






30
May
最小熵原理(三):“飞象过河”之句模版和语言结构
By 苏剑林 | 2018-05-30 | 63700位读者 | 引用在前一文《最小熵原理(二):“当机立断”之词库构建》中,我们以最小熵原理为出发点进行了一系列的数学推导,最终得到$(2.15)$和$(2.17)$式,它告诉我们两个互信息比较大的元素我们应该将它们合并起来,这有利于降低“学习难度”。于是利用这一原理,我们通过邻字互信息来实现了词库的无监督生成。
由字到词、由词到词组,考察的是相邻的元素能不能合并成一个好“套路”。可是套路为什么非得要相邻的呢?当然不一定相邻,我们学习语言的时候,不仅仅会学习到词语、词组,还要学习到“固定搭配”,也就是说词语怎么运用才是合理的,这是语法的体现,是本文所要探究的,希望最终能达到一定的无监督句法分析的效果。
由于这次我们考虑的是跨邻词的语言关联,因此我给它起个名字为“飞象过河”,正是
“套路宝典”第二式——“飞象过河”
语言结构
对于大多数人来说,并不会真正知道什么是语法,他们脑海里就只有一些“固定搭配”、“定式”,或者更正式一点可以叫“模版”。大多数情况下,我们是根据模版来说出合理的话来。而不同的人的说话模版可能有所不同,这就是个人的说话风格,甚至是“口头禅”。
29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 155484位读者 | 引用在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 94030位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
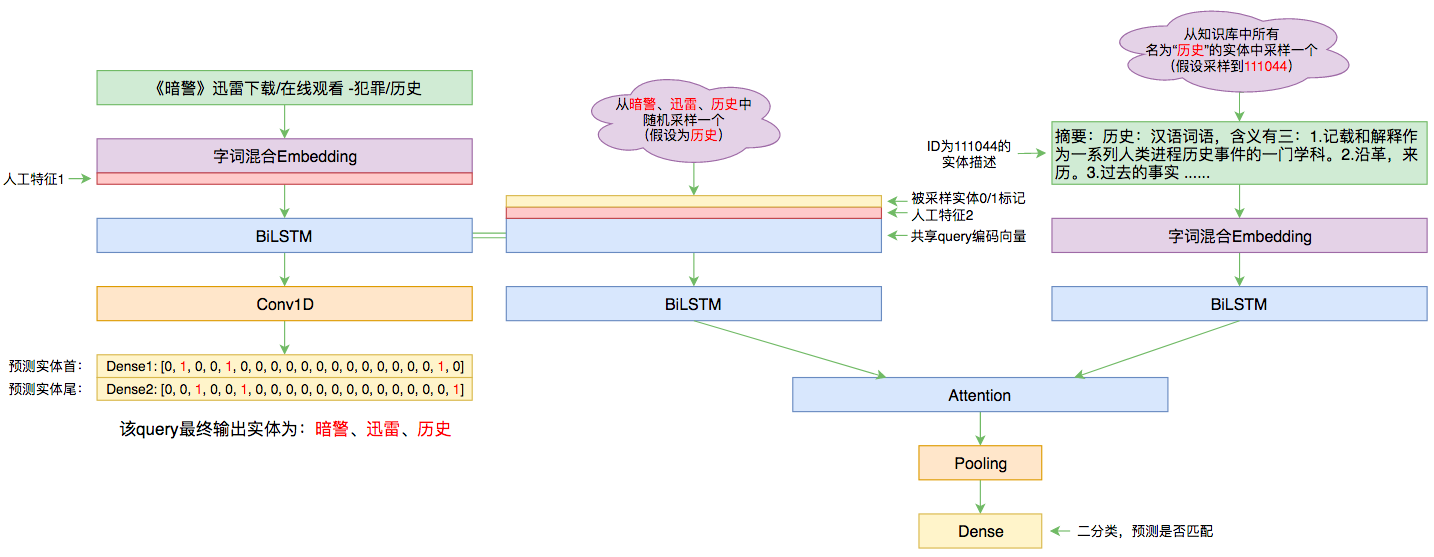
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
6
Jan
获取并处理中文维基百科语料
By 苏剑林 | 2017-01-06 | 117560位读者 | 引用中文语料库中,质量高而又容易获取的语料库,应该就是维基百科的中文语料了,而且维基百科相当厚道,每个月都把所有条目都打包一次(下载地址在这里:https://dumps.wikimedia.org/zhwiki/),供全世界使用,这才是真正的“取之于民,回馈于民”呀。遗憾的是,由于天朝的无理封锁,中文维基百科的条目到目前只有91万多条,而百度百科、互动百科都有千万条了(英文维基百科也有上千万了)。尽管如此,这并没有阻挡中文维基百科成为几乎是最高质量的中文语料库。(百度百科、互动百科它们只能自己用爬虫爬取,而且不少记录质量相当差,几乎都是互相复制甚至抄袭。)
门槛
尽量下载很容易,但是使用维基百科语料还是有一定门槛的。直接下载下来的维基百科语料是一个带有诸多html和markdown标记的文本压缩包,基本不能直接使用。幸好,已经有热心的高手为我们写好了处理工具,主要有两个:1、Wikipedia Extractor;2、gensim的wikicorpus库。它们都是基于python的。
然而,这两个主流的处理方法都不能让我满意。首先,Wikipedia Extractor提取出来的结果,会去掉{{}}标记的内容,这样会导致下面的情形
西方语言中“数学”(;)一词源自于古希腊语的()
24
Apr
【语料】2500万中文三元组!
By 苏剑林 | 2017-04-24 | 95947位读者 | 引用闲聊
这两年,知识图谱、问答系统、聊天机器人等领域是越来越火了。知识图谱是一个很泛化的概念,在我看来,涉及到知识库的构建、检索、利用等机器学习相关的内容,都算知识图谱。当然,这也不是个什么定义,只是个人的直观感觉。
做知识图谱的读者都知道,三元组是结构化知识的一种方法,是做知识型问答系统的重要组成部分。对于英文领域,已经有一些较大的开源的三元组语料库,而很显然,中文目前还没有这样的语料库共享(哪怕有人爬取到了,也珍藏起来了)。笔者前段时间写了个百度百科的爬虫,爬了一段时间,抓了几百万个百度百科的词条。其中不少词条含有一些结构化的信息,直接抽取出来,就是有效的“三元组”了,可以用来做知识图谱。本文分享的三元组语料正是由此而来,共有2500万个三元组。

