






28
Mar
Google新作试图“复活”RNN:RNN能否再次辉煌?
By 苏剑林 | 2023-03-28 | 54435位读者 | 引用当前,像ChatGPT之类的LLM可谓是“风靡全球”。有读者留意到,几乎所有LLM都还是用最初的Multi-Head Scaled-Dot Attention,近年来大量的Efficient工作如线性Attention、FLASH等均未被采用。是它们版本效果太差,还是根本没有必要考虑效率?其实答案笔者在《线性Transformer应该不是你要等的那个模型》已经分析过了,只有序列长度明显超过hidden size时,标准Attention才呈现出二次复杂度,在此之前它还是接近线性的,它的速度比很多Efficient改进都快,而像GPT3用到了上万的hidden size,这意味着只要你的LLM不是面向数万长度的文本生成,那么用Efficient改进是没有必要的,很多时候速度没提上去,效果还降低了。
那么,真有数万甚至数十万长度的序列处理需求时,我们又该用什么模型呢?近日,Google的一篇论文《Resurrecting Recurrent Neural Networks for Long Sequences》重新优化了RNN模型,特别指出了RNN在处理超长序列场景下的优势。那么,RNN能否再次辉煌?
26
Sep
脑洞大开:非线性RNN居然也可以并行计算?
By 苏剑林 | 2023-09-26 | 49144位读者 | 引用近年来,线性RNN由于其可并行训练以及常数推理成本等特性,吸引了一定研究人员的关注(例如笔者之前写的《Google新作试图“复活”RNN:RNN能否再次辉煌?》),这让RNN在Transformer遍地开花的潮流中仍有“一席之地”。然而,目前看来这“一席之地”只属于线性RNN,因为非线性RNN无法高效地并行训练,所以在架构之争中是“心有余而力不足”。
不过,一篇名为《Parallelizing Non-Linear Sequential Models over the Sequence Length》的论文有不同的看法,它提出了一种迭代算法,宣传可以实现非线性RNN的并行训练!真有如此神奇?接下来我们一探究竟。
求不动点
原论文对其方法做了非常一般的介绍,而且其侧重点是PDE和ODE,这里我们直接从RNN入手。考虑常见的简单非线性RNN:
\begin{equation}x_t = \tanh(Ax_{t-1} + u_t)\label{eq:rnn}\end{equation}
25
Dec
写了个刷论文的辅助网站:Cool Papers
By 苏剑林 | 2023-12-25 | 81652位读者 | 引用写在开头
一直以来,笔者都有日刷Arxiv的习惯,以求尽可能跟上领域内最新成果,并告诫自己“不进则退”。之前也有不少读者问我是怎么刷Arxiv的、有什么辅助工具等,但事实上,在很长的时间里,笔者都是直接刷Arxiv官网,并且没有用任何算法过滤,都是自己一篇篇过的。这个过程很枯燥,但并非不能接受,之所以不用算法初筛,主要还是担心算法漏召,毕竟“刷”就是为了追新,一旦算法漏召就“错失先机”了。
自从Kimi Chat发布后,笔者就一直计划着写一个辅助网站结合Kimi来加速刷论文的过程。最近几个星期稍微闲了一点,于是在GPT4、Kimi的帮助下,初步写成了这个网站,并且经过几天的测试和优化后,已经逐步趋于稳定,于是正式邀请读者试用。
Cool Papers:https://papers.cool
7
Mar
用傅里叶级数拟合一维概率密度函数
By 苏剑林 | 2024-03-07 | 28908位读者 | 引用在《“闭门造车”之多模态思路浅谈(一):无损输入》中我们曾提到,图像生成的本质困难是没有一个连续型概率密度的万能拟合器。当然,也不能说完全没有,比如高斯混合模型(GMM)理论上就是可以拟合任意概率密度,就连GAN本质上也可以理解为混合了无限个高斯模型的GMM。然而,GMM尽管理论上的能力是足够的,但它的最大似然估计会很困难,尤其是通常不适用基于梯度的优化器,这限制了它的使用场景。
近日,Google的一篇新论文《Fourier Basis Density Model》针对一维情形,提出了一个新的解决方案——用傅里叶级数来拟合。论文的分析过程颇为有趣,构造形式也很是巧妙,值得学习一番。
问题简述
可能有读者质疑:只研究一维情形有什么价值?确实,如果只考虑图像生成场景,那可能真的价值有限,但一维概率密度估计本身有它的应用价值,如数据的有损压缩,所以它依然是一个值得研究的主题。再者,即便我们需要研究多维的概率密度,也可以通过自回归的方式转化为多个一维的条件概率密度来估计。最后,这个分析和构造过程本身就很值得回味,所以哪怕是仅仅作为一道数学分析题来练习也是相当有益的。
7
May
Cool Papers更新:简单搭建了一个站内检索系统
By 苏剑林 | 2024-05-07 | 31112位读者 | 引用自从《更便捷的Cool Papers打开方式:Chrome重定向扩展》之后,Cool Papers有两次比较大的变化,一次是引入了venue分支,逐步收录了一些会议历年的论文集,如ICLR、ICML等,这部分是动态人工扩充的,欢迎有心仪的会议的读者提更多需求;另一次就是本文的主题,前天新增加的站内检索功能。
本文将简单介绍一下新增功能,并对搭建站内检索系统的过程做个基本总结。
简介
在Cool Papers的首页,我们看到搜索入口:

