






很早以前我就对这个问题感兴趣了,但是一直搁置着,没有怎么研究。最近在阅读《引力与时空》的“潮汐力”那一节时重新回到了这个问题上,决定写点什么东西。在这里不深究流体静力平衡的定义,顾名思义地理解,它就是流体在某个特定的力场下所达到的平衡状态。流体静力学告诉我们:
达到流体静力平衡时,流体的面必定是一个等势面。
这是为什么呢?我们从数学的角度来简单分析一下:只考虑二维情况,假如等势面方程是$U(x,y)=C$,那么两边微分就有
$$0=dU=\frac{\partial U}{\partial x}dx+\frac{\partial U}{\partial y}dy=(\frac{\partial U}{\partial x},\frac{\partial U}{\partial y})\cdot (dx,dy)$$
这意味着向量$(\frac{\partial U}{\partial x},\frac{\partial U}{\partial y})$和向量$(dx,dy)$是垂直的,前者便是力的函数,后者就是一个切向量(三维就是一个切平面)。也就是说合外力必然和流体面垂直,这样才能提供一个相等的方向相反的内力让整个结构体系处于平衡状态!
26
Sep
数学基本技艺(A Mathematical Trivium)
By 苏剑林 | 2013-09-26 | 25288位读者 | 引用这是Arnold给物理系学生出的基础数学题。原文是Arnold于1991年,在Russian Math Surveys 46:1(1991),271-278上发的一篇文章,英文名叫 A mathematical trivium,这篇文章是有个前言的,用两页纸的内容吐槽了1991年的学生数学学得很烂,尤其是物理系的。文后附了100道数学题,号称是物理系学生的数学底线。
这是给物理系出的数学题,所以和一般的数学竞赛题目不同,没太多证明题,主要就是计算和解模型,而且还有不少近似估算的,带有明显的物理风格。虽然作者说这是物理系学生数学的底线,但即使对于数学系的学生来说,这些题目还是有不少难度的。网络也有一些题目的答案,但是都比较零散。在这里与大家分享一下题目。什么时候有时间了,或者刚好碰到类似的研究,我也会把题目做做,与各位分享。希望有兴趣的朋友做了之后也把答案与大家交流呀。

