






30
Apr
当概率遇上复变:随机游走基本公式
By 苏剑林 | 2014-04-30 | 60254位读者 | 引用
2
Jul
[追溯]封装界传奇人物
By 苏剑林 | 2014-07-02 | 19164位读者 | 引用转载理由:现在的deepin和ylmf(已经改为StartOs)都已经在制作自己的Linux,而当初它们都是制作GhostXp的大家。我的初中,即2009年以前,是GhostXP流行的时代,而我当时也加入了这一行列中,发表过一些GhostXP的作品。后来随着时代的发展,XP也就慢慢退出了舞台。我也就随之退出了这个舞台,也因此得以专注科学。但是,几乎所有我的电脑知识,都积累于那个时期,因为为了完成一个系统的制作和推广,需要懂得的电脑技术很多很多,我也得到了充分的锻炼。下面列举的一些人,都是当年GhostXP界的神话人物,有些我并不认识,但其名在当时就如雷贯耳;有些人在当时还十分幸运地加上了他们的QQ。这篇文章实际上已经是很久已经的了,但还是值得回味过去的时间,以此为我的初中时代留下一些回忆。
30
Jul
素数之美1:所有素数之积
By 苏剑林 | 2014-07-30 | 32986位读者 | 引用在之前的欧拉数学中,我们计算过所有素数的倒数之和,得出素数的倒数之和是发散的,从而这也是一个关于素数个数为无穷的证明。在本篇文章中,我们尝试计算所有素数之积,通过一个简单的技巧,得到素数之积的一个上限(以后我们也会计算下限),从而也得到$\pi(n)$的一个上限公式。更重要的,该估计是初等地证明Bertrand假设(说的是n与2n之间定有一个素数)的重要基础之一。本文内容部分参考自《数学天书中的证明》和《解析和概率数论导引》。
素数之积
笔者已经说过,数论的神奇之处就是它总是出人意料地把数学的不同领域联系了起来。读者很快就可以看到,本文的证明和组合数学有重要联系(但仅仅是简单的联系)。关于素数之积,我们有以下结论:
不超过$n$的所有素数之积小于$4^{n-1}$。
17
Aug
从费马大定理谈起(四):唯一分解整环
By 苏剑林 | 2014-08-17 | 43895位读者 | 引用在小学的时候,数学老师就教我们除法运算:
被除数 = 除数 × 商 + 余数
其中,余数要小于除数。不过,我们也许未曾想到过,这一运算的成立,几乎是自然数$\mathbb{N}$所有算术(数论)运算性质成立的基础!在代数中,上面的运算等式称为带余除法(division algorithm)。如果在一个整环中成立带余除法,那么该整环几乎就拥有了所有理想的性质,比如唯一分解性,也就是我们说的算术基本定理。这样的一个整环,被称为唯一分解整环(Unique factorization domain)。
欧几里得整环

