






14
Oct
【理解黎曼几何】1. 一条几何之路
By 苏剑林 | 2016-10-14 | 84510位读者 | 引用一个月没更新了,这个月花了不少时间在黎曼几何的理解方面,有一些体会,与大家分享。记得当初孟岩写的《理解矩阵》,和笔者所写的《新理解矩阵》,读者反响都挺不错的,这次沿用了这个名称,称之为《理解黎曼几何》。

生活在二维空间的蚂蚁
黎曼几何是研究内蕴几何的几何分支。通俗来讲,就是我们可能生活在弯曲的空间中,比如一只生活在二维球面的蚂蚁,作为生活在弯曲空间中的个体,我们并没有足够多的智慧去把我们的弯曲嵌入到更高维的空间中去研究,就好比蚂蚁只懂得在球面上爬,不能从“三维空间的曲面”这一观点来认识球面,因为球面就是它们的世界。因此,我们就有了内蕴几何,它告诉我们,即便是身处弯曲空间中,我们依旧能够测量长度、面积、体积等,我们依旧能够算微分、积分,甚至我们能够发现我们的空间是弯曲的!也就是说,身处球面的蚂蚁,只要有足够的智慧,它们就能发现曲面是弯曲的——跟哥伦布环球航行那样——它们朝着一个方向走,最终却回到了起点,这就可以断定它们自身所处的空间必然是弯曲的——这个发现不需要用到三维空间的知识。
16
Jun
梯度流:探索通向最小值之路
By 苏剑林 | 2023-06-16 | 38895位读者 | 引用在这篇文章中,我们将探讨一个被称为“梯度流(Gradient Flow)”的概念。简单来说,梯度流是将我们在用梯度下降法中寻找最小值的过程中的各个点连接起来,形成一条随(虚拟的)时间变化的轨迹,这条轨迹便被称作“梯度流”。在文章的后半部分,我们将重点讨论如何将梯度流的概念扩展到概率空间,从而形成“Wasserstein梯度流”,为我们理解连续性方程、Fokker-Planck方程等内容提供一个新的视角。
梯度下降
假设我们想搜索光滑函数$f(\boldsymbol{x})$的最小值,常见的方案是梯度下降(Gradient Descent),即按照如下格式进行迭代:
\begin{equation}\boldsymbol{x}_{t+1} = \boldsymbol{x}_t -\alpha \nabla_{\boldsymbol{x}_t}f(\boldsymbol{x}_t)\label{eq:gd-d}\end{equation}
如果$f(\boldsymbol{x})$关于$\boldsymbol{x}$是凸的,那么梯度下降通常能够找到最小值点;相反,则通常只能收敛到一个“驻点”——即梯度为0的点,比较理想的情况下能收敛到一个极小值(局部最小值)点。这里没有对极小值和最小值做严格区分,因为在深度学习中,即便是收敛到一个极小值点也是很难得的了。
15
Sep
低秩近似之路(一):伪逆
By 苏剑林 | 2024-09-15 | 29318位读者 | 引用可能很多读者跟笔者一样,对矩阵的低秩近似有种熟悉而又陌生的感觉。熟悉是因为,低秩近似的概念和意义都不难理解,加之目前诸如LoRA等基于低秩近似的微调技术遍地开花,让低秩近似的概念在耳濡目染间就已经深入人心;然而,低秩近似所覆盖的内容非常广,在低秩近似相关的论文中时常能看到一些不熟悉但又让我们叹为观止的新技巧,这就导致了一种似懂非懂的陌生感。
因此,在这个系列文章中,笔者将试图系统梳理一下矩阵低秩近似相关的理论内容,以补全对低秩近似的了解。而在第一篇文章中,我们主要介绍低秩近似系列中相对简单的一个概念——伪逆。
优化视角
伪逆(Pseudo Inverse),也称“广义逆(Generalized Inverse)”,顾名思义就是“广义的逆矩阵”,它实际上是“逆矩阵”的概念对于不可逆矩阵的推广。
1
Oct
低秩近似之路(二):SVD
By 苏剑林 | 2024-10-01 | 22297位读者 | 引用上一篇文章中我们介绍了“伪逆”,它关系到给定矩阵$\boldsymbol{M}$和$\boldsymbol{A}$(或$\boldsymbol{B}$)时优化目标$\Vert \boldsymbol{A}\boldsymbol{B} - \boldsymbol{M}\Vert_F^2$的最优解。这篇文章我们来关注$\boldsymbol{A},\boldsymbol{B}$都不给出时的最优解,即
\begin{equation}\mathop{\text{argmin}}_{\boldsymbol{A},\boldsymbol{B}}\Vert \boldsymbol{A}\boldsymbol{B} - \boldsymbol{M}\Vert_F^2\label{eq:loss-ab}\end{equation}
