






6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 186431位读者 |不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。
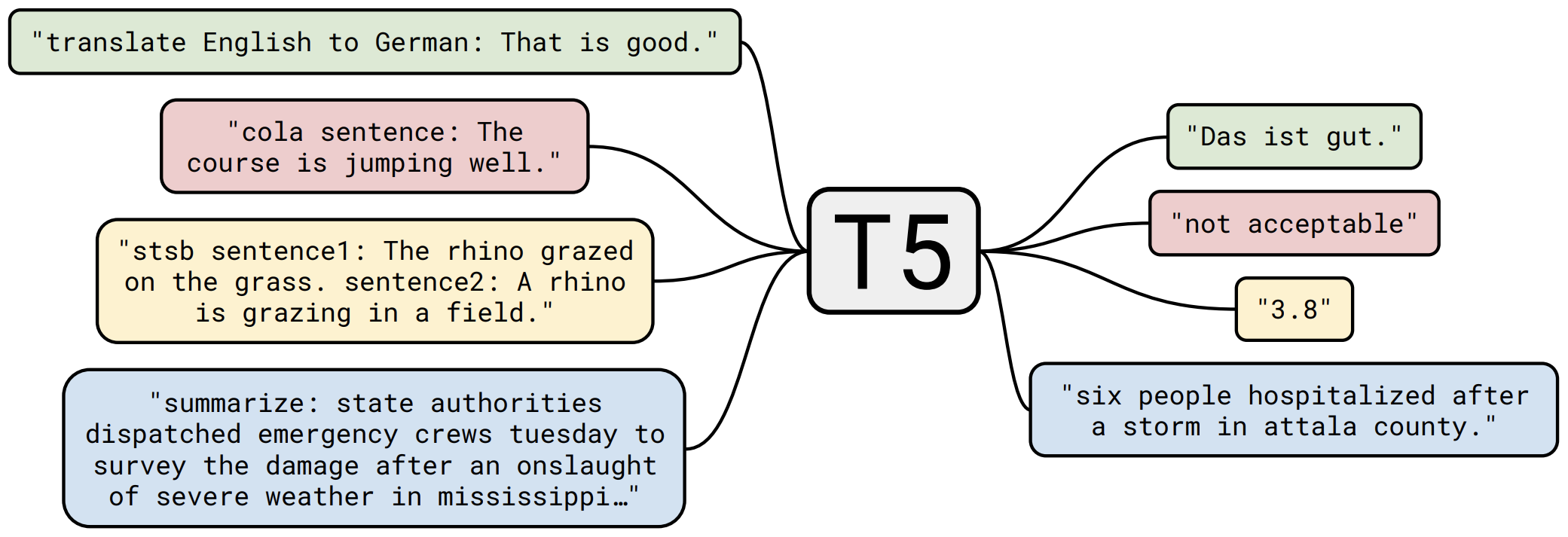
“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。
T5 #
跟BERT一样,T5也是Google出品的预训练模型,来自论文为《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》,Github为text-to-text-transfer-transformer。T5的理念就是“万事皆可Seq2Seq”,它使用了标准的Encoder-Decoder模型,并且构建了无监督/有监督的文本生成预训练任务,最终将效果推向了一个新高度。
训练 #
T5的预训练包含无监督和有监督两部分。无监督部分使用的是Google构建的近800G的语料(论文称之为C4),而训练目标则跟BERT类似,只不过改成了Seq2Seq版本,我们可以将它看成一个高级版的完形填空问题:
输入:明月几时有,[M0]问青天,不知[M1],今夕是何年?我欲[M2]归去,又恐琼楼玉宇,高处[M3];起舞[M4]清影,何似在人间。
输出:[M0]把酒[M1]天上宫阙[M2]乘风[M3]不胜寒[M4]弄
而有监督部分,则是收集了常见的NLP监督任务数据,并也统一转化为SeqSeq任务来训练。比如情感分类可以这样转化:
输入:识别该句子的情感倾向:这趟北京之旅我感觉很不错。
输出:正面
主题分类可以这样转化:
输入:下面是一则什么新闻?八个月了,终于又能在赛场上看到女排姑娘们了。
输出:体育
阅读理解可以这样转化:
输入:阅读理解:特朗普与拜登共同竞选下一任美国总统。根据上述信息回答问题:特朗普是哪国人?
