






18
May
鱼与熊掌兼得:融合检索和生成的SimBERT模型
By 苏剑林 | 2020-05-18 | 420191位读者 |前段时间我们开放了一个名为SimBERT的模型权重,它是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明。在这篇文章里,我们来补充这部分内容。
UniLM #
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。我们之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

UniLM的Mask
换句话说,[CLS] 你 想 吃 啥 [SEP]这几个token之间是双向的Attention,而白 切 鸡 [SEP]这几个token则是单向Attention,从而允许递归地预测白 切 鸡 [SEP]这几个token,所以它具备文本生成能力。
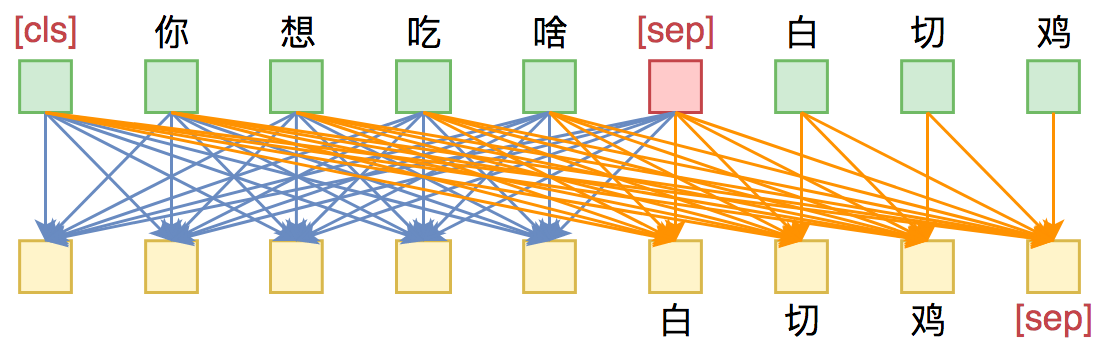
UNILM做Seq2Seq模型图示。输入部分内部可做双向Attention,输出部分只做单向Attention。
Seq2Seq只能说明UniLM具有NLG的能力,那前面为什么说它同时具备NLU和NLG能力呢?因为UniLM特殊的Attention Mask,所以[CLS] 你 想 吃 啥 [SEP]这6个token只在它们之间相互做Attention,而跟白 切 鸡 [SEP]完全没关系,这就意味着,尽管后面拼接了白 切 鸡 [SEP],但这不会影响到前6个编码向量。再说明白一点,那就是前6个编码向量等价于只有[CLS] 你 想 吃 啥 [SEP]时的编码结果,如果[CLS]的向量代表着句向量,那么它就是你 想 吃 啥的句向量,而不是加上白 切 鸡后的句向量。
由于这个特性,UniLM在输入的时候也随机加入一些[MASK],这样输入部分就可以做MLM任务,输出部分就可以做Seq2Seq任务,MLM增强了NLU能力,而Seq2Seq增强了NLG能力,一举两得。
SimBERT #
