






24
Nov
生成扩散模型漫谈(三十一):预测数据而非噪声
By 苏剑林 | 2025-11-24 | 26386位读者 | 引用时至今日,LDM(Latent Diffusion Models)依旧是扩散模型的主流范式。借助Encoder对原始图像进行高倍压缩,LDM能显著减少训练与推理的计算成本,同时还能降低训难度,可谓一举多得。然而,高倍压缩也意味着信息损失,而且“压缩、生成、解压缩”的流水线也少了些端到端的美感。因此,始终有一部分人执着于“回到像素空间”,希望让扩散模型直接在原始数据上完成生成。
本文要介绍的《Back to Basics: Let Denoising Generative Models Denoise》正是这一思路的新工作,它基于原始数据往往处于低维子流形这一事实,提出模型应预测数据而不是噪声,由此得到“JiT(Just image Transformers)”,显著地简化了像素空间的扩散模型架构。
信噪之比
毋庸置疑,当今扩散模型的“主力军”依然是LDM,即便是前段时间颇为热闹的RAE,也只是声称LDM的Encoder已经“过时”了,要给它换一个新的更强的Encoder,但依然没改变“先压缩后生成”这一模式。
8
Oct
DiVeQ:一种非常简洁的VQ训练方案
By 苏剑林 | 2025-10-08 | 33584位读者 | 引用对于坚持离散化路线的研究人员来说,VQ(Vector Quantization)是视觉理解和生成的关键部分,担任着视觉中的“Tokenizer”的角色。它提出在2017年的论文《Neural Discrete Representation Learning》,笔者在2019年的博客《VQ-VAE的简明介绍:量子化自编码器》也介绍过它。
然而,这么多年过去了,我们可以发现VQ的训练技术几乎没有变化,都是STE(Straight-Through Estimator)加额外的Aux Loss。STE倒是没啥问题,它可以说是给离散化运算设计梯度的标准方式了,但Aux Loss的存在总让人有种不够端到端的感觉,同时还引入了额外的超参要调。
幸运的是,这个局面可能要结束了,上周的论文《DiVeQ: Differentiable Vector Quantization Using the Reparameterization Trick》提出了一个新的STE技巧,它最大亮点是不需要Aux Loss,这让它显得特别简洁漂亮!
5
Oct
为什么线性注意力要加Short Conv?
By 苏剑林 | 2025-10-05 | 42318位读者 | 引用如果读者有关注模型架构方面的进展,那么就会发现,比较新的线性Attention(参考《线性注意力简史:从模仿、创新到反哺》)模型都给$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$加上了Short Conv,比如下图所示的DeltaNet:
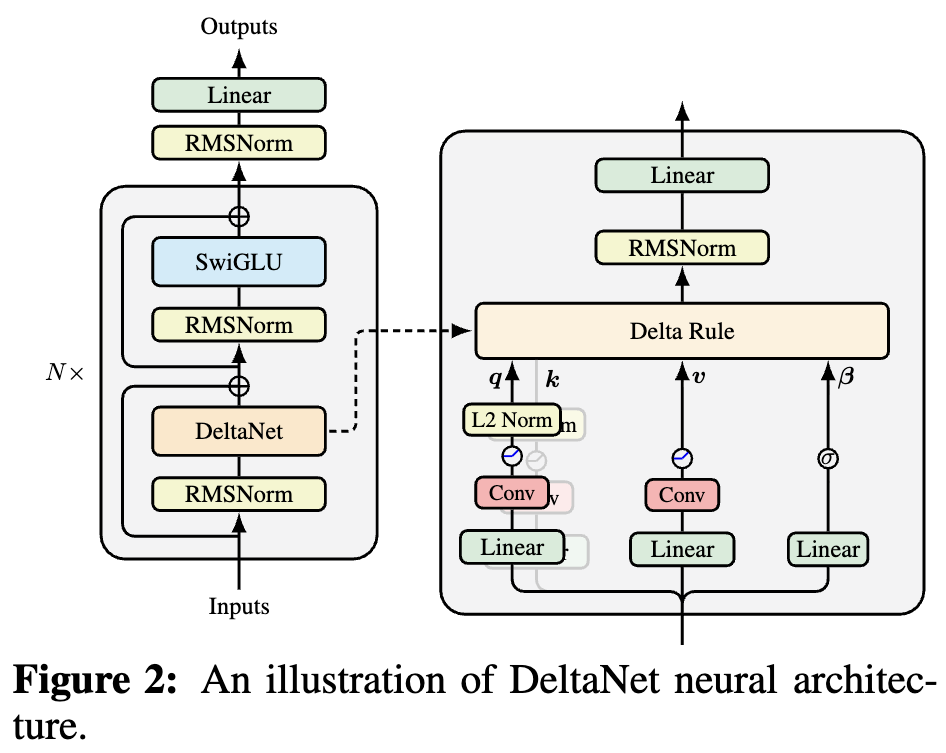
DeltaNet中的Short Conv
为什么要加这个Short Conv呢?直观理解可能是增加模型深度、增强模型的Token-Mixing能力等,说白了就是补偿线性化导致的表达能力下降。这个说法当然是大差不差,但它属于“万能模版”式的回答,我们更想对它的生效机制有更准确的认知。
接下来,笔者将给出自己的一个理解(更准确说应该是猜测)。
10
Jul
Transformer升级之路:21、MLA好在哪里?(下)
By 苏剑林 | 2025-07-10 | 78835位读者 | 引用
20
Jun
线性注意力简史:从模仿、创新到反哺