输出:美国
可以看到,这种转化跟GPT2、GPT3、PET的思想都是一致的,都是希望用文字把我们要做的任务表达出来,然后都转化为文字的预测,读者还可以翻看旧作《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》了解相关内容。总的来说,在我们的内部实验里边,模型够大、数据够多以及有监督预训练都是T5成功的关键因素,“万事皆可Seq2Seq”则提供了有效地融合这些关键因素的方案。
结果 #
T5的主要战绩汇总如下表:
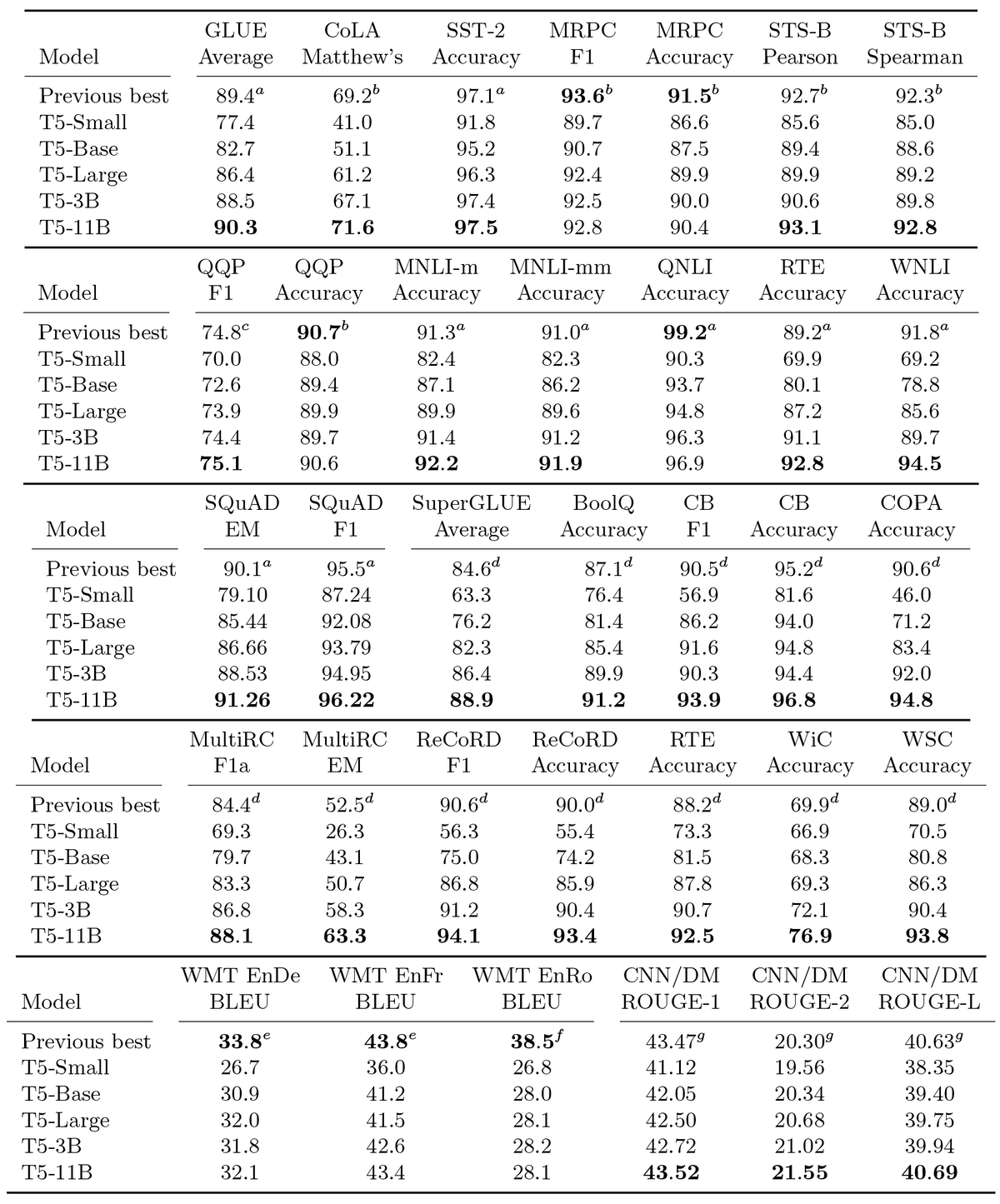
T5的战绩汇总
除了屠了多个榜单之外,T5还对整个训练流程中很多可调的超参数都调试了一遍,比如模型架构究竟用标准的Encoder-Decoder好还是UniLM那种结构好,无监督预训练任务究竟是BERT的方式好还是其他方式好,随机Mask的比例是不是15%最好,等等,最后给出了如下的表格,并还很遗憾地表达了一句“其实我们觉得T5的实验做得还不是很充分”,颇有一种“走别人的路,让别人无路可走”的感觉。当然,不管怎样,这些炼丹结果还是值得每一位要做语言模型的同学好好看看,或许能让我们少走一些弯路。
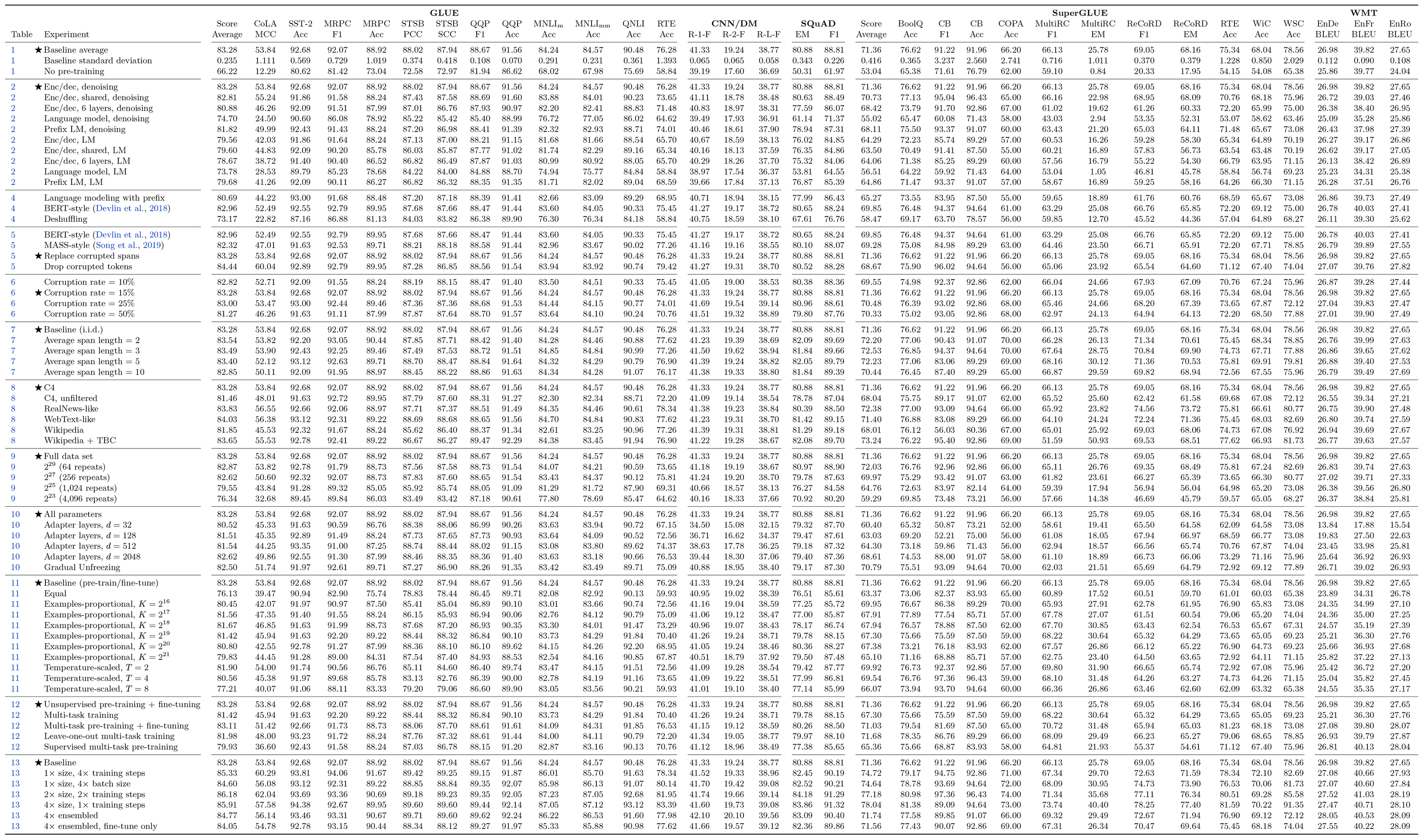
T5那巨细无遗的“炼丹宝典”(点击可以看大图)
mT5 #
至于mT5,即Multilingual T5,T5的多国语言版,出自最近的论文《mT5: A massively multilingual pre-trained text-to-text transformer》,Github为multilingual-t5,这也是将多语种NLP任务的榜单推到了一个新高度了。当然,对我们来说,最重要的是mT5里边包含了中文,因此我们终于有机会在中文任务中尝试下T5了。
T5.1.1 #
总的来说,mT5跟T5一脉相承的,整体基本一样,但在模型结构方面,mT5使用的是T5.1.1方案,在此对它做个基本的介绍。
很多人都不知道的是,自从在去年10月发布后,T5在今年还经历了一次低调的小升级,具体细节可以查看Github链接,官方把升级前的T5称为T5.1.0,而升级后的叫做T5.1.1。它主要的改动来自论文《GLU Variants Improve Transformer》,主要是借用了《Language Modeling with Gated Convolutional Networks》的GLU(Gated Linear Unit)来增强FFN部分的效果。具体来说,原来T5的FFN为(T5没有Bias)
\begin{equation}\text{FFN}(x)=\text{relu}(xW_1)W_2\end{equation}
