






26
Jun
OCR技术浅探:7. 语言模型
By 苏剑林 | 2016-06-26 | 52477位读者 | 引用由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一.
转移概率
在我们分析实验结果的过程中,有出现这一案例.由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择.但是语言模型却可以很巧妙地解决这个问题.原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”.
从概率的角度来看,就是对于第一个字的区域的识别结果$s_1$,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率$W(s_1)$分别为0.99996、0.00004;第二个字的区域的识别结果$s_2$,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率$W(s_2)$分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”.
1
Jul
从Boosting学习到神经网络:看山是山?
By 苏剑林 | 2016-07-01 | 67620位读者 | 引用前段时间在潮州给韩师的同学讲文本挖掘之余,涉猎到了Boosting学习算法,并且做了一番头脑风暴,最后把Boosting学习算法的一些本质特征思考清楚了,而且得到一些意外的结果,比如说AdaBoost算法的一些理论证明也可以用来解释神经网络模型这么强大。
AdaBoost算法
Boosting学习,属于组合模型的范畴,当然,与其说它是一个算法,倒不如说是一种解决问题的思路。以有监督的分类问题为例,它说的是可以把弱的分类器(只要准确率严格大于随机分类器)通过某种方式组合起来,就可以得到一个很优秀的分类器(理论上准确率可以100%)。AdaBoost算法是Boosting算法的一个例子,由Schapire在1996年提出,它构造了一种Boosting学习的明确的方案,并且从理论上给出了关于错误率的证明。
以二分类问题为例子,假设我们有一批样本$\{x_i,y_i\},i=1,2,\dots,n$,其中$x_i$是样本数据,有可能是多维度的输入,$y_i\in\{1,-1\}$为样本标签,这里用1和-1来描述样本标签而不是之前惯用的1和0,只是为了后面证明上的方便,没有什么特殊的含义。接着假设我们已经有了一个弱分类器$G(x)$,比如逻辑回归、SVM、决策树等,对分类器的唯一要求是它的准确率要严格大于随机(在二分类问题中就是要严格大于0.5),所谓严格大于,就是存在一个大于0的常数$\epsilon$,每次的准确率都不低于$\frac{1}{2}+\epsilon$。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 84731位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
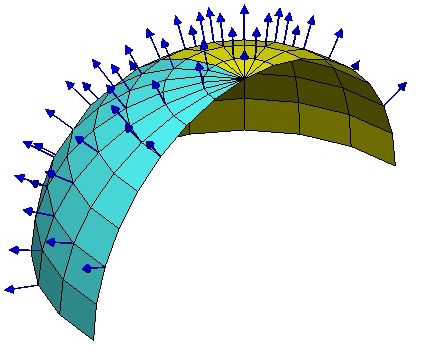
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
4
Nov
【外微分浅谈】2. 反对称的威力
By 苏剑林 | 2016-11-04 | 47592位读者 | 引用内积与外积
向量(这里暂时指的是二维或者三维空间中的向量)的强大之处,在于它定义了内积和外积(更多时候称为叉积、向量积等),它们都是两个向量之间的运算,其中,内积被定义为是对称的,而外积则被定义为反对称的,它们都满足分配律。
沿着书本的传统,我们用$\langle,\rangle$表示内积,用$\land$表示外积,对于外积,更多的时候是用$\times$,但为了不至于出现太多的符号,我们统一使用$\land$。我们将向量用基的形式写出来,比如
$$\boldsymbol{A}=\boldsymbol{e}_{\mu}A^{\mu} \tag{1} $$
其中$\boldsymbol{e}_{\mu}$代表着一组基,而$A^{\mu}$则是向量的分量。我们来计算两个向量$\boldsymbol{A},\boldsymbol{B}$的内积和外积,即
