






15
Dec
生成扩散模型漫谈(十四):构建ODE的一般步骤(上)
By 苏剑林 | 2022-12-15 | 69992位读者 | 引用书接上文,在《生成扩散模型漫谈(十三):从万有引力到扩散模型》中,我们介绍了一个由万有引力启发的、几何意义非常清晰的ODE式生成扩散模型。有的读者看了之后就疑问:似乎“万有引力”并不是唯一的选择,其他形式的力是否可以由同样的物理绘景构建扩散模型?另一方面,该模型在物理上确实很直观,但还欠缺从数学上证明最后确实能学习到数据分布。
本文就尝试从数学角度比较精确地回答“什么样的力场适合构建ODE式生成扩散模型”这个问题。
基础结论
要回答这个问题,需要用到在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》中我们推导过的一个关于常微分方程对应的分布变化的结论。
考虑$\boldsymbol{x}_t\in\mathbb{R}^d, t\in[0,T]$的一阶(常)微分方程(组)
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq:ode}\end{equation}
28
Dec
Transformer升级之路:6、旋转位置编码的完备性分析
By 苏剑林 | 2022-12-28 | 47415位读者 | 引用在去年的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中,笔者提出了旋转位置编码(RoPE),当时的出发点只是觉得用绝对位置来实现相对位置是一件“很好玩的事情”,并没料到其实际效果还相当不错,并为大家所接受,不得不说这真是一个意外之喜。后来,在《Transformer升级之路:4、二维位置的旋转式位置编码》中,笔者讨论了二维形式的RoPE,并研究了用矩阵指数表示的RoPE的一般解。
既然有了一般解,那么自然就会引出一个问题:我们常用的RoPE,只是一个以二维旋转矩阵为基本单元的分块对角矩阵,如果换成一般解,理论上效果会不会更好呢?本文就来回答这个问题。
指数通解
在《Transformer升级之路:4、二维位置的旋转式位置编码》中,我们将RoPE抽象地定义为任意满足下式的方阵
\begin{equation}\boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n=\boldsymbol{\mathcal{R}}_{n-m}\label{eq:re}\end{equation}
4
Jan
智能家居之热水器零冷水技术原理浅析
By 苏剑林 | 2023-01-04 | 56464位读者 | 引用如果家庭使用单一的热水器集中供热水,那么当我们想要用热水时,往往需要先放一段时间的冷水,而如果放冷水时间比较长的话,就会比较影响体验。所谓零冷水,实际上就是想办法提前把热水管中的冷水排放掉,以达到(几乎)瞬间出热水的效果。事实上,零冷水并不是什么高大上的技术,但可能由于观念没跟上、理解上有误等原因,零冷水技术还没有在家庭中得到普及,不过随着大家对生活品质的要求越来越高,零冷水确实在慢慢流行起来了。
