






16
Oct
Cool Papers浏览器扩展升级至v0.2.0
By 苏剑林 | 2024-10-16 | 23944位读者 | 引用年初,我们在《更便捷的Cool Papers打开方式:Chrome重定向扩展》中发布了一个Chrome浏览器插件(Cool Papers Redirector v0.1.0),可以通过右击菜单从任意页面中重定向到Cool Papers中,让大家更方便地获取Kimi对论文的理解。前几天我们把该插件升级到了v0.2.0,并顺利上架到了Chrome应用商店中,遂在此向大家推送一下。
更新汇总
相比旧版v0.1.0,当前版v0.2.0的主要更新内容如下:
1、右键菜单跳转改为在新标签页打开;
2、右键菜单支持同时访问多个论文ID;
3、右键菜单支持PDF页面;
4、右键菜单新增更多论文源(arXiv、OpenReview、ACL、IJCAI、PMLR);
5、右键菜单在搜索不到论文ID时,转入站内搜索(即划词搜索);
6、在某些网站的适当位置插入快捷跳转链接(arXiv、OpenReview,ACL)。
7
Feb
年三十折腾极路由之SSH反向代理
By 苏剑林 | 2016-02-07 | 65038位读者 | 引用
猴年快乐!
今天是年三十了,这里简单祝大家除夕快乐,新年快乐!愿大家在新的一年里都晋升为学神。^_^
这两天主要在折腾家里的路由器。平时家里只有爸妈两人,所以为了节省,家里只是通过中继隔壁家的网络来上网。本来家里用小米路由器mini,可是小米mini中继模式下功能限制非常多,我又不想刷第三方固件(因为这样会失去app控制功能,不是很方便),所以干脆换了个极路由3。极路由在中继模式下仍然保留了大部分功能(我觉得这样才是正常的,我不理解小米mini在中继之后就没了那么多功能究竟是什么逻辑)。
作为折腾派,一个新路由到手,总有很多东西要配置,极路由本身是基于openwrt的,因此可玩性也很强。首先要完成中继,然后上网,这个很简单就不多说了。其次是获得ssh权限,在极路由那里叫做“申请开发者模式”,或者叫root(感觉极路由想做路由界的苹果,但是在如今这个时代,苹果当初那种发展模式估计很难发展起来了),这个步骤也不难,不过申请之后就会失去极路由的保修资格(不理解这是什么逻辑)。
本文主要介绍了怎么在openwrt(极路由)上安装python,以及建立SSH反向代理(实现内网穿透)。
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 229820位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
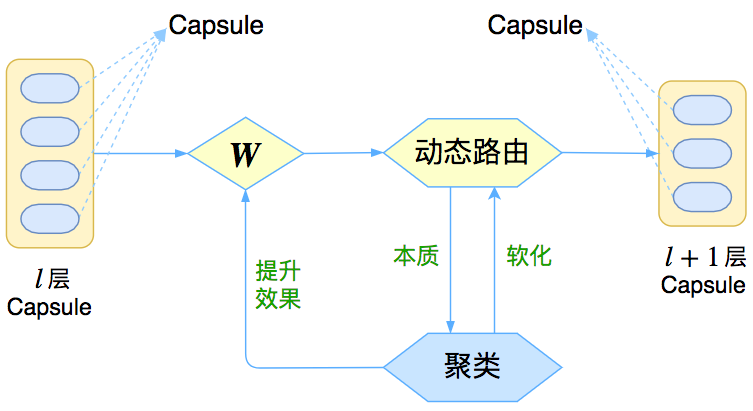
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 145981位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。
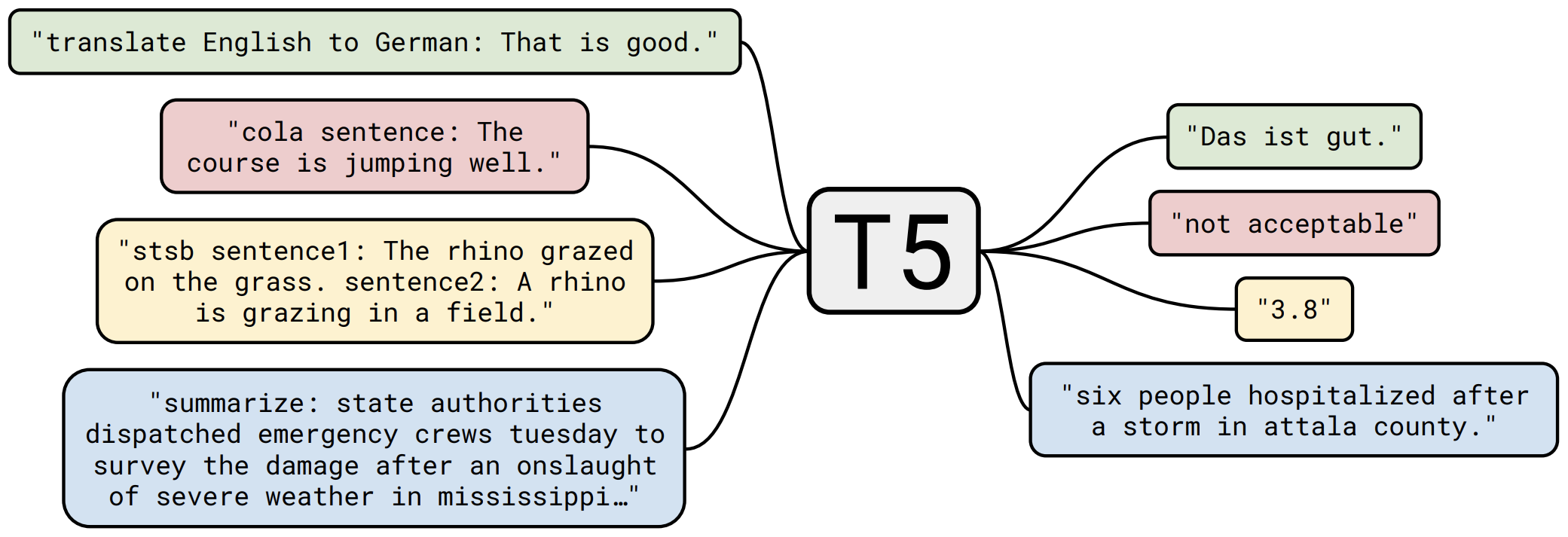
