






18
May
鱼与熊掌兼得:融合检索和生成的SimBERT模型
By 苏剑林 | 2020-05-18 | 406908位读者 |前段时间我们开放了一个名为SimBERT的模型权重,它是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明。在这篇文章里,我们来补充这部分内容。
UniLM #
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。我们之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

UniLM的Mask
换句话说,[CLS] 你 想 吃 啥 [SEP]这几个token之间是双向的Attention,而白 切 鸡 [SEP]这几个token则是单向Attention,从而允许递归地预测白 切 鸡 [SEP]这几个token,所以它具备文本生成能力。
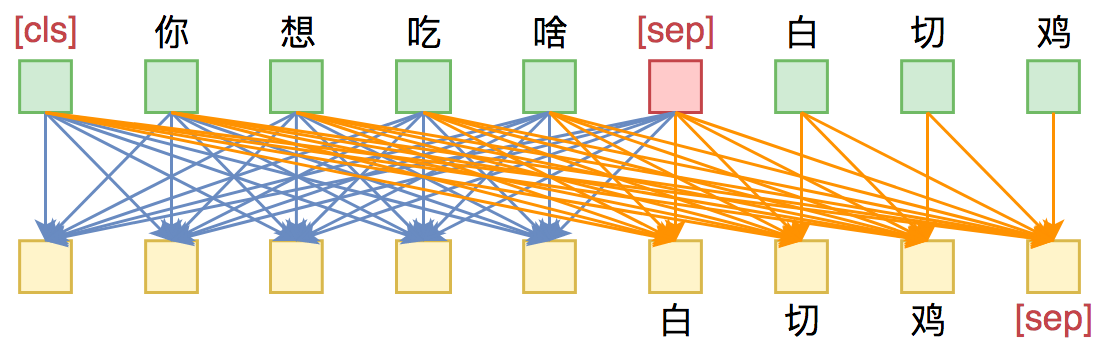
UNILM做Seq2Seq模型图示。输入部分内部可做双向Attention,输出部分只做单向Attention。
Seq2Seq只能说明UniLM具有NLG的能力,那前面为什么说它同时具备NLU和NLG能力呢?因为UniLM特殊的Attention Mask,所以[CLS] 你 想 吃 啥 [SEP]这6个token只在它们之间相互做Attention,而跟白 切 鸡 [SEP]完全没关系,这就意味着,尽管后面拼接了白 切 鸡 [SEP],但这不会影响到前6个编码向量。再说明白一点,那就是前6个编码向量等价于只有[CLS] 你 想 吃 啥 [SEP]时的编码结果,如果[CLS]的向量代表着句向量,那么它就是你 想 吃 啥的句向量,而不是加上白 切 鸡后的句向量。
由于这个特性,UniLM在输入的时候也随机加入一些[MASK],这样输入部分就可以做MLM任务,输出部分就可以做Seq2Seq任务,MLM增强了NLU能力,而Seq2Seq增强了NLG能力,一举两得。
SimBERT #