理解了UniLM后,其实就不难理解SimBERT训练方式了。SimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后前面也提到过[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务,如下图:
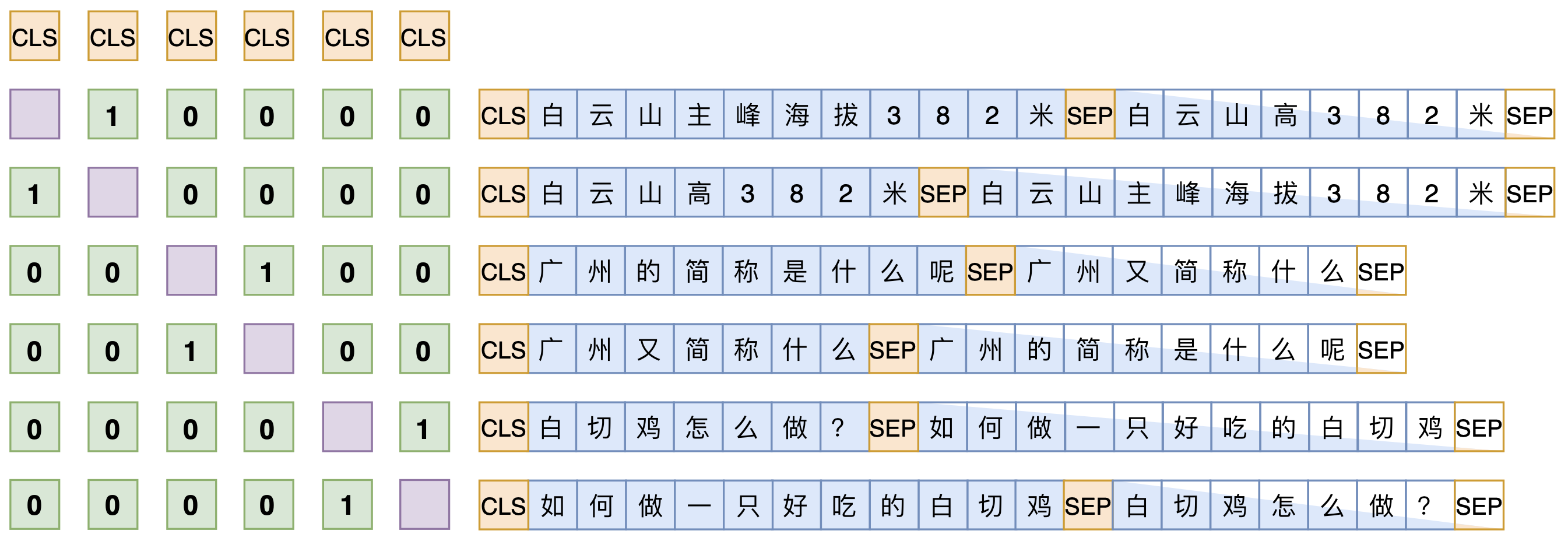
SimBERT训练方式示意图
假设SENT_a和SENT_b是一组相似句,那么在同一个batch中,把[CLS] SENT_a [SEP] SENT_b [SEP]和[CLS] SENT_b [SEP] SENT_a [SEP]都加入训练,做一个相似句的生成任务,这是Seq2Seq部分。
另一方面,把整个batch内的[CLS]向量都拿出来,得到一个句向量矩阵$\boldsymbol{V}\in\mathbb{R}^{b\times d}$($b$是batch_size,$d$是hidden_size),然后对$d$维度做$l_2$归一化,得到$\tilde{\boldsymbol{V}}$,然后两两做内积,得到$b\times b$的相似度矩阵$\tilde{\boldsymbol{V}}\tilde{\boldsymbol{V}}^{\top}$,接着乘以一个scale(我们取了30),并mask掉对角线部分,最后每一行进行softmax,作为一个分类任务训练,每个样本的目标标签是它的相似句(至于自身已经被mask掉)。说白了,就是把batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。
说到底,关键就是“[CLS]的向量事实上就代表着输入的句向量”,所以可以用它来做一些NLU相关的事情。最后的loss是Seq2Seq和相似句分类两部分loss之和。
其他细节 #
由于已经开放源码,所以更多的训练细节大家可以自行阅读源码。模型使用keras + bert4keras实现,代码还是很清晰的,所以很多疑惑应该都可以通过阅读源码解决。
效果演示:
>>> gen_synonyms(u'微信和支付宝哪个好?')
