






29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 396807位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
22
Aug
【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
By 苏剑林 | 2016-08-22 | 453141位读者 | 引用关于字标注法
上一篇文章谈到了分词的字标注法。要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了。在我看来,字标注法有效有两个主要的原因,第一个原因是它将分词问题变成了一个序列标注问题,而且这个标注是对齐的,也就是输入的字跟输出的标签是一一对应的,这在序列标注中是一个比较成熟的问题;第二个原因是这个标注法实际上已经是一个总结语义规律的过程,以4tag标注为为例,我们知道,“李”字是常用的姓氏,一半作为多字词(人名)的首字,即标记为b;而“想”由于“理想”之类的词语,也有比较高的比例标记为e,这样一来,要是“李想”两字放在一起时,即便原来词表没有“李想”一词,我们也能正确输出be,也就是识别出“李想”为一个词,也正是因为这个原因,即便是常被视为最不精确的HMM模型也能起到不错的效果。
关于标注,还有一个值得讨论的内容,就是标注的数目。常用的是4tag,事实上还有6tag和2tag,而标记分词结果最简单的方法应该是2tag,即标记“切分/不切分”就够了,但效果不好。为什么反而更多数目的tag效果更好呢?因为更多的tag实际上更全面概括了语义规律。比如,用4tag标注,我们能总结出哪些字单字成词、哪些字经常用作开头、哪些字用作末尾,但仅仅用2tag,就只能总结出哪些字经常用作开头,从归纳的角度来看,是不够全面的。但6tag跟4tag比较呢?我觉得不一定更好,6tag的意思是还要总结出哪些字作第二字、第三字,但这个总结角度是不是对的?我觉得,似乎并没有哪些字固定用于第二字或者第三字的,这个规律的总结性比首字和末字的规律弱多了(不过从新词发现的角度来看,6tag更容易发现长词。)。
双向LSTM
5
Sep
进驻中山大学南校区,折腾校园网
By 苏剑林 | 2016-09-05 | 77096位读者 | 引用开始研究僧之旅,希望有一天能企及扫地僧的境界。
进入中山大学后,各种郁闷的事情就来了。首先最郁闷的就是开学时间特早,8月26日开学,感觉至少比一般学校早了一星期,开学这么早有意思么~~接着就是感觉中大的管理制度各种混乱,比我本科的华师差多了。好吧,这些琐事先不吐槽,接下来弄校园网,这是作死的开始。
我们是在南校区的,校园网是通过锐捷客户端来认证的,而我是用macbook的,不过中大这边还很人性化地提供了Mac版的锐捷,体积就1M左右,挺好的。但众所周知,macbook并没有有线网卡,每次我上网都得插着个USB网卡然后连着网线,这该有多郁闷。于是想办法通过路由器拨号。我也不算没经验的了,对openwrt这个系统有过一定研究,以前在本科的时候也是锐捷,可以用mentohust替代拨号,很简单。于是我在这里重复这样的过程,发现一直认证失败,按照网上提示的各种方法,都无法解决。
经过研究,我发现在Windows下,这里就只能用官方提供了锐捷4.90版本,从其他地方下载的更高级或者更低级的锐捷,都无法通过验证。估计就是因为这个机制,导致了mentohust难以通过验证。而且网上流行的mentohust都是基于V2协议的,但4.90是基于V4的。后来我又去下载了V4版本的进行交叉编译,测试发现还不成功。几近绝望的时候,我发现了mentohust-proxy,一个mentohust的改进版,让我找到了希望。(怎么找到它?我是直接到github搜索了,因为实在没辙了~~)
原理很简单,如果直接通过mentohust无法完成认证,那么就通过代理模式,由电脑来完成认证,而mentohust只需要负责发送心跳包维持联网就行。这是个很折中的方案,但应该说是一个很通用的方案,因为它的成功与否,基本就取决于自己电脑的锐捷客户端而已。看到这个方案,我就知道有戏了,于是赶紧补习了一下交叉编译的知识,最后成功编译好了,并且在路由上成功地完成了认证。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 78168位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
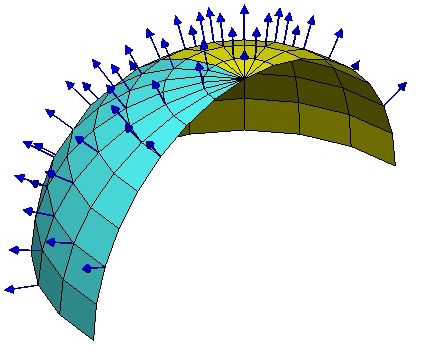
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
14
Oct
【理解黎曼几何】1. 一条几何之路
By 苏剑林 | 2016-10-14 | 79951位读者 | 引用一个月没更新了,这个月花了不少时间在黎曼几何的理解方面,有一些体会,与大家分享。记得当初孟岩写的《理解矩阵》,和笔者所写的《新理解矩阵》,读者反响都挺不错的,这次沿用了这个名称,称之为《理解黎曼几何》。