百度百科的三元组
26
Apr
中文任务还是SOTA吗?我们给SimCSE补充了一些实验
By 苏剑林 | 2021-04-26 | 259449位读者 | 引用今年年初,笔者受到BERT-flow的启发,构思了成为“BERT-whitening”的方法,并一度成为了语义相似度的新SOTA(参考《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,论文为《Whitening Sentence Representations for Better Semantics and Faster Retrieval》)。然而“好景不长”,在BERT-whitening提交到Arxiv的不久之后,Arxiv上出现了至少有两篇结果明显优于BERT-whitening的新论文。
第一篇是《Generating Datasets with Pretrained Language Models》,这篇借助模板从GPT2_XL中无监督地构造了数据对来训练相似度模型,个人认为虽然有一定的启发而且效果还可以,但是复现的成本和变数都太大。另一篇则是本文的主角《SimCSE: Simple Contrastive Learning of Sentence Embeddings》,它提出的SimCSE在英文数据上显著超过了BERT-flow和BERT-whitening,并且方法特别简单~
那么,SimCSE在中文上同样有效吗?能大幅提高中文语义相似度的效果吗?本文就来做些补充实验。
26
Oct
新词发现的信息熵方法与实现
By 苏剑林 | 2015-10-26 | 118710位读者 | 引用在本博客的前面文章中,已经简单提到过中文文本处理与挖掘的问题了,中文数据挖掘与英语同类问题中最大的差别是,中文没有空格,如果要较好地完成语言任务,首先得分词。目前流行的分词方法都是基于词库的,然而重要的问题就来了:词库哪里来?人工可以把一些常用的词语收集到词库中,然而这却应付不了层出不穷的新词,尤其是网络新词等——而这往往是语言任务的关键地方。因此,中文语言处理很核心的一个任务就是完善新词发现算法。
新词发现说的就是不加入任何先验素材,直接从大规模的语料库中,自动发现可能成词的语言片段。前两天我去小虾的公司膜拜,并且试着加入了他们的一个开发项目中,主要任务就是网络文章处理。因此,补习了一下新词发现的算法知识,参考了Matrix67.com的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》,尤其是里边的信息熵思想,并且根据他的思路,用Python写了个简单的脚本。
3
Apr
【不可思议的Word2Vec】 2.训练好的模型
By 苏剑林 | 2017-04-03 | 473863位读者 | 引用由于后面几篇要讲解Word2Vec怎么用,因此笔者先训练好了一个Word2Vec模型。为了节约读者的时间,并且保证读者可以复现后面的结果,笔者决定把这个训练好的模型分享出来,用Gensim训练的。单纯的词向量并不大,但第一篇已经说了,我们要用到完整的Word2Vec模型,因此我将完整的模型分享出来了,包含四个文件,所以文件相对大一些。
提醒读者的是,如果你想获取完整的Word2Vec模型,又不想改源代码,那么Python的Gensim库应该是你唯一的选择,据我所知,其他版本的Word2Vec最后都是只提供词向量给我们,没有完整的模型。
对于做知识挖掘来说,显然用知识库语料(如百科语料)训练的Word2Vec效果会更好。但百科语料我还在爬取中,爬完了我再训练一个模型,到时再分享。
模型概况
这个模型的大概情况如下:
$$\begin{array}{c|c}
\hline
\text{训练语料} & \text{微信公众号的文章,多领域,属于中文平衡语料}\\
\hline
\text{语料数量} & \text{800万篇,总词数达到650亿}\\
\hline
\text{模型词数} & \text{共352196词,基本是中文词,包含常见英文词}\\
\hline
\text{模型结构} & \text{Skip-Gram + Huffman Softmax}\\
\hline
\text{向量维度} & \text{256维}\\
\hline
\text{分词工具} & \text{结巴分词,加入了有50万词条的词典,关闭了新词发现}\\
\hline
\text{训练工具} & \text{Gensim的Word2Vec,服务器训练了7天}\\
\hline
\text{其他情况} & \text{窗口大小为10,最小词频是64,迭代了10次}\\
\hline
\end{array}$$

最近评论