理解了UniLM后,其实就不难理解SimBERT训练方式了。SimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后前面也提到过[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务,如下图:
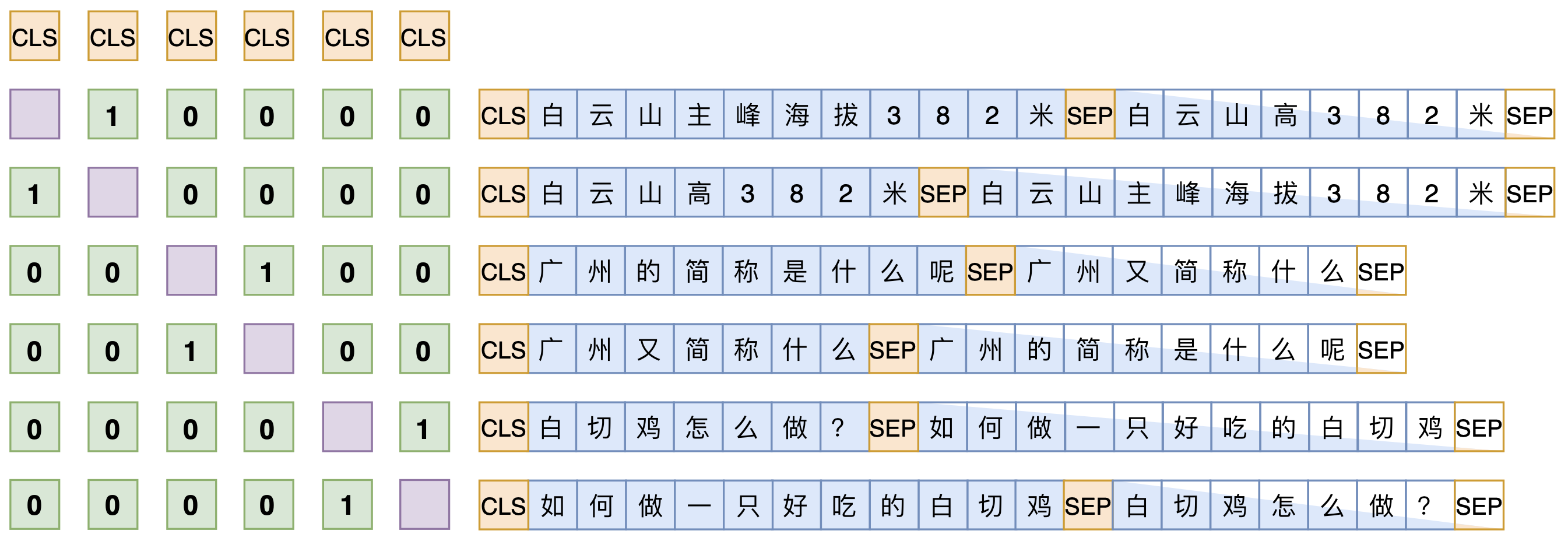
SimBERT训练方式示意图
假设SENT_a和SENT_b是一组相似句,那么在同一个batch中,把[CLS] SENT_a [SEP] SENT_b [SEP]和[CLS] SENT_b [SEP] SENT_a [SEP]都加入训练,做一个相似句的生成任务,这是Seq2Seq部分。
另一方面,把整个batch内的[CLS]向量都拿出来,得到一个句向量矩阵$\boldsymbol{V}\in\mathbb{R}^{b\times d}$($b$是batch_size,$d$是hidden_size),然后对$d$维度做$l_2$归一化,得到$\tilde{\boldsymbol{V}}$,然后两两做内积,得到$b\times b$的相似度矩阵$\tilde{\boldsymbol{V}}\tilde{\boldsymbol{V}}^{\top}$,接着乘以一个scale(我们取了30),并mask掉对角线部分,最后每一行进行softmax,作为一个分类任务训练,每个样本的目标标签是它的相似句(至于自身已经被mask掉)。说白了,就是把batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。
说到底,关键就是“[CLS]的向量事实上就代表着输入的句向量”,所以可以用它来做一些NLU相关的事情。最后的loss是Seq2Seq和相似句分类两部分loss之和。
其他细节 #
由于已经开放源码,所以更多的训练细节大家可以自行阅读源码。模型使用keras + bert4keras实现,代码还是很清晰的,所以很多疑惑应该都可以通过阅读源码解决。
效果演示:
>>> gen_synonyms(u'微信和支付宝哪个好?')
