






22
Sep
实数集到无理数集的双射
By 苏剑林 | 2014-09-22 | 37397位读者 | 引用集合论的结果告诉我们,全体实数的集合$\mathbb{R}$跟全体无理数的集合$\mathbb{R} \backslash \mathbb{Q}$是等势的,那么,如何构造出它们俩之间的一个双射出来呢?这是一个颇考读者想象力的问题。当然,如果把答案给出来,又似乎显得没有那么神秘。下面给出笔者构造的一个例子,读者可以从中看到这种映射是怎么构造的。
为了构造这样的双射,一个很自然的想法是,让全体有理数和部分无理数在它们自身内相互映射,剩下的无理数则恒等映射。构造这样的一个双射首先得找出一个函数,它的值只会是无理数。要找到这样的函数并不难,比如我们知道:
1、方程$x^4 + 1 = y^2$没有除$x=0,y=\pm 1$外的有理点,否则将与费马大定理$n=4$时的结果矛盾。
2、无理数的平方根依然是无理数。
根据这些信息,足以构造一个正实数$\mathbb{R}^+$到正无理数$\mathbb{R}^+ \backslash \mathbb{Q}^+$的双射,然后稍微修改一下,就可以得到$\mathbb{R}$到$\mathbb{R} \backslash \mathbb{Q}$的双射。
集合上的一个等价关系决定了几何的一个划分,反之亦然,这直观上是不难理解的。但是,如果我要问一个有$n$个元素的有限集合,共有多少种不同的划分呢?以前感觉这也是一个很简单的问题,就没去细想,但前天抽象代数老师提到这是一个有相当难度的题目,于是研究了一下,发现里面大有文章。这里把我的研究过程简单分享一下,读者可以从中看到如何“从零到有”的过程。
以下假设有$n$个元素的有限集合为$\{1,2,\dots,n\}$,记它的划分数为$B(n)$。
前期:暴力计算
$n=3$的情况不难列出:
$$\begin{aligned}&\{\{1,2,3\}\},\{\{1,2\},\{3\}\},\{\{1,3\},\{2\}\},\\
&\{\{2,3\},\{1\}\},\{\{1\},\{2\},\{3\}\}\end{aligned}$$
17
Oct
两百万素数之和与“电脑病”
By 苏剑林 | 2014-10-17 | 16010位读者 | 引用原则上来讲,同样的算法,如果分别在Python和C++上实现,那么Python的速度肯定比不上C++的。但是Python还被称为“胶水语言”,它允许我们把主要计算的部分用C或C++等高效的语言编写好,然后它作为“粘合剂”把两者粘合在一起。正因为如此,Python才有了各种各样的扩展库,这些库中有不少是用C语言编写的。因此,我们在编写Python程序的时候,如果可以用这些现成的库,速度会快很多。本文就是用Numpy来改进之前的《两百万前素数之和与前两百万素数之和》的计算。
算法本身是没有变的,只是用了Numpy来处理数组计算,代码如下:
25
Oct
从费马大定理谈起(十二):再谈谈切线法
By 苏剑林 | 2014-10-25 | 26448位读者 | 引用首先谈点题外话,关于本系列以及本博客的写作。其实本博客的写作内容,代表了笔者在这段时间附近的研究成果。也就是说,我此时在写这篇文章,其实表明我这段时间正在研究这个问题。而接下来的研究是否有结果,有怎样的结果,则是完全不知道的。所以,我在写这篇文章的时候,并不确定下一篇文章会写些什么。有些类似的话题,我会放在同一个系列去写。但不管怎样,这些文章可能并不遵循常规的教学或者学习思路,有些内容还可能与主流的思想方法有相当出入,请读者见谅,望大家继续支持!
上一篇我们谈到了切线法来求二次和三次曲线的有理点。切线法在寻找不高于三次的曲线上的有理点是很成功的,可是对于更高次的曲线有没有类似的方法呢?换句话说,有没有推广的可能性。我们从纯代数的角度来回复一下切线法生效的原因。切线法,更一般的是割线法,能够起作用,主要是因为如果有理系数的三次方程有两个有理数的根,那么第三个根肯定是有理数。如果只有一个已知的有理根,那么就可以让两个根重合为已知的那个根,从而割线变成了切线。
24
Nov
力的无穷分解与格林函数法
By 苏剑林 | 2014-11-24 | 38181位读者 | 引用我小时候一直有个疑问:
直升机上的螺旋桨能不能用来挡雨?
