






22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 222514位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
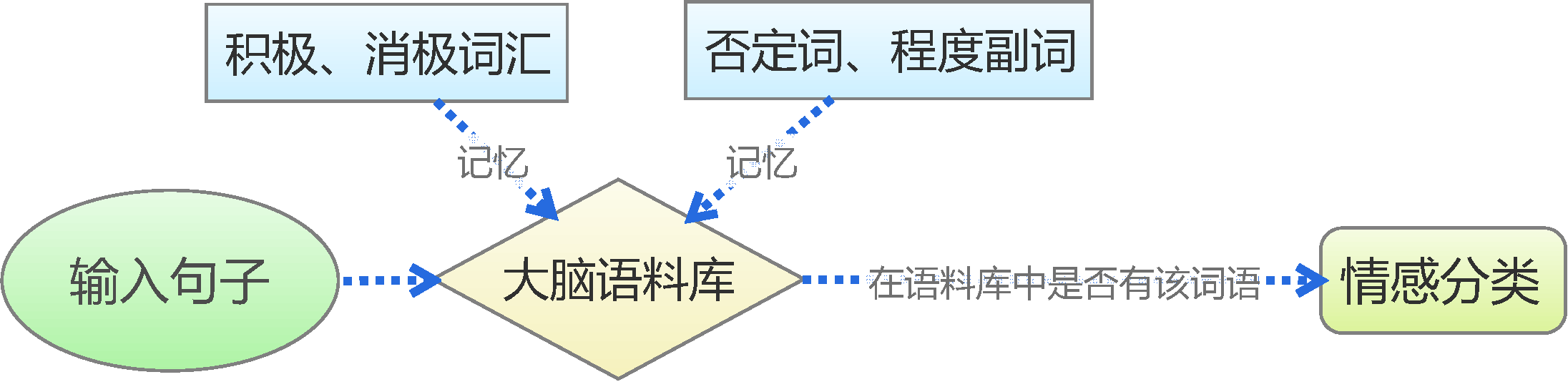
人的最简单的判断思维
2
Jul
用Pandas实现高效的Apriori算法
By 苏剑林 | 2015-07-02 | 140811位读者 | 引用最近在做数据挖掘相关的工作,阅读到了Apriori算法。平时由于没有涉及到相关领域,因此对Apriori算法并不了解,而如今工作上遇到了,就不得不认真学习一下了。Apriori算法是一个寻找关联规则的算法,也就是从一大批数据中找到可能的逻辑,比如“条件A+条件B”很有可能推出“条件C”(A+B-->C),这就是一个关联规则。具体来讲,比如客户买了A商品后,往往会买B商品(反之,买了B商品不一定会买A商品),或者更复杂的,买了A、B两种商品的客户,很有可能会再买C商品(反之也不一定)。有了这些信息,我们就可以把一些商品组合销售,以获得更高的收益。而寻求关联规则的算法,就是关联分析算法。
啤酒与尿布

啤酒与尿布
关联算法的案例中,最为人老生常谈的应该是“啤酒与尿布”了。“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,超市管理人员发现“啤酒与尿布两件看上去毫无关系的商品会经常出现在同一个购物篮中”。经过分析,原来在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。因此,沃尔玛尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品。事实是效果相当不错!
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 601338位读者 | 引用
13
Aug
exp(1/2 t^2+xt)级数展开的图解技术
By 苏剑林 | 2015-08-13 | 30923位读者 | 引用本文要研究的是关于$t$的函数
$$\exp\left(\frac{1}{2}t^2+xt\right)$$
在$t=0$处的泰勒展开式。显然,它并不困难,手算或者软件都可以做出来,答案是:
$$1+x t+\frac{1}{2} \left(x^2+1\right) t^2+\frac{1}{6}\left(x^3+3 x\right) t^3 +\frac{1}{24} \left(x^4+6 x^2+3\right) t^4 + \dots$$
不过,本文将会给出笔者构造的该级数的一个图解方法。通过这个图解方法比较比较直观而方便地手算出展开式的前面一些项。后面我们再来谈谈这种图解技术的起源以及进一步的应用。
级数的图解方法:说明
首先,很明显要写出这个级数,关键是写出展开式的每一项,也就是要求出
$$f_k (x) = \left.\frac{d^k}{dt^k}\exp\left(\frac{1}{2}t^2+xt\right)\right|_{t=0}$$
$f_k (x)$是一个关于$x$的$k$次整系数多项式,$k$是展开式的阶,也是求导的阶数。
这里,我们用一个“点”表示一个$x$,用“两点之间的一条直线”表示“相乘”,那么,$x^2$就可以表示成

x^2项
5
Oct
2015诺贝尔医学奖:中国人在内
By 苏剑林 | 2015-10-05 | 23754位读者 | 引用
7
Dec
一阶偏微分方程的特征线法
By 苏剑林 | 2017-12-07 | 80335位读者 | 引用本文以尽可能清晰、简明的方式来介绍了一阶偏微分方程的特征线法。个人认为这是偏微分方程理论中较为简单但事实上又容易让人含糊的一部分内容,因此尝试以自己的文字来做一番介绍。当然,更准确来说其实是笔者自己的备忘。
拟线性情形
一般步骤
考虑偏微分方程
$$\begin{equation}\boldsymbol{\alpha}(\boldsymbol{x},u) \cdot \frac{\partial}{\partial \boldsymbol{x}} u = \beta(\boldsymbol{x},u)\end{equation}$$
其中$\boldsymbol{\alpha}$是一个$n$维向量函数,$\beta$是一个标量函数,$\cdot$是向量的点积,$u\equiv u(\boldsymbol{x})$是$n$元函数,$\boldsymbol{x}$是它的自变量。
28
Dec
【分享】兴隆山的双子座流星雨
By 苏剑林 | 2015-12-28 | 27386位读者 | 引用
15
Feb
积分估计的极值原理——变分原理的初级版本
By 苏剑林 | 2016-02-15 | 34996位读者 | 引用如果一直关注科学空间的朋友会发现,笔者一直对极值原理有偏爱。比如,之前曾经写过一系列《自然极值》的文章,介绍一些极值问题和变分法;在物理学中,笔者偏爱最小作用量原理的形式;在数据挖掘中,笔者也因此对基于最大熵原理的最大熵模型有浓厚的兴趣;最近,在做《量子力学与路径积分》的习题中,笔者也对第十一章所说的变分原理产生了很大的兴趣。
对于一样新东西,笔者的学习方法是以一个尽可能简单的例子搞清楚它的原理和思想,然后再逐步复杂化,这样子我就不至于迷失了。对于变分原理,它是估算路径积分的一个很强大的方法,路径积分是泛函积分,或者说,无穷维积分,那么很自然想到,对于有限维的积分估计,比如最简单的一维积分,有没有类似的估算原理呢?事实上是有的,它并不复杂,弄懂它有助于了解变分原理的核心思想。很遗憾,我并没有找到已有的资料描述这个简化版的原理,可能跟我找的资料比较少有关。
从高斯型积分出发
变分原理本质上是Jensen不等式的应用。我们从下述积分出发
$$\begin{equation}\label{jifen}I(\epsilon)=\int_{-\infty}^{\infty}e^{-x^2-\epsilon x^4}dx\end{equation}$$

最近评论