本文来简单分析一下零冷水技术的实现原理,包括各种方案的优缺点和自省DIY的参考思路。
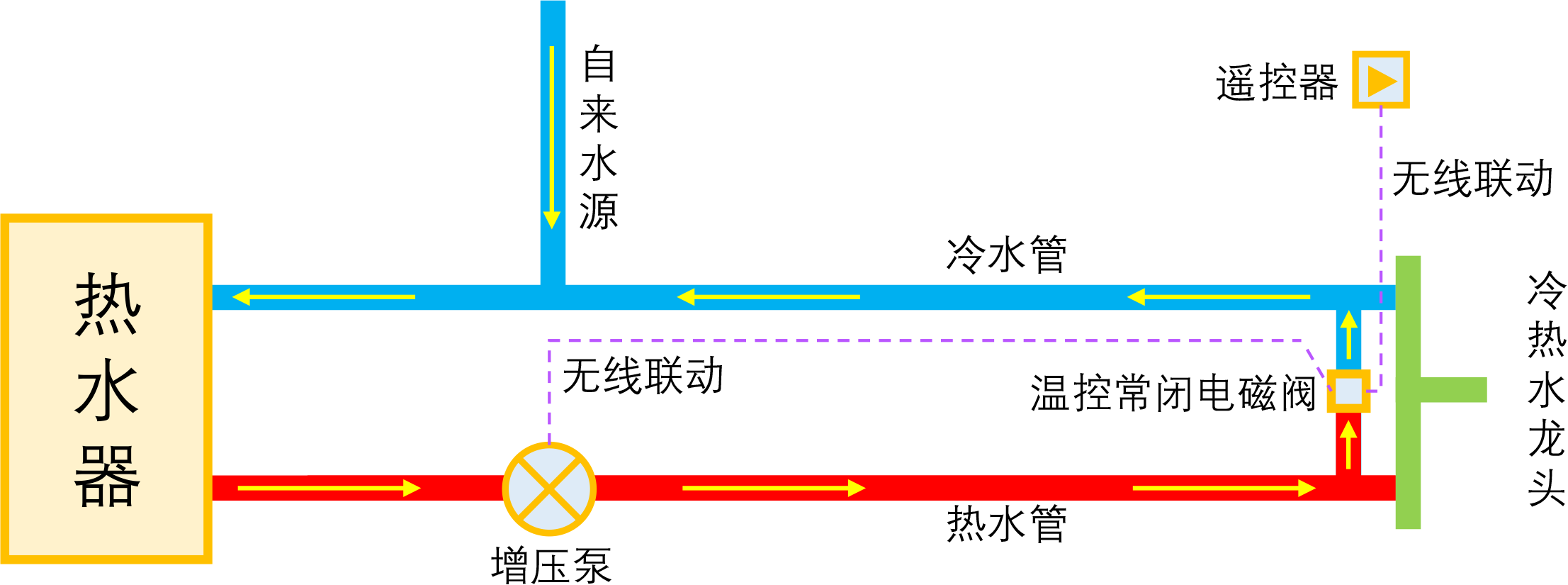
理想的零冷水方案
写在前面
在文章开始,需要纠正很多人的一个错误观念:零冷水不是为了省钱,而是为了提升生活品质。如果你是省钱最大的心态,那么接下来的内容就可以不用看了,零冷水技术对你毫无价值。
25
Apr
注意力和Softmax的两点有趣发现:鲁棒性和信息量
By 苏剑林 | 2023-04-25 | 36106位读者 | 引用最近几周笔者一直都在思考注意力机制的相关性质,在这个过程中对注意力及Softmax有了更深刻的理解。在这篇文章中,笔者简单分享其中的两点:
1、Softmax注意力天然能够抵御一定的噪声扰动;
2、从信息熵角度也可以对初始化问题形成直观理解。
鲁棒性
基于Softmax归一化的注意力机制,可以写为
\begin{equation}o = \frac{\sum\limits_{i=1}^n e^{s_i} v_i}{\sum\limits_{i=1}^n e^{s_i}}\end{equation}
有一天笔者突然想到一个问题:如果往$s_i$中加入独立同分布的噪声会怎样?
17
Apr
梯度视角下的LoRA:简介、分析、猜测及推广
By 苏剑林 | 2023-04-17 | 90625位读者 | 引用随着ChatGPT及其平替的火热,各种参数高效(Parameter-Efficient)的微调方法也“水涨船高”,其中最流行的方案之一就是本文的主角LoRA了,它出自论文《LoRA: Low-Rank Adaptation of Large Language Models》。LoRA方法上比较简单直接,而且也有不少现成实现,不管是理解还是使用都很容易上手,所以本身也没太多值得细写的地方了。
然而,直接实现LoRA需要修改网络结构,这略微麻烦了些,同时LoRA给笔者的感觉是很像之前的优化器AdaFactor,所以笔者的问题是:能否从优化器角度来分析和实现LoRA呢?本文就围绕此主题展开讨论。
方法简介
以往的一些结果(比如《Exploring Aniversal Intrinsic Task Subspace via Prompt Tuning》)显示,尽管预训练模型的参数量很大,但每个下游任务对应的本征维度(Intrinsic Dimension)并不大,换句话说,理论上我们可以微调非常小的参数量,就能在下游任务取得不错的效果。
LoRA借鉴了上述结果,提出对于预训练的参数矩阵$W_0\in\mathbb{R}^{n\times m}$,我们不去直接微调$W_0$,而是对增量做低秩分解假设:
\begin{equation}W = W_0 + A B,\qquad A\in\mathbb{R}^{n\times r},B\in\mathbb{R}^{r\times m}\end{equation}
23
May
NBCE:使用朴素贝叶斯扩展LLM的Context处理长度
By 苏剑林 | 2023-05-23 | 95250位读者 | 引用在LLM时代还玩朴素贝叶斯(Naive Bayes)?