一般的螺旋桨是若干个“条状”物通过旋转对称而形成的,也就是说,它并非一个面,按常理来说,它是没办法用来挡雨的。但是,如果在高速旋转的情况下,甚至假设旋转速度可以任意大,那么我们任意时刻都没有办法穿过它了,这种情况下,它似乎与一个实在的面无异?
力的无穷分解
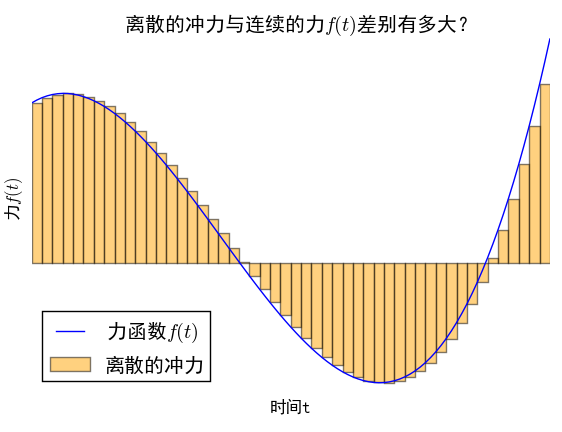
力的离散化
而让人惊喜的是,在通常的物理系统中,将力分段为无数个小区间内的恒力的做法,能够导致正确的答案,而且,这恰好是线性常微分方程的格林函数法。下面我们来分析这一做法。
在数学分析的级数理论中,有一类常见的题目,其中涉及到
$$\cos\theta+\cos 2\theta+\dots+\cos n\theta\tag{1}$$
和
$$\sin\theta+\sin 2\theta+\dots+\sin n\theta\tag{2}$$
之类的正弦或者余弦级数的求和,主要是证明该和式有界。而为了证明这一点,通常是把和式的通项求出来。当然,该级数在物理中也有重要作用,它表示$n$个相同振子的合振幅。在我们的数学分析教材中,通常是将级数乘上一项$\sin\frac{\theta}{2}$,然后利用积化和差公式完成。诚然,如果仅限在实数范围内考虑,这有可能是唯一的推导技巧的。但是这样推导的运算过程本身不简单,而且也不利于记忆,在大二的时候我就为此感到很痛苦。前几天在看费曼的书的时候,想到了一种利用复数的推导技巧。很奇怪,这个技巧是如此简单——写出来显得这篇文章都有点水了——可是我以前居然一直没留意到!看来功力尚浅,需多多修炼呀。
13
Jan
当概率遇上复变:从二项分布到泊松分布
By 苏剑林 | 2015-01-13 | 25703位读者 | 引用泊松分布,适合于描述单位时间内随机事件发生的次数的概率分布,如某一服务设施在一定时间内受到的服务请求的次数、汽车站台的候客人数等。[维基百科]泊松分布也可以作为小概率的二项分布的近似,其推导过程在一般的概率论教材都会讲到。可是一般教材上给出的证明并不是那么让人赏心悦目,如《概率论与数理统计教程》(第二版,茆诗松等编)的第98页就给出的证明过程。那么,哪个证明过程才更让人点赞呢?我认为是利用母函数的证明。
二项分布的母函数为
$$\begin{equation}(q+px)^n,\quad q=1-p\end{equation}$$
17
Mar
你所没有思考过的平行线问题
By 苏剑林 | 2015-03-17 | 37196位读者 | 引用
欧几里得
本文的主题是平行线,了解数学的朋友可能会想我会写有关非欧几何的内容。但这次不是,本文的内容纯粹是我们从小就开始学习的欧氏几何,基于“欧几里得第五公设”(又称平行公设)。但即便是从小就学习的欧氏几何中的平行线,也许里边的很多问题我们都没有思考清楚。因为平行是几何中非常基本的情形,因此,在讨论这种基本命题的时候,相当容易会出现循环论证、甚至本末倒置的情况。
我们从初中开始就被灌输“同位角相等,两直线平行”、“内错角相等,两直线平行”之类的平行线判断法则,当然,还少不了的是“过直线外一点只能作一条直线与已知直线平行”。但是,这些内容之中,有多少是基本的公理,有多少是可以证明的,该如何证明,我想很多人都理解不清楚,我自己也没有一个很好的答案。那些在初中教授平行线的老师们,估计也没多少个能够把它说清楚的。后来我发现,我居然不会证明“同位角相等,两直线平行”,“欧几里得第五公设”好像并没有告诉我们这个判定法则呀。于是,我翻看了一下初中的数学教科书,发现原来当初“同位角相等,两直线平行”这一判定法则是不加证明地让我们接受的,无怪乎我怎么也想不到关于这一法则的简单的证明...
于是,我想写这篇文章,为大家理解平行线的整个逻辑提供一点参考。

最近评论