现在改为了
\begin{equation}\text{FFN}_{\text{GEGLU}}(x)=\big(\text{gelu}(xW_1)\otimes xW_2\big)W_3\end{equation}
也就是把relu激活的第一个变化层改为了gelu激活的门控线性单元,这样FFN层增加了50%参数,但是从论文效果看效果明显增加。此外,T5.1.1还对Embedding层做了改动,原来在T5.1.0中,Encoder和Decoder的Embedding层、Decoder最后预测概率分布的Softmax层都是共享同一个Embedding矩阵的,现在T5.1.1只让Encoder和Decoder的Embedding层共享,而Decoder最后预测概率分布的Softmax层则用了一个独立的Embedding矩阵,当然这会让参数量大大增加,但Google的结论说这样做效果会更好,其结论被总结在最近的论文《Rethinking embedding coupling in pre-trained language models》中。还有最后一点改动,T5.1.1在预训练阶段去掉了Dropout,而只有在下游微调阶段才使用Dropout。
经过这些调整后,Google重新训练并开放了全系列的T5.1.1模型,其下载地址可以在刚才的Github链接找到,注意T5.1.1只做了无监督预训练,但效果依然相当出色。由于T5.1.1提升明显,所以mT5也就继续使用了T5.1.1结构了
结果 #
mT5其实就是重新构建了多国语言版的数据集mC4,然后使用T5.1.1方案训练了一波,技术路线上没有什么明显的创新。关于训练细节,大家观察下原论文就好,论文其实也不长,毕竟T5已经把路都给铺好了。
至于mT5的战绩,主要就是集中在下面这张表内了:
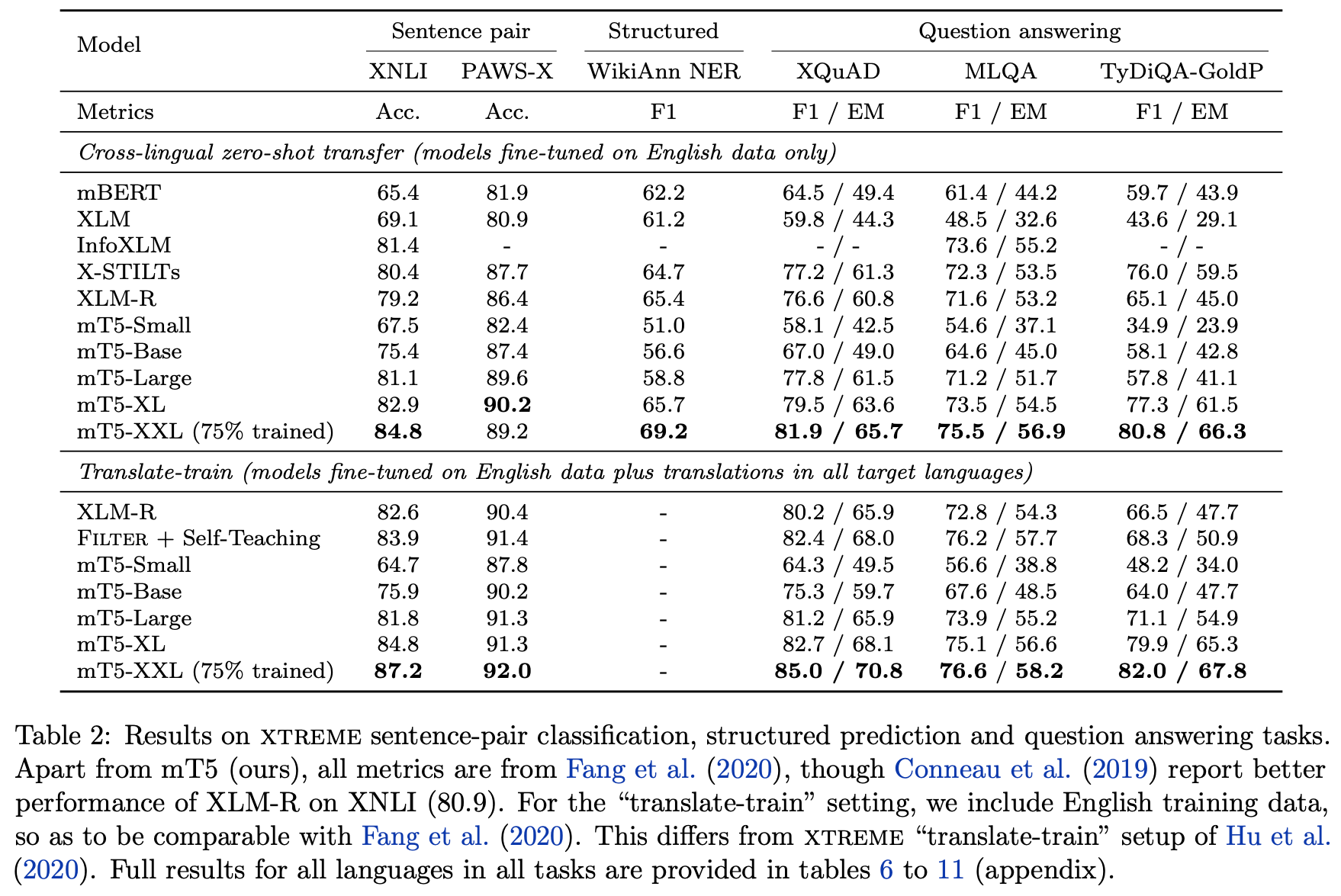
mT5的“战绩”
读者可能会有疑问,这种多国语言版的该用什么方式评测?简单的话,我们可以直接在此基础上finetune一个跨语种的机器翻译任务,看看效果的提升。但事实上,对于多国语言版模型,研究人员更关心的是它在跨语种任务上的Zero Shot表现,说白了,就是同一种任务,在一个语种上进行finetune,其模型能不能直接用于其余语种?这也是上图中“Cross-lingual zero-shot transfer (models fine-tuned on English data only)”的含义了,可以看到,mT5的表现还是相当出色的。
实践 #