[
u'微信和支付宝,哪个好?',
u'微信和支付宝哪个好',
u'支付宝和微信哪个好',
u'支付宝和微信哪个好啊',
u'微信和支付宝那个好用?',
u'微信和支付宝哪个好用',
u'支付宝和微信那个更好',
u'支付宝和微信哪个好用',
u'微信和支付宝用起来哪个好?',
u'微信和支付宝选哪个好',
u'微信好还是支付宝比较用',
u'微信与支付宝哪个',
u'支付宝和微信哪个好用一点?',
u'支付宝好还是微信',
u'微信支付宝究竟哪个好',
u'支付宝和微信哪个实用性更好',
u'好,支付宝和微信哪个更安全?',
u'微信支付宝哪个好用?有什么区别',
u'微信和支付宝有什么区别?谁比较好用',
u'支付宝和微信哪个好玩'
]
>>> most_similar(u'怎么开初婚未育证明', 20)
[
(u'开初婚未育证明怎么弄?', 0.9728098),
(u'初婚未育情况证明怎么开?', 0.9612292),
(u'到哪里开初婚未育证明?', 0.94987774),
(u'初婚未育证明在哪里开?', 0.9476072),
(u'男方也要开初婚证明吗?', 0.7712214),
(u'初婚证明除了村里开,单位可以开吗?', 0.63224965),
(u'生孩子怎么发', 0.40672967),
(u'是需要您到当地公安局开具变更证明的', 0.39978087),
(u'淘宝开店认证未通过怎么办', 0.39477515),
(u'您好,是需要当地公安局开具的变更证明的', 0.39288986),
(u'没有工作证明,怎么办信用卡', 0.37745982),
(u'未成年小孩还没办身份证怎么买高铁车票', 0.36504325),
(u'烟草证不给办,应该怎么办呢?', 0.35596085),
(u'怎么生孩子', 0.3493368),
(u'怎么开福利彩票站', 0.34158638),
(u'沈阳烟草证怎么办?好办不?', 0.33718678),
(u'男性不孕不育有哪些特征', 0.33530876),
(u'结婚证丢了一本怎么办离婚', 0.33166665),
(u'怎样到地税局开发票?', 0.33079252),
(u'男性不孕不育检查要注意什么?', 0.3274408)
]大家可能比较关心训练数据的问题,这里统一回答:关于训练数据,不方便公开,私下分享也不方便,所以就不要问数据的事情了,数据来源就是爬取百度知道推荐的相似问,然后经过简单算法过滤。如果读者手头上本身有很多问句,那么其实也可以通过常见的检索算法检索出一些相似句,作为训练数据用。总而言之,训练数据没有特别严格要求,理论上有一定的相似性都可以。
至于训练硬件,开源的模型是在一张TITAN RTX(22G显存,batch_size=128)上训练了4天左右,显存和时间其实也没有硬性要求,视实际情况而定,如果显存没那么大,那么适当降低batch_size即可,如果语料本身不是很多,那么训练时间也不用那么长(大概是能完整遍历几遍数据集即可)。
暂时就只能想到这些了,还有啥问题欢迎留言讨论。
文章小结 #
本文介绍了早先我们放出来的SimBERT模型的训练原理,并开源了训练代码。SimBERT通过基于UniLM思想进行训练,同时具备检索和生成的能力,欢迎大家使用测试~
转载到请包括本文地址:https://kexue.fm/archives/7427
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 18, 2020). 《鱼与熊掌兼得:融合检索和生成的SimBERT模型 》[Blog post]. Retrieved from https://kexue.fm/archives/7427
@online{kexuefm-7427,
title={鱼与熊掌兼得:融合检索和生成的SimBERT模型},
author={苏剑林},
year={2020},
month={May},
url={\url{https://kexue.fm/archives/7427}},
}

October 13th, 2020
嗨,苏神,请教一下,UniLM的预训练mask有3中,双向,单向,seq2seq mask三种,根据simbert的理解,预训练是不是只用了seq2seq mask这种啊,如果加了双向mask,cls表示的就不是左边句子的含义了,单向的mask貌似也可以加,不知道理解了对不对?
是的,只用了seq2seq mask
November 17th, 2020
有点疑惑:
simbert中 CLS S1 SEP S2 SEP: CLS S1 SEP 真的跟S2 SEP没关系吗?在单个attention中是没有关系(attention中用了mask),可是bert是多个attention,后面不是还有LN,Dense?这总有点关系吧?对s2s也有点类似的疑惑。不知道哪里没想清楚。
LN, Dense都是每个token独立进行的,跟其他token无关。
明白了
March 15th, 2021
你好,这是在模型生成的句子中找相似吗,如果这样,就像间接从语料中找相似句子,生成的万一不和数据集内的句子一致,不利于找到原始相似句子啊
不知道你说什么。我为什么要找训练集已有的句子?
感谢大神的回复,是这样的,我想用这个模型做FAQ,想通过新输入的句子检索相似问,自然需要检索的相似问是训练集里面的,因为训练集里面的问题可以直接映射到答案。
还有第二个问题,我下载了大佬的开源代码和预训练模型,在恢复seq2seq部分时,遇到了问题。查看了一下使用transformer构建的bert,bert的outputs只有一个张量。encoder取了bert.model.output[0],seq2seq取bert.model.output[1],这时候取不到张量啊。还请大神解惑,谢谢!