Cool Papers(2024.05.07)
18
Mar
时空之章:将Attention视为平方复杂度的RNN
By 苏剑林 | 2024-03-18 | 39859位读者 | 引用近年来,RNN由于其线性的训练和推理效率,重新吸引了不少研究人员和用户的兴趣,隐约有“文艺复兴”之势,其代表作有RWKV、RetNet、Mamba等。当将RNN用于语言模型时,其典型特点就是每步生成都是常数的空间复杂度和时间复杂度,从整个序列看来就是常数的空间复杂度和线性的时间复杂度。当然,任何事情都有两面性,相比于Attention动态增长的KV Cache,RNN的常数空间复杂度通常也让人怀疑记忆容量有限,在Long Context上的效果很难比得上Attention。
在这篇文章中,我们表明Causal Attention可以重写成RNN的形式,并且它的每一步生成理论上也能够以$\mathcal{O}(1)$的空间复杂度进行(代价是时间复杂度非常高,远超平方级)。这表明Attention的优势(如果有的话)是靠计算堆出来的,而不是直觉上的堆内存,它跟RNN一样本质上都是常数量级的记忆容量(记忆瓶颈)。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 18549位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
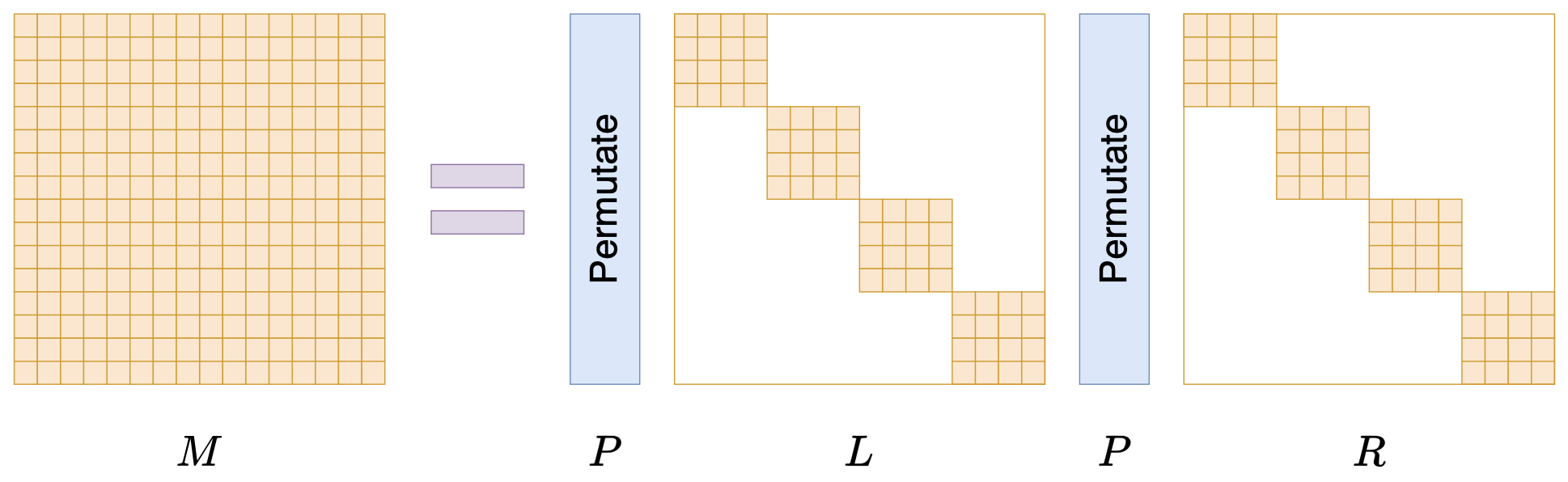
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
6
Aug
通向最优分布之路:概率空间的最小化
By 苏剑林 | 2024-08-06 | 15633位读者 | 引用当要求函数的最小值时,我们通常会先求导函数然后寻找其零点,比较幸运的情况下,这些零点之一正好是原函数的最小值点。如果是向量函数,则将导数改为梯度并求其零点。当梯度零点不易求得时,我们可以使用梯度下降来逐渐逼近最小值点。
以上这些都是无约束优化的基础结果,相信不少读者都有所了解。然而,本文的主题是概率空间中的优化,即目标函数的输入是一个概率分布,这类目标的优化更为复杂,因为它的搜索空间不再是无约束的,如果我们依旧去求解梯度零点或者执行梯度下降,所得结果未必能保证是一个概率分布。因此,我们需要寻找一种新的分析和计算方法,以确保优化结果能够符合概率分布的特性。
对此,笔者一直以来也感到颇为头疼,所以近来决定”痛定思痛“,针对概率分布的优化问题系统学习了一番,最后将学习所得整理在此,供大家参考。

最近评论