$$\begin{aligned}&\langle \boldsymbol{A}, \boldsymbol{B}\rangle=\langle \boldsymbol{e}_{\mu}A^{\mu}, \boldsymbol{e}_{\nu}B^{\nu}\rangle=\langle\boldsymbol{e}_{\mu},\boldsymbol{e}_{\nu}\rangle A^{\mu}A^{\nu}\\
&\boldsymbol{A}\land \boldsymbol{B}=(\boldsymbol{e}_{\mu}A^{\mu})\land (\boldsymbol{e}_{\nu}B^{\nu})=\boldsymbol{e}_{\mu}\land\boldsymbol{e}_{\nu} A^{\mu}B^{\nu}
\end{aligned} \tag{2} $$
6
Nov
【外微分浅谈】5. 几何意义
By 苏剑林 | 2016-11-06 | 72404位读者 | 引用对于前面所述的外微分,包括后面还略微涉及到的微分形式的积分,都是纯粹代数定义的内容,本身不具有任何的几何意义。但是,我们可以将某些公式或者定义,与一些几何内容对应起来,使我们更深刻地理解它,并且更灵活运用它。但是,它仅仅是一种对应,而且取决于我们的诠释。比如,我们说外微分公式
$$\int_{\partial D} Pdx+Qdy = \int_{D} \left(\frac{\partial Q}{\partial x}-\frac{\partial P}{\partial y}\right)dx\land dy \tag{32} $$
对应于格林公式
$$\int_{\partial D} Pdx+Qdy = \int_{D} \left(\frac{\partial Q}{\partial x}-\frac{\partial P}{\partial y}\right)dxdy \tag{33} $$
。这是没问题的,但它们并不等价,它们仅仅是形式上刚好一样。因为格林公式是描述闭合曲线的积分跟面积分的联系,而外微分的公式是一种纯粹的代数运算。因为你完全可以将$dx\land dy$对应于$-dxdy$而不是$dxdy$,这样就得到另外一种几何的对应。
更深刻的问题是:为什么恰好有这个对应?也就是说,为什么经过一些调整和诠释后,就能够得到与积分公式的对应?首先要明确的是外积与普通的数的乘积,除了反对称性之外,是没有任何区别的,因此不少性质得以保留;其次,还应该要回到反对称本身来考虑,矩阵的行列式代表着矩阵所对应的向量组张成的$n$维立体的体积,然而行列式是反对称的,这就意味着反对称运算跟体积、积分等有着先天的联系。当然,更细致的认识,笔者也还没做到。
此外,我们说寻求微分形式的几何意义,通常只是针对不超过3维的空间来讨论的,更高维的几何图像我们很难想象出来,尤其是高维的曲面积分,一般只是类比,但类比是否成立,有时还需要进一步商榷。因此,这种情况下,倒不如干脆点,说微分形式描述的东西就是几何,而不再去寻找所谓的几何意义了。也就是说,反过来,将微分形式和外微分作为公理式的第一性原理来定义几何。
甚至,你可以只将外微分当作是一种记忆各种微分、积分公式的有效途径,比如现在我要大家默写三维空间中的斯托克斯公式,大家估计会乱,因为不一定记得是哪个减哪个。但是在外微分框架下,可以很快地将它推导一遍。好比式$(11)$,如果非要寻求几何解释,那就是开普勒第二定律:单位时间内扫过的面积相等;然而没有几何解释,你依旧可以把方程解下去。
5
Nov
【外微分浅谈】3. 正交标架
By 苏剑林 | 2016-11-05 | 32544位读者 | 引用众所周知,要掌握黎曼几何,需要强烈的几何直观感。但除此之外,用分量语言描述的黎曼几何,也需要很好的分析能力才能梳理清楚,因为有$N$多的指标在表示着分量和求和,咋看上去处处皆指标。这种繁琐的分量语言并不总讨人喜欢,甚至在不少地方是声名狼籍的。