“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。
24
May
重温SSM(一):线性系统和HiPPO矩阵
By 苏剑林 | 2024-05-24 | 67212位读者 | 引用前几天,笔者看了几篇介绍SSM(State Space Model)的文章,才发现原来自己从未认真了解过SSM,于是打算认真去学习一下SSM的相关内容,顺便开了这个新坑,记录一下学习所得。
SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的S4,不算太老,而SSM最新最火的变体大概是去年的Mamba。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样RWKV、RetNet还有此前我们在《Google新作试图“复活”RNN:RNN能否再次辉煌?》介绍过的LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。
尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作《HiPPO: Recurrent Memory with Optimal Polynomial Projections》(简称HiPPO),所以本文从HiPPO开始说起。
24
Mar
高阶muP:更简明但更高明的谱条件缩放
By 苏剑林 | 2025-03-24 | 4999位读者 | 引用在文章《初探muP:超参数的跨模型尺度迁移规律》中,我们基于前向传播、反向传播、损失增量和特征变化的尺度不变性推导了muP(Maximal Update Parametrization)。可能对于部分读者来说,这一过程还是显得有些繁琐,但实际上它比原始论文已经明显简化。要知道,我们是在单篇文章内相对完整地介绍的muP,而muP的论文实际上是作者Tensor Programs系列论文的第5篇!
不过好消息是,作者在后续的研究《A Spectral Condition for Feature Learning》中,发现了一种新的理解方式(下称“谱条件”),它比muP的原始推导和笔者的推导都更加直观和简洁,但却能得到比muP更丰富的结果,可谓muP的高阶版本,简明且不失高明的代表作。
准备工作
顾名思义,谱条件(Spectral Condition)跟谱范数(Spectral Norm)相关,它的出发点是谱范数的一个基本不等式:
\begin{equation}\Vert\boldsymbol{x}\boldsymbol{W}\Vert_2\leq \Vert\boldsymbol{x}\Vert_2 \Vert\boldsymbol{W}\Vert_2\label{neq:spec-2}\end{equation}
26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 346821位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
16
Jul

最近评论