终于到了大家喜闻乐见的实践时间了,这里我们简单介绍一下在bert4keras上使用mT5模型来做中文文本生成任务的流程和技巧。bert4keras从0.9.1版本开始支持调用mT5模型,如果要进行下述实验的读者,请先将bert4keras升级到0.9.1版或以上。
Github链接:https://github.com/bojone/t5_in_bert4keras
基本 #
用bert4keras把mT5模型加载到keras中的基本代码为
# 模型路径
config_path = '/root/kg/bert/mt5/mt5_small/t5_config.json'
checkpoint_path = '/root/kg/bert/mt5/mt5_small/model.ckpt-1000000'
spm_path = '/root/kg/bert/mt5/sentencepiece.model'
# 加载分词器
tokenizer = SpTokenizer(spm_path, token_start=None, token_end='</s>')
# 加载模型
t5 = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
model='t5.1.1',
return_keras_model=False,
name='T5',
)
encoder = t5.encoder
decoder = t5.decoder
model = t5.model可以看到跟在bert4keras中加载BERT没太大区别,其中t5_config.json的构建、model.ckpt-1000000的下载在Github上都有详细介绍,大家请移步去看。完整代码(训练和解码细节)在Github上也可以找到,这里就不展开了。
值得一提的是,对于中文来说,tokenizer给出的结果是带有词的,即对于中文来说mT5是以词为单位的,只不过词颗粒度会比较少。这进一步说明了我们之前的工作《提速不掉点:基于词颗粒度的中文WoBERT》的改进方向是正确的。
中文 #
相信看本博客的读者多数都只关心中文任务,部分读者可能也会关心英文任务,应该鲜有读者会关心中英文以外的任务了。然而,mT5涵盖了101种语言,总词表有25万,而且它采用的T5.1.1结构的Softmax还不共享参数,这就导致了Embedding层占用了相当多的参数量,比如mT5 small的参数量为3亿,其中Embedding相关的就占了2.5亿,关键是里边的大部分参数我们都用不上,纯粹是不必要的浪费。因此,对于主要关心中文任务的我们来说,有必要精简一下这个Embedding层了。
