






20
Apr
你的语言模型有没有“无法预测的词”?
By 苏剑林 | 2022-04-20 | 22721位读者 | 引用众所周知,分类模型通常都是先得到编码向量,然后接一个Dense层预测每个类别的概率,而预测时则是输出概率最大的类别。但大家是否想过这样一种可能:训练好的分类模型可能存在“无法预测的类别”,即不管输入是什么,都不可能预测出某个类别$k$,类别$k$永远不可能成为概率最大的那个。
当然,这种情况一般只出现在类别数远远超过编码向量维度的场景,常规的分类问题很少这么极端的。然而,我们知道语言模型本质上也是一个分类模型,它的类别数也就是词表的总大小,往往是远超过向量维度的,那么我们的语言模型是否有“无法预测的词”?(只考虑Greedy解码)
是否存在
ACL2022的论文《Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice》首先探究了这个问题,正如其标题所言,答案是“理论上存在但实际出现概率很小”。
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 162018位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
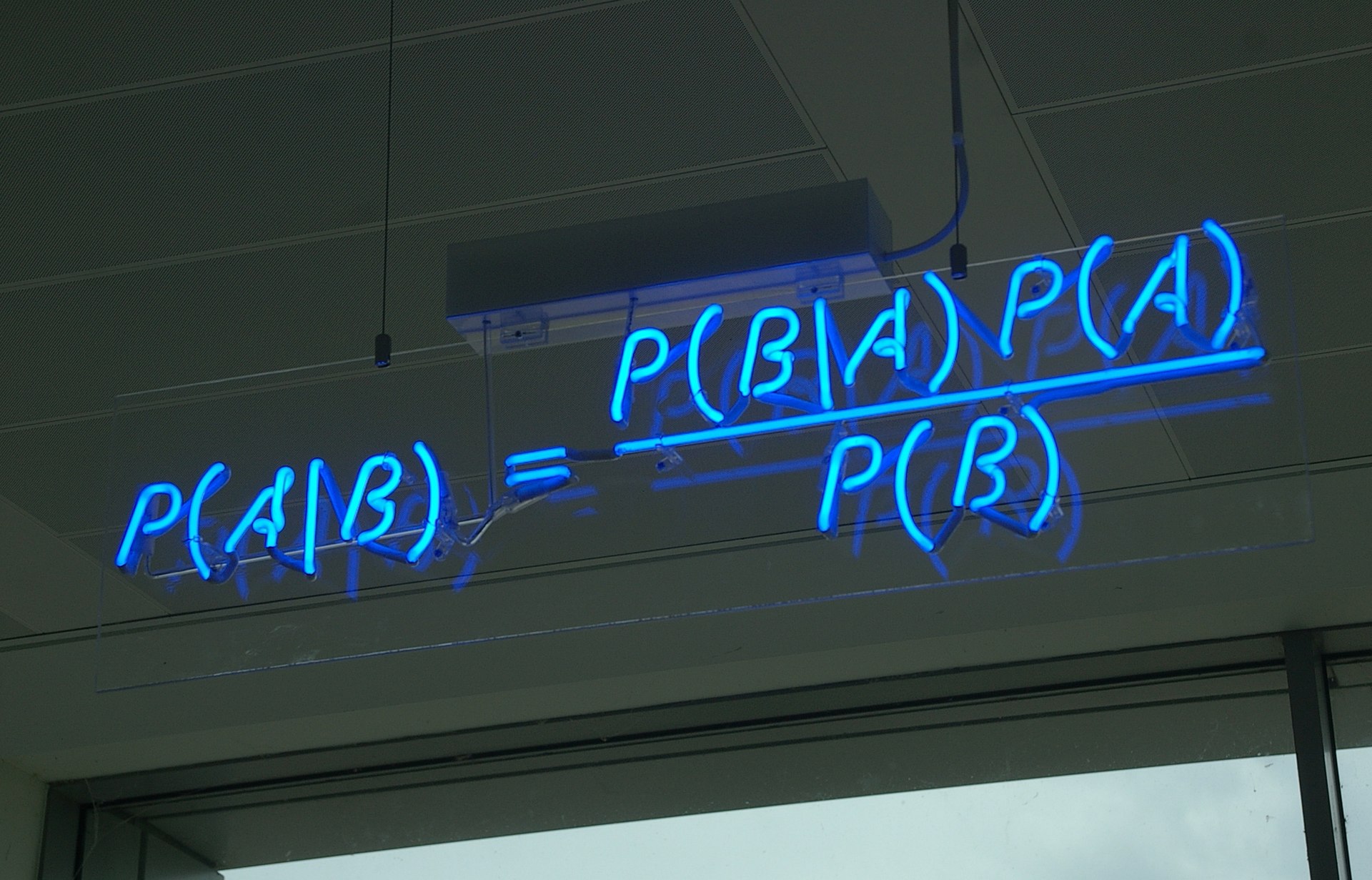
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
8
Aug
生成扩散模型漫谈(六):一般框架之ODE篇
By 苏剑林 | 2022-08-08 | 123708位读者 | 引用上一篇文章《生成扩散模型漫谈(五):一般框架之SDE篇》中,我们对宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》做了基本的介绍和推导。然而,顾名思义,上一篇文章主要涉及的是原论文中SDE相关的部分,而遗留了被称为“概率流ODE(Probability flow ODE)”的部分内容,所以本文对此做个补充分享。
事实上,遗留的这部分内容在原论文的正文中只占了一小节的篇幅,但我们需要新开一篇文章来介绍它,因为笔者想了很久后发现,该结果的推导还是没办法绕开Fokker-Planck方程,所以我们需要一定的篇幅来介绍Fokker-Planck方程,然后才能请主角ODE登场。
再次反思
我们来大致总结一下上一篇文章的内容:首先,我们通过SDE来定义了一个前向过程(“拆楼”):
\begin{equation}d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\label{eq:sde-forward}\end{equation}
23
May
NBCE:使用朴素贝叶斯扩展LLM的Context处理长度