其中$\boldsymbol{A}\in\mathbb{R}^{n\times r}, \boldsymbol{B}\in\mathbb{R}^{r\times m}, \boldsymbol{M}\in\mathbb{R}^{n\times m},r < \min(n,m)$。说白了,这就是要寻找矩阵$\boldsymbol{M}$的“最优$r$秩近似(秩不超过$r$的最优近似)”。而要解决这个问题,就需要请出大名鼎鼎的“SVD(奇异值分解)”了。虽然本系列把伪逆作为开篇,但它的“名声”远不如SVD,听过甚至用过SVD但没听说过伪逆的应该大有人在,包括笔者也是先了解SVD后才看到伪逆。
接下来,我们将围绕着矩阵的最优低秩近似来展开介绍SVD。
结论初探
对于任意矩阵$\boldsymbol{M}\in\mathbb{R}^{n\times m}$,都可以找到如下形式的奇异值分解(SVD,Singular Value Decomposition):
\begin{equation}\boldsymbol{M} = \boldsymbol{U}\boldsymbol{\Sigma} \boldsymbol{V}^{\top}\end{equation}
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 366433位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
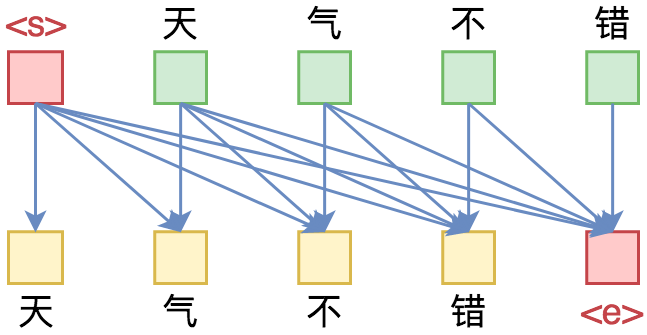
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
13
Apr
突破瓶颈,打造更强大的Transformer
By 苏剑林 | 2020-04-13 | 144614位读者 | 引用自《Attention is All You Need》一文发布后,基于Multi-Head Attention的Transformer模型开始流行起来,而去年发布的BERT模型更是将Transformer模型的热度推上了又一个高峰。当然,技术的探索是无止境的,改进的工作也相继涌现:有改进预训练任务的,比如XLNET的PLM、ALBERT的SOP等;有改进归一化的,比如Post-Norm向Pre-Norm的改变,以及T5中去掉了Layer Norm里边的beta参数等;也有改进模型结构的,比如Transformer-XL等;有改进训练方式的,比如ALBERT的参数共享等;...
以上的这些改动,都是在Attention外部进行改动的,也就是说它们都默认了Attention的合理性,没有对Attention本身进行改动。而本文我们则介绍关于两个新结果:它们针对Multi-Head Attention中可能存在建模瓶颈,提出了不同的方案来改进Multi-Head Attention。两篇论文都来自Google,并且做了相当充分的实验,因此结果应该是相当有说服力的了。
再小也不能小key_size
第一个结果来自文章《Low-Rank Bottleneck in Multi-head Attention Models》,它明确地指出了Multi-Head Attention里边的表达能力瓶颈,并提出通过增大key_size的方法来缓解这个瓶颈。
3
Feb
让研究人员绞尽脑汁的Transformer位置编码
By 苏剑林 | 2021-02-03 | 237135位读者 | 引用不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:1、想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;2、想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。
虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。
绝对位置编码
形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第$k$个向量$\boldsymbol{x}_k$中加入位置向量$\boldsymbol{p}_k$变为$\boldsymbol{x}_k + \boldsymbol{p}_k$,其中$\boldsymbol{p}_k$只依赖于位置编号$k$。
24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 67426位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:

最近评论