这可能是许多读者在看到标题后的首个想法。确实如此,当古老的朴素贝叶斯与前沿的LLM相遇时,产生了令人惊讶的效果——我们可以直接扩展现有LLM模型的Context处理长度,无需对模型进行微调,也不依赖于模型架构,具有线性效率,而且效果看起来还不错——这就是本文所提出的NBCE(Naive Bayes-based Context Extension)方法。
摸石过河
假设$T$为要生成的token序列,$S_1,S_2,\cdots,S_n$是给定的若干个相对独立的Context集合(比如$n$个不同的段落,至少不是一个句子被分割为两个片段那种),假设它们的总长度已经超过了训练长度,而单个$S_k$加$T$还在训练长度内。我们需要根据$S_1,S_2,\cdots,S_n$生成$T$,即估计$p(T|S_1, S_2,\cdots,S_n)$。
10
Apr
从JL引理看熵不变性Attention
By 苏剑林 | 2023-04-10 | 37163位读者 | 引用在《从熵不变性看Attention的Scale操作》、《熵不变性Softmax的一个快速推导》中笔者提出了熵不变性Softmax,简单来说就是往Softmax之前的Attention矩阵多乘上一个$\log n$,理论上有助于增强长度外推性,其中$n$是序列长度。$\log n$这个因子让笔者联系到了JL引理(Johnson-Lindenstrauss引理),因为JL引理告诉我们编码$n$个向量只需要$\mathcal{O}(\log n)$的维度就行了,大家都是$\log n$,这两者有没有什么关联呢?
熵不变性
我们知道,熵是不确定性的度量,用在注意力机制中,我们将它作为“集中注意力的程度”。所谓熵不变性,指的是不管序列长度$n$是多少,我们都要将注意力集中在关键的几个token上,而不要太过分散。为此,我们提出的熵不变性Attention形式为
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\log_{512} n}{\sqrt{d}}QK^{\top}\right)V\label{eq:core}\end{equation}
5
May
如何度量数据的稀疏程度?
By 苏剑林 | 2023-05-05 | 40030位读者 | 引用在机器学习中,我们经常会谈到稀疏性,比如我们经常说注意力矩阵通常是很稀疏的。然而,不知道大家发现没有,我们似乎从没有给出过度量稀疏程度的标准方法。也就是说,以往我们关于稀疏性的讨论,仅仅是直观层面的感觉,并没有过定量分析。那么问题来了,稀疏性的度量有标准方法了吗?
经过搜索,笔者发现确实是有一些可用的指标,比如$l_1/l_2$、熵等,但由于关注视角的不同,在稀疏性度量方面并没有标准答案。本文简单记录一下笔者的结果。
基本结果
狭义上来讲,“稀疏”就是指数据中有大量的零,所以最简单的稀疏性指标就是统计零的比例。但如果仅仅是这样的话,注意力矩阵就谈不上稀疏了,因为softmax出来的结果一定是正数。所以,有必要推广稀疏的概念。一个朴素的想法是统计绝对值不超过$\epsilon$的元素比例,但这个$\epsilon$怎么确定呢?

最近评论