对模型的精简很简单,只需要在两个Embedding矩阵中删除不需要的行就行了,关键在于如何决定要保留的token,以及如何得到一个精简后的sentencepiece模型。决定要保留的token,简单来想就是把中文的token保留下来,但是也不只是中文,英文的也要保留一部分,看上去似乎只是一个正则表达式的问题,实际上没那么简单,用英文字母的也不一定是英语,用中文字的也不一定是中文,这是个让人纠结的事情。于是笔者想了另外一个办法:用这个25万token的tokenizer对笔者收集的几十G中文语料分词,统计分词结果,然后按照词频选择前面的部分(最后保留了3万多个token)。这样虽然费时一些,但是比较靠谱,能确保把我们比较需要的token保留下来。决定词表后,就要修改得到一个新的sentencepiece模型,这也有点麻烦,但最终经过搜索后还是把这个事情解决了,处理方法都分享在Github上。
经过这样处理后,要构建新的模型,则只需要多加三行代码keep_tokens相关的代码,所需要的显存就大大降低,并且中文生成的效果基本不变了:
# 模型路径
config_path = '/root/kg/bert/mt5/mt5_base/t5_config.json'
checkpoint_path = '/root/kg/bert/mt5/mt5_base/model.ckpt-1000000'
spm_path = '/root/kg/bert/mt5/sentencepiece_cn.model'
keep_tokens_path = '/root/kg/bert/mt5/sentencepiece_cn_keep_tokens.json'
# 加载分词器
tokenizer = SpTokenizer(spm_path, token_start=None, token_end='</s>')
keep_tokens = json.load(open(keep_tokens_path))
# 加载模型
t5 = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
keep_tokens=keep_tokens,
model='t5.1.1',
return_keras_model=False,
name='T5',
)
encoder = t5.encoder
decoder = t5.decoder
model = t5.model效果 #
最后,大家应该是关心折腾了这么久,生成效果究竟有没有提升,有没有使用的价值?这样说吧,用mT5 small版本finetune出来的CSL标题生成模型,BLEU指标能持平基于WoBERT的UniLM模型,并且解码速度快130%;而用mT5 base版本finetune出来的CSL标题生成模型,指标能超过基于WoBERT的UniLM模型1%以上,并且解码速度也能快60%。