1
4
Jun
当概率遇上复变:随机游走与路径积分
By 苏剑林 | 2014-06-04 | 24481位读者 | 引用我们在上一篇文章中已经看到,随机游走的概率分布是正态的,而在概率论中可以了解到正态分布(几乎)是最重要的一种分布了。随机游走模型和正态分布的应用都很广,我们或许可以思考一个问题,究竟是随机游走造就了正态分布,还是正态分布造就了随机游走?换句话说,哪个更本质些?个人就自己目前所阅读到的内容来看,随机游走更本质些,随机游走正好对应着普遍存在的随机不确定性(比如每次测量的误差),它的分布正好就是正态分布,所以正态分布才应用得如此广泛——因为随机不确定性无处不在。
下面我们来考虑随机游走的另外一种描述方式,原则上来说,它更广泛,更深刻,其大名曰“路径积分”。
12
Nov
特殊的通项公式:二次非线性递推
By 苏剑林 | 2014-11-12 | 65094位读者 | 引用特殊的通项公式
对数学或编程感兴趣的读者,相信都已经很熟悉斐波那契数列了
0, 1, 1, 2, 3, 5, 8, 13, ...
它是由
$$a_{n+2}=a_{n+1}+a_n,\quad a_0=0,a_1=1$$
递推所得。读者或许已经见过它的通项公式
$$a_{n}=\frac{\sqrt{5}}{5} \cdot \left[\left(\frac{1 + \sqrt{5}}{2}\right)^{n} - \left(\frac{1 - \sqrt{5}}{2}\right)^{n}\right]$$
这里假设我们没有如此高的智商可以求出这个复杂的表达式出来,但是我们通过研究数列发现,这个数列越来越大时,相邻两项趋于一个常数,这个常数也就是(假设我们只发现了后面的数值,并没有前面的根式)
$$\beta=\frac{1 + \sqrt{5}}{2}=1.61803398\dots$$
6
Jun
闲聊:神经网络与深度学习
By 苏剑林 | 2015-06-06 | 73947位读者 | 引用
神经网络
在所有机器学习模型之中,也许最有趣、最深刻的便是神经网络模型了。笔者也想献丑一番,说一次神经网络。当然,本文并不打算从头开始介绍神经网络,只是谈谈我对神经网络的个人理解。如果希望进一步了解神经网络与深度学习的朋友,请移步阅读下面的教程:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
http://blog.csdn.net/zouxy09/article/details/8775360
机器分类
这里以分类工作为例,数据挖掘或机器学习中,有很多分类的问题,比如讲一句话的情况进行分类,粗略点可以分类为“积极”或“消极”,精细点分为开心、生气、忧伤等;另外一个典型的分类问题是手写数字识别,也就是将图片分为10类(0,1,2,3,4,5,6,7,8,9)。因此,也产生了很多分类的模型。
25
Dec
从loss的硬截断、软化到focal loss
By 苏剑林 | 2017-12-25 | 208250位读者 | 引用前言
今天在QQ群里的讨论中看到了focal loss,经搜索它是Kaiming大神团队在他们的论文《Focal Loss for Dense Object Detection》提出来的损失函数,利用它改善了图像物体检测的效果。不过我很少做图像任务,不怎么关心图像方面的应用。本质上讲,focal loss就是一个解决分类问题中类别不平衡、分类难度差异的一个loss,总之这个工作一片好评就是了。大家还可以看知乎的讨论:
《如何评价kaiming的Focal Loss for Dense Object Detection?》
看到这个loss,开始感觉很神奇,感觉大有用途。因为在NLP中,也存在大量的类别不平衡的任务。最经典的就是序列标注任务中类别是严重不平衡的,比如在命名实体识别中,显然一句话里边实体是比非实体要少得多,这就是一个类别严重不平衡的情况。我尝试把它用在我的基于序列标注的问答模型中,也有微小提升。嗯,这的确是一个好loss。
接着我再仔细对比了一下,我发现这个loss跟我昨晚构思的一个loss具有异曲同工之理!这就促使我写这篇博文了。我将从我自己的思考角度出发,来分析这个问题,最后得到focal loss,也给出我昨晚得到的类似的loss。
最近一直在考虑一些自然语言处理问题和一些非线性分析问题,无暇总结发文,在此表示抱歉。本文要说的是对于一阶非线性差分方程(当然高阶也可以类似地做)的一种摄动格式,理论上来说,本方法可以得到任意一阶非线性差分方程的显式渐近解。
非线性差分方程
对于一般的一阶非线性差分方程
$$\begin{equation}\label{chafenfangcheng}x_{n+1}-x_n = f(x_n)\end{equation}$$
通常来说,差分方程很少有解析解,因此要通过渐近分析等手段来分析非线性差分方程的性质。很多时候,我们首先会考虑将差分替换为求导,得到微分方程
$$\begin{equation}\label{weifenfangcheng}\frac{dx}{dn}=f(x)\end{equation}$$
作为差分方程$\eqref{chafenfangcheng}$的近似。其中的原因,除了微分方程有比较简单的显式解之外,另一重要原因是微分方程$\eqref{weifenfangcheng}$近似保留了差分方程$\eqref{chafenfangcheng}$的一些比较重要的性质,如渐近性。例如,考虑离散的阻滞增长模型:
$$\begin{equation}\label{zuzhizengzhang}x_{n+1}=(1+\alpha)x_n -\beta x_n^2\end{equation}$$
对应的微分方程为(差分替换为求导):
$$\begin{equation}\frac{dx}{dn}=\alpha x -\beta x^2\end{equation}$$
此方程解得
$$\begin{equation}x_n = \frac{\alpha}{\beta+c e^{-\alpha n}}\end{equation}$$
其中$c$是任意常数。上述结果已经大概给出了原差分方程$\eqref{zuzhizengzhang}$的解的变化趋势,并且成功给出了最终的渐近极限$x_n \to \frac{\alpha}{\beta}$。下图是当$\alpha=\beta=1$且$c=1$(即$x_0=\frac{1}{2}$)时,微分方程的解与差分方程的解的值比较。
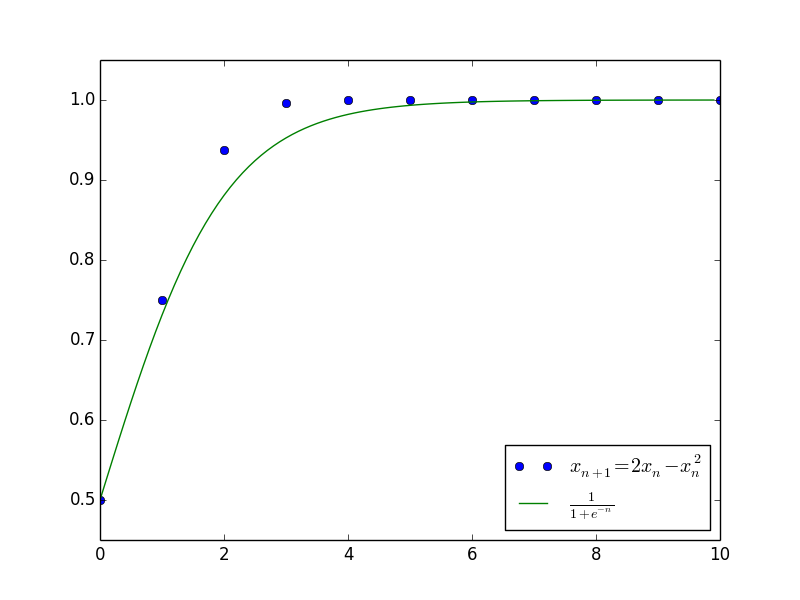
差分方程的摄动法1
现在的问题是,既然微分方程的解可以作为一个形态良好的近似解了,那么是否可以在微分方程的解的基础上,进一步加入修正项提高精度?
6
Dec


最近评论