By 苏剑林 | 2023-05-23 | 89298位读者 | 引用在LLM时代还玩朴素贝叶斯(Naive Bayes)?
这可能是许多读者在看到标题后的首个想法。确实如此,当古老的朴素贝叶斯与前沿的LLM相遇时,产生了令人惊讶的效果——我们可以直接扩展现有LLM模型的Context处理长度,无需对模型进行微调,也不依赖于模型架构,具有线性效率,而且效果看起来还不错——这就是本文所提出的NBCE(Naive Bayes-based Context Extension)方法。
摸石过河
假设$T$为要生成的token序列,$S_1,S_2,\cdots,S_n$是给定的若干个相对独立的Context集合(比如$n$个不同的段落,至少不是一个句子被分割为两个片段那种),假设它们的总长度已经超过了训练长度,而单个$S_k$加$T$还在训练长度内。我们需要根据$S_1,S_2,\cdots,S_n$生成$T$,即估计$p(T|S_1, S_2,\cdots,S_n)$。
13
Sep
大词表语言模型在续写任务上的一个问题及对策
By 苏剑林 | 2023-09-13 | 34964位读者 | 引用对于LLM来说,通过增大Tokenizer的词表来提高压缩率,从而缩短序列长度、降低解码成本,是大家都喜闻乐见的事情。毕竟增大词表只需要增大Embedding层和输出的Dense层,这部分增加的计算量几乎不可感知,但缩短序列长度之后带来的解码速度提升却是实打实的。当然,增加词表大小也可能会对模型效果带来一些负面影响,所以也不能无节制地增加词表大小。本文就来分析增大词表后语言模型在续写任务上会出现的一个问题,并提出参考的解决方案。
优劣分析
增加词表大小的好处是显而易见的。一方面,由于LLM是自回归的,它的解码会越来越慢,而“增大词表 → 提高压缩率 → 缩短序列长度”,换言之相同文本对应的tokens数变少了,也就是解码步数变少了,从而解码速度提升了;另一方面,语言模型的训练方式是Teacher Forcing,缩短序列长度能够缓解Teacher Forcing带来的Exposure Bias问题,从而可能提升模型效果。
20
Sep
自然数集中 N = ab + c 时 a + b + c 的最小值
By 苏剑林 | 2023-09-20 | 41969位读者 | 引用前天晚上微信群里有群友提出了一个问题:
对于一个任意整数$N > 100$,求一个近似算法,使得$N=a\times b+c$(其中$a,b,c$都是非负整数),并且令$a+b+c$尽量地小。
初看这道题,笔者第一感觉就是“这还需要算法?”,因为看上去自由度太大了,应该能求出个解析解才对,于是简单分析了一下之后就给出了个“答案”,结果很快就有群友给出了反例。这时,笔者才意识到这题并非那么平凡,随后正式推导了一番,总算得到了一个可行的算法。正当笔者以为这个问题已经结束时,另一个数学群的群友精妙地构造了新的参数化,证明了算法的复杂度还可以进一步下降!