\begin{array}{c}
\text{CSL摘要生成实验结果 (beam size=1)}\\
{\begin{array}{c|cccc|c}
\hline
& \text{Rouge-L} & \text{Rouge-1} & \text{Rouge-2} & \text{BLEU} & \text{解码速度}\\
\hline
\text{BERT base} & 63.81 & 65.45 & 54.91 & 45.52 & \text{1x}\\
\text{WoBERT base} & 66.38 & 68.22 & 57.83 & 47.76 & \text{1.1x}\\
\hline
\text{mT5 small} & 65.14 & 67.08 & 56.71 & 47.69 & \text{2.3x}\\
\text{mT5 base} & \textbf{66.81} & \textbf{68.94} & \textbf{58.49} & \textbf{49.49} & \text{1.6x}\\
\hline
\end{array}}
\end{array}
说白了,确实是又快又好。至于设备要求,平时跑过BERT base的同学,基本都应该能跑起mT5 small/base版,甚至large版也可以尝试一下,至于XL和XXL,那就比较难搞了,建议还是放弃吧。更多的惊喜,还是大家自己去挖掘吧~~对了,顺便需要提醒一下,微调T5模型的时候,学习率要比微调BERT大10倍以上才行(即$10^{-4}$级别,BERT一般是$10^{-5}$级别),这是两者模型架构差异决定的。
小结 #
本文回顾了一下Google去年发布的T5模型,然后介绍了最近发布的多国语言版的mT5,最后介绍了如何在bert4keras中微调mT5来做中文任务,结果显示mT5在中文生成上有着很不错的表现,值得做文本生成任务的同学一试。
转载到请包括本文地址:https://kexue.fm/archives/7867
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Nov. 06, 2020). 《那个屠榜的T5模型,现在可以在中文上玩玩了 》[Blog post]. Retrieved from https://kexue.fm/archives/7867
@online{kexuefm-7867,
title={那个屠榜的T5模型,现在可以在中文上玩玩了},
author={苏剑林},
year={2020},
month={Nov},
url={\url{https://kexue.fm/archives/7867}},
}