[
u'微信和支付宝,哪个好?',
u'微信和支付宝哪个好',
u'支付宝和微信哪个好',
u'支付宝和微信哪个好啊',
u'微信和支付宝那个好用?',
u'微信和支付宝哪个好用',
u'支付宝和微信那个更好',
u'支付宝和微信哪个好用',
u'微信和支付宝用起来哪个好?',
u'微信和支付宝选哪个好',
u'微信好还是支付宝比较用',
u'微信与支付宝哪个',
u'支付宝和微信哪个好用一点?',
u'支付宝好还是微信',
u'微信支付宝究竟哪个好',
u'支付宝和微信哪个实用性更好',
u'好,支付宝和微信哪个更安全?',
u'微信支付宝哪个好用?有什么区别',
u'微信和支付宝有什么区别?谁比较好用',
u'支付宝和微信哪个好玩'
]
>>> most_similar(u'怎么开初婚未育证明', 20)
[
(u'开初婚未育证明怎么弄?', 0.9728098),
(u'初婚未育情况证明怎么开?', 0.9612292),
(u'到哪里开初婚未育证明?', 0.94987774),
(u'初婚未育证明在哪里开?', 0.9476072),
(u'男方也要开初婚证明吗?', 0.7712214),
(u'初婚证明除了村里开,单位可以开吗?', 0.63224965),
(u'生孩子怎么发', 0.40672967),
(u'是需要您到当地公安局开具变更证明的', 0.39978087),
(u'淘宝开店认证未通过怎么办', 0.39477515),
(u'您好,是需要当地公安局开具的变更证明的', 0.39288986),
(u'没有工作证明,怎么办信用卡', 0.37745982),
(u'未成年小孩还没办身份证怎么买高铁车票', 0.36504325),
(u'烟草证不给办,应该怎么办呢?', 0.35596085),
(u'怎么生孩子', 0.3493368),
(u'怎么开福利彩票站', 0.34158638),
(u'沈阳烟草证怎么办?好办不?', 0.33718678),
(u'男性不孕不育有哪些特征', 0.33530876),
(u'结婚证丢了一本怎么办离婚', 0.33166665),
(u'怎样到地税局开发票?', 0.33079252),
(u'男性不孕不育检查要注意什么?', 0.3274408)
]大家可能比较关心训练数据的问题,这里统一回答:关于训练数据,不方便公开,私下分享也不方便,所以就不要问数据的事情了,数据来源就是爬取百度知道推荐的相似问,然后经过简单算法过滤。如果读者手头上本身有很多问句,那么其实也可以通过常见的检索算法检索出一些相似句,作为训练数据用。总而言之,训练数据没有特别严格要求,理论上有一定的相似性都可以。
至于训练硬件,开源的模型是在一张TITAN RTX(22G显存,batch_size=128)上训练了4天左右,显存和时间其实也没有硬性要求,视实际情况而定,如果显存没那么大,那么适当降低batch_size即可,如果语料本身不是很多,那么训练时间也不用那么长(大概是能完整遍历几遍数据集即可)。
暂时就只能想到这些了,还有啥问题欢迎留言讨论。
文章小结 #
本文介绍了早先我们放出来的SimBERT模型的训练原理,并开源了训练代码。SimBERT通过基于UniLM思想进行训练,同时具备检索和生成的能力,欢迎大家使用测试~
转载到请包括本文地址:https://kexue.fm/archives/7427
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 18, 2020). 《鱼与熊掌兼得:融合检索和生成的SimBERT模型 》[Blog post]. Retrieved from https://kexue.fm/archives/7427
@online{kexuefm-7427,
title={鱼与熊掌兼得:融合检索和生成的SimBERT模型},
author={苏剑林},
year={2020},
month={May},
url={\url{https://kexue.fm/archives/7427}},
}

May 18th, 2020
强强
我试过直接用Unilm作相似句,没有做cls的操作,比较容易出现identity的句子,可能跟语料有关,在想有没有什么约束loss的方法减少identity预测的出现
解码是用beam search解码还是随机采样解码?
May 27th, 2020
苏神,本人使用你开源的模型和代码,在进行NSP任务的fine-tune时,发现 `cls/seq_relationship/output_weights`这个参数名不在模型ckpt中,如果之前没训练过,则是否应该返回一个初始化的参数呢,否则fine-tune应该怎么去做?
之前确实没考虑这个。不过你可以加载好编码器部分,然后自己把CLS向量拿出来,然后再接一个随机初始化的分类层。
嗯嗯,感谢!
May 29th, 2020
请问最后softmax这会存在多标签的情况吗,还是保证每个batch只有一个正样本?
由于样本打乱过,所以一个batch内多个正样本的概率比较小,就算有也有无所谓了,就当是随机噪声吧。
了解了
June 24th, 2020
苏神,您好。
我用bert-as-serving调用bert向量用来做句向量的相似度匹配,使用了您的simBert模型,效果确实更好。
若将bert替换为tiny或者small版的albert是否也应该能提升?
