这一思路由来已久. 费曼在他的著作[5]中,已经建立了路径积分与线性随机微分方程的关系. 而对于非线性的情况,也有不少研究,但比较混乱,如文献[8]甚至给出了错误的结果.
本文从路径积分的离散化概念出发,明确地建立了两个路径积分微元的雅可比行列式关系,从而对非线性随机微分方程也建立了路径积分. 本文的结果跟文献[9]的结果是一致的.
概念
本文所研究的仅仅是随机常微分方程,它与一般的常微分方程的区别在于布朗运动项的引入,如常见的一类随机微分方程为
$$dx(t)=p(x(t),t)dt + \sqrt{\alpha} dW_t.\tag{48}$$
其中$W_t$代表着一个标准的布朗运动. 由于引入了随机项,所以解$x(t)$不再是确定的,而是有一定的概率分布.
在对随机微分方程中,感兴趣的量有很多,比如关于$x$的某个量的期望、方差,或者稳定性,等等. 随机微分方程领域中有各种分析的技巧,但是显然,直接求出$x(t)$的概率分布后对概率分布进行研究,是最理想最容易的方案. 路径积分正是给出了求概率分布的一个方法.
9
Jun
路径积分系列:5.例子和综述
By 苏剑林 | 2016-06-09 | 23621位读者 | 引用路径积分方法为解决某些随机问题带来了新视角.
一个例子:股票价格模型
考虑有风险资产(如股票),在$t$时刻其价格为$S_t$,考虑的时间区间为$[0,T]$,0表示初始时间,$T$表示为到期日. $S_t$看作是随时间变化的连续时间变量,并服从下列随机微分方程:
$$dS_t^0=rS_t^0 dt;\quad dS_t=S_t(\mu dt+\sigma dW_t).\tag{70}$$
其中,$\mu$和$\sigma$是两个常量,$W_t$是一个标准布朗运动.
关于$S_t$的方程是一个随机微分方程,一般解决思路是通过随机微积分. 随机微积分有别于一般的微积分的地方在于,随机微积分在做一阶展开的时候,不能忽略$dS_t^2$项,因为$dW_t^2=dt$. 比如,设$S_t=e^{x_t}$,则$x_t=\ln S_t$
$$\begin{aligned}dx_t=&\ln(S_t+dS_t)-\ln S_t=\frac{dS_t}{S_t}-\frac{dS_t^2}{2S_t^2}\\
=&\frac{S_t(\mu dt+\sigma dW_t)}{S_t}-\frac{[S_t(\mu dt+\sigma dW_t)]^2}{2S_t^2}\\
=&\mu dt+\sigma dW_t-\frac{1}{2}\sigma^2 dW_t^2\quad(\text{其余项均低于}dt\text{阶})\\
=&\left(\mu-\frac{1}{2}\sigma^2\right) dt+\sigma dW_t\end{aligned}
,\tag{71}$$
17
Jun
OCR技术浅探:2. 背景与假设
By 苏剑林 | 2016-06-17 | 40367位读者 | 引用研究背景
关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不少成熟的OCR技术和产品产生,比如汉王OCR、ABBYY FineReader、Tesseract OCR等. 值得一提的是,ABBYY FineReader不仅正确率高(包括对中文的识别),而且还能保留大部分的排版效果,是一个非常强大的OCR商业软件.
然而,在诸多的OCR成品中,除了Tesseract OCR外,其他的都是闭源的、甚至是商业的软件,我们既无法将它们嵌入到我们自己的程序中,也无法对其进行改进. 开源的唯一选择是Google的Tesseract OCR,但它的识别效果不算很好,而且中文识别正确率偏低,有待进一步改进.
综上所述,不管是为了学术研究还是实际应用,都有必要对OCR技术进行探究和改进. 我们队伍将完整的OCR系统分为“特征提取”、“文字定位”、“光学识别”、“语言模型”四个方面,逐步进行解决,最终完成了一个可用的、完整的、用于印刷文字的OCR系统. 该系统可以初步用于电商、微信等平台的图片文字识别,以判断上面信息的真伪.
研究假设
在本文中,我们假设图像的文字部分有以下的特征:

最近评论