这种需求为什么不直接用检索模型?当然用生成模型理论上也可以,通过前缀树来控制解码过程就行了。
检索模型? 是不是另外一篇文章的无监督模型哪家强?
随便。SimBERT也有检索模型。
March 18th, 2021
关于bert.model.outputsTensor的问题已经搞清楚了,忘了开启with_mlm。不用麻烦大佬了
April 2nd, 2021
请问苏神,simbert用tensorflow severing部署模型文件怎么转?
simbert用tensorflow severing部署模型跟其他keras模型用tensorflow severing部署没什么区别。至于其他keras模型怎么用tensorflow severing部署,我也没研究过~
供参考:https://github.com/bojone/bert4keras/issues/194
April 28th, 2021
为啥没有写paper发表?
May 25th, 2021
苏神,这个可以并行化的生成相似语句吗,我看代码一次只能生成一句话的相似语句
自己改写就可以,现成的不可以。
June 12th, 2021
苏神,您好。请问训练数据是否可以公开呢?
暂时不可以。
June 25th, 2021
UniLM的Mask那张图是不是有点问题?因为用的是MLM,一个token也是可以关注到它本身的。也就是“白”对应“白”的mask应该是0,而不是-∞。
没有问题。并不是mlm。
我看UniLM论文里面seq2seq模式在预训练时是通过mask来实现的,inference的时候我理解是这样的。
[CLS] 你 想 吃 啥 [SEP] 白 [MASK] --> [CLS] 你 想 吃 啥 [SEP] 白 切
请问为什么不是mlm呢?我哪里理解错了吗?
因为我理解的inference不是这样的,我理解的inference就是跟训练一致的。我不知道你为什么要理解成训练和预测不一致...
预训练和fintune的时候不是也是这样的吗?
显然不是,你还没理解unilm的原理。
“[SOS] S1 [EOS] S2 [EOS]”. The model is fine-tuned by masking some percentage of tokens in the target sequence at random, and learning to recover the masked words. The training objective is to maximize the likelihood of masked tokens given context.
这是原文内容,训练阶段是通过mask来做的,微调阶段不同的地方是可以mask [EOS]。
训练阶段过程是这样的:
[SOS] 你 想 吃 啥 [EOS] 白 [MASK] 鸡 [EOS] --> [SOS] 你 想 吃 啥 [EOS] 白 切 鸡 [EOS]
然后通过attention mask来控制target只能看到左边的信息,这确实是MLM模型呀。
@wby|comment-16751
如果真是这样的话,那就是原论文作者自己的问题。我用的是正确的纯unilm用法,不用这种unilm和mlm混杂用法。
June 28th, 2021
@苏剑林|comment-16753
啊?我上面摘抄出来的就是unilm的原始论文呀。
那跟我有什么关系啊...
我用的是unilm这种attention mask,我用的是我认为最正确的用法,我不是照搬unilm的原论文,也不认为原论文全是对的。它的代码我没看,如果真像它写的,finetune阶段用unilm和mlm混杂的用法,那么真的是非常丑的,而丑的东西我认为是绝对要抛弃的(哪怕它效果可能更好)。
另外,事实上这个attention mask我是自己独立发现的,只不过后来发现unilm的思路差不多,所以才跟unilm的命名对齐。所以我没多少参考unilm的原论文。
.....你用的标题和图都是UniLM,然后和原始论文不一样。我只是提出来可能有错误而已,向你学习,大家共同进步。
感谢你的意见。
但很显然我的图是自己画的,我的代码也是自己写的,而且很显然UniLM的新颖之处也是因为它的attention mask(也就是它所谓的预训练阶段),所以我这样使用UniLM这个名字按道理应该是揪不出毛病来的。
反倒原论文里边,预训练用一套,微调又用另一套(MLM的方式),还不带解释,才是真正让人莫名其妙的。我认为大家对UniLM的印象,也主要是停留在它的attention mask,而不在于它预训练和微调各搞一套的莫名其妙吧。
感觉我们的观点还是不一样,实际上原论文在预训练、微调和预测阶段用的都是MLM这一套,并没有不同。当然attention mask也确实是他的核心点。不过无所谓了,求同存异。
这就轮到我莫名其妙了。真如你所说的话,那官方版的unilm真的没有任何优雅可言了。