在分量的语言中,我们本质上可以在局部建立任意形式的坐标系,也就是采用任意形式的基底$\{\boldsymbol{e}_{\mu}\}$,或者说自然标架。但不可否认,在正交标架(标准正交基)之下,很多方程会简单不少,并且得益于我们对欧氏空间的熟练,我们对正交标架下的研究可能会更有感觉。因此,如果条件允许的话,我们应当使用正交标架$\{\hat{\boldsymbol{e}}_{\mu}\}$,哪怕是活动的,这里我们用$\hat{}$标记正交标架。
比如,我们有微元
$$d\boldsymbol{r} = \boldsymbol{e}_{\mu}dx^{\mu} \tag{12} $$
是在一般标架下测量的,那么就可以得到黎曼度量
11
Nov
【外微分浅谈】7. 有力的计算
By 苏剑林 | 2016-11-11 | 28256位读者 | 引用这里我们将展示上面一节的方法对于计算黎曼曲率张量的计算是多少的有力!我们再次列出我们得到的所有公式。首先是概念式的
$$\begin{aligned}&\omega^{\mu}=h_{\alpha}^{\mu}dx^{\alpha}\\
&d\boldsymbol{r}=\hat{\boldsymbol{e}}_{\mu} \omega^{\mu}\\
&ds^2 = \eta_{\mu\nu} \omega^{\mu}\omega^{\nu}\\
&\langle \hat{\boldsymbol{e}}_{\mu}, \hat{\boldsymbol{e}}_{\nu}\rangle = \eta_{\mu\nu}\end{aligned} \tag{65} $$
然后是
$$\begin{aligned}&d\eta_{\mu\nu}=\omega_{\nu\mu}+\omega_{\mu\nu}=\eta_{\nu\alpha}\omega_{\mu}^{\alpha}+\eta_{\mu \alpha}\omega_{\nu}^{\alpha}\\
&d\omega^{\mu}+\omega_{\nu}^{\mu}\land \omega^{\nu}=0\end{aligned} \tag{66} $$
这两个可以帮助我们确定$\omega_{\nu}^{\mu}$;接着就是
$$\mathscr{R}_{\nu}^{\mu} = d\omega_{\nu}^{\mu}+\omega_{\alpha}^{\mu} \land \omega_{\nu}^{\alpha} \tag{67} $$
最后你要正交标架下的$\hat{R}^{\mu}_{\nu\beta\gamma}$,就要写出:
$$\mathscr{R}_{\nu}^{\mu}=\sum_{\beta < \gamma} \hat{R}^{\mu}_{\nu\beta\gamma}\omega^{\beta}\land \omega^{\gamma} \tag{68} $$
如果你要原始标架下的$R^{\mu}_{\nu\beta\gamma}$,就要写出
$$(h^{-1})_{\mu'}^{\mu}\mathscr{R}^{\mu'}_{\nu'}h_{\nu}^{\nu'} = \sum_{\beta < \gamma} R^{\mu}_{\nu\beta\gamma}dx^{\beta}\land dx^{\gamma} \tag{69} $$
然后依次读出$R^{\mu}_{\nu\beta\gamma}$,就像制表一样。
15
Jan
SVD分解(一):自编码器与人工智能
By 苏剑林 | 2017-01-15 | 51603位读者 | 引用咋看上去,SVD分解是比较传统的数据挖掘手段,自编码器是深度学习中一个比较“先进”的概念,应该没啥交集才对。而本文则要说,如果不考虑激活函数,那么两者将是等价的。进一步的思考就可以发现,不管是SVD还是自编码器,我们降维,并不是纯粹地为了减少储存量或者减少计算量,而是“智能”的初步体现。
等价性
假设有一个$m$行$n$列的庞大矩阵$M_{m\times n}$,这可能使得计算甚至存储上都成问题,于是考虑一个分解,希望找到矩阵$A_{m\times k}$和$B_{k\times n}$,使得
$$M_{m\times n}=A_{m\times k}\times B_{k\times n}$$
这里的乘法是矩阵乘法。如图
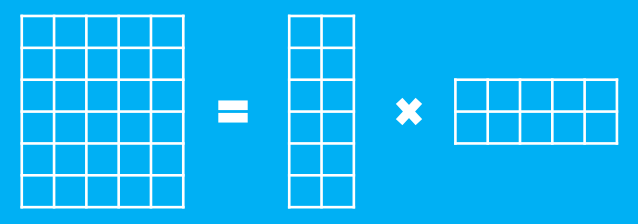
SVD

最近评论