December 24th, 2020
想改装你的t5代码来应用在原来bert4keras的事件抽取例子中,nodes = model.predict([[token_ids], [segment_ids]])[0]这个predict函数得到的nodes除了第一行全是无穷小,应该修改什么呢?
t5哪来的segment_ids?要换t5的话,需要先理解t5,然后理解keras,最后理解事件抽取模型。
January 6th, 2021
“想改装你的t5代码来应用在原来bert4keras的事件抽取例子中”,我也在做这个尝试,也是遇到这个问题,不知道该从何下手了,加个q1340121584交流下
January 7th, 2021
精简Embedding这个思路不错,mark!
January 28th, 2021
请问,如何做情感分类?
同问,有思路了吗你
February 1st, 2021
想了解一下您数据集的大小,我仅在GitHub找到3000条数据,但是复现的效果差很多。想咨询一下您
CSL的训练集大概有1万条标签数据左右。
苏神你好,csl这个数据集能分享一下吗?我在网上目前只能下载到总量是3500的这个版本
QQ群里有。
June 3rd, 2021
mbart取出中文相关的词向量,苏神有尝试过吗,比这个mT5如何?
July 27th, 2021
如果是阅读理解任务,输入“阅读理解:特朗普与拜登共同竞选下一任美国总统。根据上述信息回答问题:特朗普是哪国人?”这里的“阅读理解:“和”根据上述信息回答问题:”是T5独特要求的?只能这样写是吗?多谢
还有一个问题,训练数据中,需要增加answer为空的数据吗?
这不是T5要求的,这是训练者自行设计的。而且模型也没这么死板,会有一定的容错能力的。
还有一个问题,从哪里可以获取预测文本的概率呢
October 20th, 2021
微调模型的时候用多大的学习率,应该如何根据架构决定呢?
February 19th, 2022
苏神请问:MT5做分类任务和序列标注的NER任务,可以直接在模型添加下游任务的网络层,如直接接一个Softmax进行输出吗?Softmax是要接到t5_Decoder层后面吗?
这种做法直接接到encoder后面就行了
mt5模型的"Encoder-Transformer-11-FeedForward-Norm"层后面?
我看您接到了BERT的"Transformer-11-FeedForward-Norm"后面.在mt5的模型层中,这个名字比较类似.
调了从1e-3到1e-5的学习率.在NER的数据集上最好的结果也相差2%以上.
September 14th, 2022
[...][4] 那个屠榜的T5模型,现在可以在中文上玩玩了[...]