整个过程波澜起伏,让笔者获益匪浅,遂将过程记录在此,与大家分享。
23
Apr
生成扩散模型漫谈(二十四):少走捷径,更快到达
By 苏剑林 | 2024-04-23 | 35727位读者 | 引用如何减少采样步数同时保证生成质量,是扩散模型应用层面的一个关键问题。其中,《生成扩散模型漫谈(四):DDIM = 高观点DDPM》介绍的DDIM可谓是加速采样的第一次尝试。后来,《生成扩散模型漫谈(五):一般框架之SDE篇》、《生成扩散模型漫谈(五):一般框架之ODE篇》等所介绍的工作将扩散模型与SDE、ODE联系了起来,于是相应的数值积分技术也被直接用于扩散模型的采样加速,其中又以相对简单的ODE加速技术最为丰富,我们在《生成扩散模型漫谈(二十一):中值定理加速ODE采样》也介绍过一例。
这篇文章我们介绍另一个特别简单有效的加速技巧——Skip Tuning,出自论文《The Surprising Effectiveness of Skip-Tuning in Diffusion Sampling》,准确来说它是配合已有的加速技巧使用,来一步提高采样质量,这就意味着在保持相同采样质量的情况下,它可以进一步压缩采样步数,从而实现加速。
19
Sep
Softmax后传:寻找Top-K的光滑近似
By 苏剑林 | 2024-09-19 | 32196位读者 | 引用Softmax,顾名思义是“soft的max”,是$\max$算子(准确来说是$\text{argmax}$)的光滑近似,它通过指数归一化将任意向量$\boldsymbol{x}\in\mathbb{R}^n$转化为分量非负且和为1的新向量,并允许我们通过温度参数来调节它与$\text{argmax}$(的one hot形式)的近似程度。除了指数归一化外,我们此前在《通向概率分布之路:盘点Softmax及其替代品》也介绍过其他一些能实现相同效果的方案。
我们知道,最大值通常又称Top-1,它的光滑近似方案看起来已经相当成熟,那读者有没有思考过,一般的Top-$k$的光滑近似又是怎么样的呢?下面让我们一起来探讨一下这个问题。
问题描述
设向量$\boldsymbol{x}=(x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$,简单起见我们假设它们两两不相等,即$i\neq j \Leftrightarrow x_i\neq x_j$。记$\Omega_k(\boldsymbol{x})$为$\boldsymbol{x}$最大的$k$个分量的下标集合,即$|\Omega_k(\boldsymbol{x})|=k$以及$\forall i\in \Omega_k(\boldsymbol{x}), j \not\in \Omega_k(\boldsymbol{x})\Rightarrow x_i > x_j$。我们定义Top-$k$算子$\mathcal{T}_k$为$\mathbb{R}^n\mapsto\{0,1\}^n$的映射:
\begin{equation}
[\mathcal{T}_k(\boldsymbol{x})]_i = \left\{\begin{aligned}1,\,\, i\in \Omega_k(\boldsymbol{x}) \\ 0,\,\, i \not\in \Omega_k(\boldsymbol{x})\end{aligned}\right.
\end{equation}
说白了,如果$x_i$属于最大的$k$个元素之一,那么对应的位置变成1,否则变成0,最终结果是一个Multi-Hot向量,比如$\mathcal{T}_2([3,2,1,4]) = [1,0,0,1]$。

最近评论