生活在二维空间的蚂蚁
黎曼几何是研究内蕴几何的几何分支。通俗来讲,就是我们可能生活在弯曲的空间中,比如一只生活在二维球面的蚂蚁,作为生活在弯曲空间中的个体,我们并没有足够多的智慧去把我们的弯曲嵌入到更高维的空间中去研究,就好比蚂蚁只懂得在球面上爬,不能从“三维空间的曲面”这一观点来认识球面,因为球面就是它们的世界。因此,我们就有了内蕴几何,它告诉我们,即便是身处弯曲空间中,我们依旧能够测量长度、面积、体积等,我们依旧能够算微分、积分,甚至我们能够发现我们的空间是弯曲的!也就是说,身处球面的蚂蚁,只要有足够的智慧,它们就能发现曲面是弯曲的——跟哥伦布环球航行那样——它们朝着一个方向走,最终却回到了起点,这就可以断定它们自身所处的空间必然是弯曲的——这个发现不需要用到三维空间的知识。
15
Oct
【理解黎曼几何】3. 测地线
By 苏剑林 | 2016-10-15 | 54794位读者 | 引用测地线
黎曼度量应该是不难理解的,在微分几何的教材中,我们就已经学习过曲面的“第一基本形式”了,事实上两者是同样的东西,只不过看待问题的角度不同,微分几何是把曲面看成是三维空间中的二维子集,而黎曼几何则是从二维曲面本身内蕴地研究几何问题。
几何关心什么问题呢?事实上,几何关心的是与变换无关的“客观实体”(或者说是在变换之下不变的东西),这也是几何的定义。根据Klein提出的《埃尔朗根纲领》,几何就是研究在某种变换(群)下的不变性质的学科。如果把变换局限为刚性变换(平移、旋转、反射),那么就是欧式几何;如果变换为一般的线性变换,那就是仿射几何。而黎曼几何关心的是与一切坐标都无关的客观实体。比如说,我有一个向量,方向和大小都确定了,在直角坐标系是$(1, 1)$,在极坐标系是$(\sqrt{2}, \pi/4)$,虽然两个坐标系下的分量不同,但它们都是指代同一个向量。也就是说向量本身是客观存在的实体,跟所使用的坐标无关。从代数层面看,就是只要能够通过某种坐标变换相互得到的,我们就认为它们是同一个东西。
因此,在学习黎曼几何时,往“客观实体”方向思考,总是有益的。

平面上的测地线
有了度规,可以很自然地引入“测地线”这一实体。狭义来看,它就是两点间的最短线——是平直空间的直线段概念的推广(实际的测地线不一定是最短的,但我们先不纠结细节,而且这不妨碍我们理解它,因为测地线至少是局部最短的)。不难想到,只要两点确定了,那么不管使用什么坐标,两点间的最短线就已经确定了,因此这显然是一个客观实体。有一个简单的类比,就是不管怎么坐标变换,一个函数$f(x)$的图像极值点总是确定的——不管你变还是不变,它就在那儿,不偏不倚。
21
Oct
【理解黎曼几何】7. 高斯-博内公式
By 苏剑林 | 2016-10-21 | 37728位读者 | 引用令人兴奋的是,我们导出黎曼曲率的途径,还能够让我们一瞥高斯-博内公式( Gauss–Bonnet formula)的风采,真正体验一番研究内蕴几何的味道。
高斯-博内公式是大范围微分几何学的一个经典的公式,它建立了空间的局部性质和整体性质之间的联系。而我们从一条几何的路径出发,结合一些矩阵变换和数学分析的内容,逐步导出了测地线、协变导数、曲率张量,现在可以还可以得到经典的高斯-博内公式,可见我们在这条路上已经走得足够远了。虽然过程不尽善尽美,然而并没有脱离这个系列的核心:几何直观。本文的目的,正是分享黎曼几何的一种直观思路,既然是思路,以思想交流为主,不以严格证明为目的。因此,对于大家来说,这个系列权当黎曼几何的补充材料吧。
形式改写
首先,我们可以将式$(48)$重写为更有几何意义的形式。从
4
Nov
【外微分浅谈】1. 绪论与启发
By 苏剑林 | 2016-11-04 | 25404位读者 | 引用写在前面
在《理解黎曼几何》系列,笔者分享了一些黎曼几何的“几何”心得,同时遗留了一个问题:怎么真正地去算黎曼张量?MTW的《引力论》中提到了一种基于外微分的方法,可是我不熟悉外微分,遂学习了一番。确实,是《引力论》中快捷计算曲率张量的步骤让笔者决定深入了解外微分的。果然,可观的效益是第一推动力。
这系列文章主要分享一些外微分的学习心得,曾经过多次修改和完善,包含的内容很多,比如外积、活动标架、外微分及其在黎曼几何的一些应用等,最后包括一种计算曲率的有效方式。
符号说明:在本系列中,用粗体的字母表示向量、矩阵以及基底,用普通字母来表示标量,它有可能是一个标量函数,也有可能是向量的分量,如无说明,则用$n$表示空间(流形)的维度。本文中同样使用了爱因斯坦求和法则,即相同的上下指标表示$1\sim n$遍历求和,即$\alpha_{\mu}\beta^{\mu}=\sum_{\mu=1}^{n} \alpha_{\mu}\beta^{\mu}$,习惯上将下标写在前面,比如$\alpha_{\mu}\beta^{\mu}$事实上跟$\beta^{\mu}\alpha_{\mu}$等价,但习惯写成前者。常用的一些记号是:$\mu,\nu$表示分量指标,$x^{\mu}$表示点的坐标分量,$dx^{\mu}$表示切向量(微元)的分量,$\alpha,\beta,\omega$等希腊字母也常用来表示微分形式。符号的使用有重复的地方,但符号的意义基本都在符号出现的附近有说明,因此应该不至于混淆。
最后,就是笔者其实对外微分还不是特别有感觉,因此文章中可能出现谬误之处,请读者见谅并指出。本系列命名为“外微分浅谈”,不是谦虚,确实是很浅,认识得浅,说的也很浅~

最近评论