Euklid-von-Alexandria_1
唯一分解定理说的是在一个整环之中,所有的元素都可以分解为该整环的某些“素元素”之积,并且在不考虑元素相乘的顺序和相差单位数的意义之下,分解形式是唯一的。我们通常说的自然数就成立唯一分解定理,比如$60=2^2\times 3\times 5$,这种分解是唯一的,这看起来相当显然,但实际上唯一分解定理相当不显然。首先,并不是所有的整数环都成立唯一分解定理的,我们考虑所有偶数组成的环$2\mathbb{Z}$,要注意,在$2\mathbb{Z}$中,2、6、10、30都是素数,因为它们无法分解成两个偶数的乘积了,但是$60=6\times 10=2\times 30$,存在两种不同的分解,因此在这样的数环中,唯一分解定理就不成立了。
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 198641位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
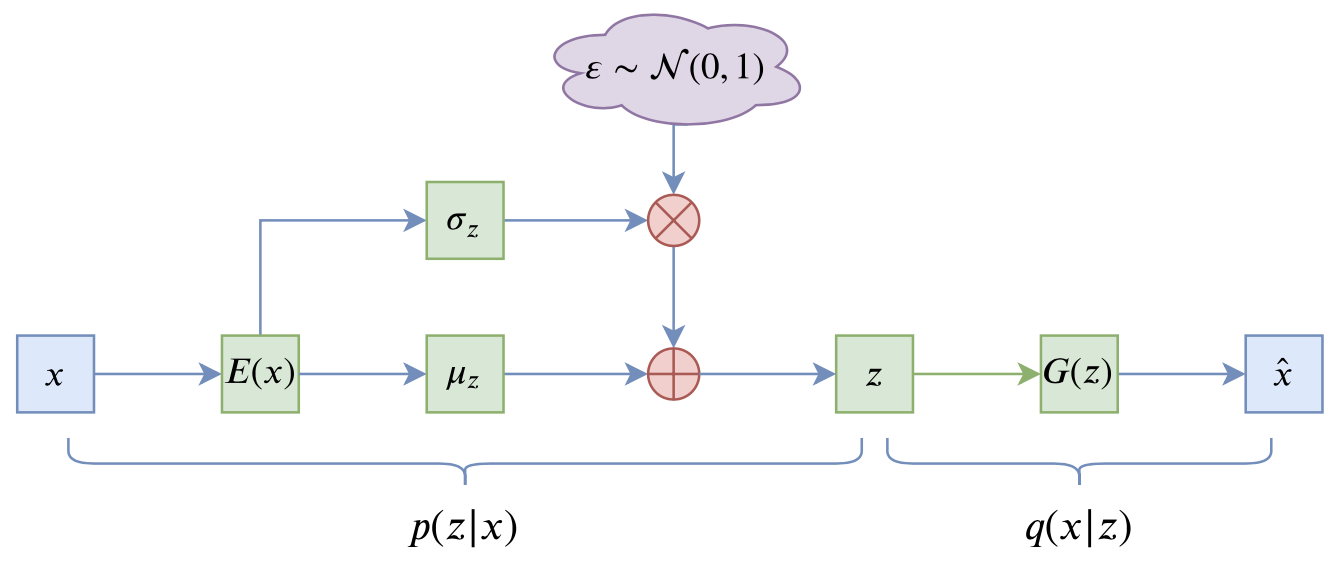
VAE训练流程图示
17
Nov
[转载] 做数学一定要是天才吗?
By 苏剑林 | 2014-11-17 | 28603位读者 | 引用(译自 陶哲轩 博客, 译者 liuxiaochuang)
(英文原文:Does one have to be a genius to do maths?)
这个问题的回答是一个大写的:不!为了达到对数学有一个良好的,有意义的贡献的目的,人们必须要刻苦努力;学好自己的领域,掌握一些其他领域的知识和工具;多问问题;多与其他数学工作者交流;要对数学有个宏观的把握。当然,一定水平的才智,耐心的要求,以及心智上的成熟性是必须的。但是,数学工作者绝不需要什么神奇的“天才”的基因,什么天生的洞察能力;不需要什么超自然的能力使自己总有灵感去出人意料的解决难题。
大众对数学家的形象有一个错误的认识:这些人似乎都使孤单离群的(甚至有一点疯癫)天才。他们不去关注其他同行的工作,不按常规的方式思考。他们总是能够获得无法解释的灵感(或者经过痛苦的挣扎之后突然获得),然后在所有的专家都一筹莫展的时候,在某个重大的问题上取得了突破的进展。这样浪漫的形象真够吸引人的,可是至少在现代数学学科中,这样的人或事是基本没有的。在数学中,我们的确有很多惊人的结论,深刻的定理,但是那都是经过几年,几十年,甚至几个世纪的积累,在很多优秀的或者伟大的数学家的努力之下一点一点得到的。每次从一个层次到另一个层次的理解加深的确都很不平凡,有些甚至是非常的出人意料。但尽管如此,这些成就也无不例外的建立在前人工作的基础之上,并不是全新的。(例如, Wiles 解决费马最后定理的工作,或者Perelman 解决庞加莱猜想的工作。)
26
Aug
fashion-mnist的gan玩具
By 苏剑林 | 2017-08-26 | 58385位读者 | 引用
fashion_mnist_demo
mnist的手写数字识别数据集一直是各种机器学习算法的试金石之一,最近有个新的数据集要向它叫板,称为fashion-mnist,内容是衣服鞋帽等分类。为了便于用户往fashion-mnist迁移,作者把数据集做成了几乎跟mnist手写数字识别数据集一模一样——同样数量、尺寸的图片,同样是10分类,甚至连数据打包和命名都跟mnist一样。看来fashion mnist为了取代mnist,也是拼了,下足了功夫,一切都做得一模一样,最大限度降低了使用成本~这叫板的心很坚定呀。
叫板的原因很简单——很多人吐槽,如果一个算法在mnist没用,那就一定没用了,但如果一个算法在mnist上有效,那它也不见得在真实问题中有效~也就是说,这个数据集太简单,没啥代表性。
fashion-mnist的github:https://github.com/zalandoresearch/fashion-mnist/
6
May
记录一次爬取淘宝/天猫评论数据的过程
By 苏剑林 | 2015-05-06 | 168718位读者 | 引用笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行。对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了。本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似的做法,不赘述。主要是分析页面以及用Python实现简单方便的抓取。
笔者使用的工具如下
Python 3——极其方便的编程语言。选择3.x的版本是因为3.x对中文处理更加友好。
Pandas——Python的一个附加库,用于数据整理。
IE 11——分析页面请求过程(其他类似的流量监控工具亦可)。
剩下的还有requests,re,这些都是Python自带的库。
实例页面(美的某热水器):http://detail.tmall.com/item.htm?id=41464129793

最近评论