我尝试了将bert换为albert的small版进行训练,再用bert-as-serving调用,发现效果比未训练的albert_small差。
这是因为数据的原因还是albert本身就不适合做UniLM
数据原因吧,albert也可以做unilm。但是albert tiny/small限制太大,用来做生成可能强模型所难了。建议用robert tiny/small (https://github.com/ZhuiyiTechnology/pretrained-models)
您是怎么在 bert-as-serving 种使用 simBert的, 可以分享一下?
July 4th, 2020
问一下,如果不考虑生成,仅仅考虑检索效果,那损失函数那里使用batch内其它样本作为负样本的方式和提前在训练数据中添加负样本的方式哪种更好?照我看来后者可能更直接一些,前者更像是使用了dssm的架构,并且正负样本对之间包含了4条语句,看起来怪怪的。您有对比过这两种方式吗?
首先,本文已经说了,虽然每个样本是两个句子concat起来的,但是cls只跟第一个句子有关,所欲每个样本的cls只有一个句子。
然后,你自己指定负样本的话,得看你的负样本策略,如果你的负样本本身也是随机抽取的,那么肯定不如simbert的训练策略高效。如果你能通过某些策略得到难度偏高的负样本,那可能效果会更好些。
July 7th, 2020
嗷,懂了。感谢回复
July 8th, 2020
苏神,您好,用了您的simbert模型,效果确实很好,目前我也在搭建自己的数据集,请问一下您对爬取的算法做过怎样的过滤?我用简单的相似度算法(比如jaccard),其实也不能很好的判断文本的语义相似性。
我就是用词级别的jaccard相似度。其实训练语料能体现一定的语义相似就好,不用太完美,神经网络会自动泛化好的。
好的,谢谢了!
1.语料不咋好,神经网络会自动泛化好的,有什么根据吗?
2.其次语料通过增强得到的句子,例如可能该句子不是人话。这样会影响吗
3.如果是一些相关性的句子而不是语义相似会对模型有什么影响。例如KB类似的知识库里句子。
1.依据是“正确的都是相似的,错误的各有各的错误”,所以当数据足够多时,正确的效应能叠加,错误的效应有可能相互抵消;
2.有影响,所以不要用比较机械的语料增强方法;
3.何为“相关”又“不语义相似”?我个人认为很难做到太完美,相似本身是一个很主观的事情。
July 14th, 2020
def get_labels_of_similarity(self, y_pred):
idxs = K.arange(0, K.shape(y_pred)[0])
idxs_1 = idxs[None, :]
idxs_2 = (idxs + 1 - idxs % 2 * 2)[:, None]
labels = K.equal(idxs_1, idxs_2)
labels = K.cast(labels, K.floatx())
return labels
这段代码没看懂怎么生成labels的,有可以解释下的么
随便代入一个y_pred,逐行eval和print
苏神,请问你是怎么想到用这个公式实现的啊,我还看了你unilm的mask生成,感觉可牛逼了。有没有推荐练习和学习的东西,可以做到你这样mask矩阵生成信手拈来呢?
强迫症使然吧,有种努力想要将代码简化的冲动。这东西没啥好练习的,就是一种意识吧~
July 20th, 2020
苏神,
“因为UniLM特殊的Attention Mask,所以[CLS] 你 想 吃 啥 [SEP]这6个token只在它们之间相互做Attention,而跟白 切 鸡 [SEP]完全没关系,这就意味着,尽管后面拼接了白 切 鸡 [SEP],但这不会影响到前6个编码向量。”得到结论是:‘[CLS]的向量事实上就代表着输入的句向量’。如果但从双向attention原因出发是否应该得到:‘编码器阶段任意token都可代表输入句向量’这样的结论?
是的,没毛病。你可以不拿CLS,你可以拿第二个、第三个token对应的向量作为句向量,或者全体token的平均向量,都没有问题。只要在所有句子中都固定这个选择,然后在检索任务中训练就行了。
July 24th, 2020
苏神,我跑simbert.py的时候为什么会出现
AttributeError: type object 'AutoRegressiveDecoder' has no attribute 'set_rtype'
的错误?
解决了,改成wraps就好了