By 苏剑林 | 2025-06-20 | 102242位读者 | 引用在中文圈,本站应该算是比较早关注线性Attention的了,在2020年写首篇相关博客《线性Attention的探索:Attention必须有个Softmax吗?》时,大家主要讨论的还是BERT相关的Softmax Attention。事后来看,在BERT时代考虑线性Attention并不是太明智,因为当时训练长度比较短,且模型主要还是Encoder,用线性Attention来做基本没有优势。对此,笔者也曾撰文《线性Transformer应该不是你要等的那个模型》表达这一观点。
直到ChatGPT的出世,倒逼大家都去做Decoder-only的生成式模型,这跟线性Attention的RNN形式高度契合。同时,追求更长的训练长度也使得Softmax Attention的二次复杂度瓶颈愈发明显。在这样的新背景下,线性Attention越来越体现出竞争力,甚至出现了“反哺”Softmax Attention的迹象。
26
May
生成扩散模型漫谈(三十):从瞬时速度到平均速度
By 苏剑林 | 2025-05-26 | 88027位读者 | 引用众所周知,生成速度慢是扩散模型一直以来的痛点,而为了解决这个问题,大家可谓“八仙过海,各显神通”,提出了各式各样的解决方案,然而长久以来并没一项工作能够脱颖而出,成为标配。什么样的工作能够达到这个标准呢?在笔者看来,它至少满足几个条件:
1、数学原理清晰,能够揭示出快速生成的本质所在;
2、能够单目标从零训练,不需要对抗、蒸馏等额外手段;
3、单步生成接近SOTA,可以通过增加步数提升效果。
根据笔者的阅读经历,几乎没有一项工作能同时满足这三个标准。然而,就在几天前,arXiv出了一篇《Mean Flows for One-step Generative Modeling》(简称“MeanFlow”),看上去非常有潜力。接下来,我们将以此为契机,讨论一下相关思路和进展。
4
May
Transformer升级之路:20、MLA好在哪里?(上)
By 苏剑林 | 2025-05-04 | 92662位读者 | 引用自从DeepSeek爆火后,它所提的Attention变体MLA(Multi-head Latent Attention)也愈发受到关注。MLA通过巧妙的设计实现了MHA与MQA的自由切换,使得模型可以根据训练和推理的不同特性(Compute-Bound or Memory-Bound)选择最佳的形式,尽可能地达到效率最大化。
诚然,MLA很有效,但也有观点认为它不够优雅,所以寻找MLA替代品的努力一直存在,包括我们也有在尝试。然而,经过一段时间的实验,我们发现很多KV Cache相同甚至更大的Attention变体,最终效果都不如MLA。这不得不让我们开始反思:MLA的出色表现背后的关键原因究竟是什么?
接下来,本文将详细介绍笔者围绕这一问题的思考过程以及相关实验结果。
观察
MLA提出自DeepSeek-V2,本文假设读者已经熟悉MLA,至少了解之前的博客《缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA》所介绍的内容,因此MLA自身的细节将不会过多展开。
14
Feb
生成扩散模型漫谈(二十九):用DDPM来离散编码
By 苏剑林 | 2025-02-14 | 68389位读者 | 引用笔者前两天在arXiv刷到了一篇新论文《Compressed Image Generation with Denoising Diffusion Codebook Models》,实在为作者的天马行空所叹服,忍不住来跟大家分享一番。
如本文标题所述,作者提出了一个叫DDCM(Denoising Diffusion Codebook Models)的脑洞,它把DDPM的噪声采样限制在一个有限的集合上,然后就可以实现一些很奇妙的效果,比如像VQVAE一样将样本编码为离散的ID序列并重构回来。注意这些操作都是在预训练好的DDPM上进行的,无需额外的训练。
有限集合
由于DDCM只需要用到一个预训练好的DDPM模型来执行采样,所以这里我们就不重复介绍DDPM的模型细节了,对DDPM还不大了解的读者可以回顾我们《生成扩散模型漫谈》系列的(一)、(二)、(三)篇。

最近评论