






17
Aug
【中文分词系列】 1. 基于AC自动机的快速分词
By 苏剑林 | 2016-08-17 | 106117位读者 | 引用前言:这个暑假花了不少时间在中文分词和语言模型上面,碰了无数次壁,也得到了零星收获。打算写一个专题,分享一下心得体会。虽说是专题,但仅仅是一些笔记式的集合,并非系统的教程,请读者见谅。
中文分词
关于中文分词的介绍和重要性,我就不多说了,matrix67这里有一篇关于分词和分词算法很清晰的介绍,值得一读。在文本挖掘中,虽然已经有不少文章探索了不分词的处理方法,如本博客的《文本情感分类(三):分词 OR 不分词》,但在一般场合都会将分词作为文本挖掘的第一步,因此,一个有效的分词算法是很重要的。当然,中文分词作为第一步,已经被探索很久了,目前做的很多工作,都是总结性质的,最多是微弱的改进,并不会有很大的变化了。
目前中文分词主要有两种思路:查词典和字标注。首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。查词典的方法简单高效(得益于动态规划的思想),尤其是结合了语言模型的最大概率法,能够很好地解决歧义问题,但对于中文分词一大难度——未登录词(中文分词有两大难度:歧义和未登录词),则无法解决;为此,人们也提出了基于字标注的思路,所谓字标注,就是通过几个标记(比如4标注的是:single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾),把句子的正确分词法表示出来。这是一个序列(输入句子)到序列(标记序列)的过程,能够较好地解决未登录词的问题,但速度较慢,而且对于已经有了完备词典的场景下,字标注的分词效果可能也不如查词典方法。总之,各有优缺点(似乎是废话~),实际使用可能会结合两者,像结巴分词,用的是有向无环图的最大概率组合,而对于连续的单字,则使用字标注的HMM模型来识别。
1
Apr
《量子力学与路径积分》习题解答V0.5
By 苏剑林 | 2016-04-01 | 37648位读者 | 引用习题解答继续艰难推进中,目前是0.5版本,相比0.4版,跳过了8、9章,先做了第10、11章统计力学部分的习题。
第10章有10道习题,第11章其实没有习题。看上去很少,但其实每一道习题的难度都很大。这两章的主要内容都是在用路径积分方法算统计力学中的配分函数,这本来就是一个很艰辛的课题。加上费曼在书中那形象的描述,容易让读者能够认识到大概,但是却很难算下去。事实上,这一章的习题,我参考了相当多的资料,中文的、英文的都有,才勉强完成了。
虽说是完成,但10道题目中,我只完成了9道,其中问题10-3是有困惑的,我感觉的结果跟费曼给出的不一样,因此就算不下去了。在这里提出来,希望了解的读者赐教。
4
Jun
当概率遇上复变:随机游走与路径积分
By 苏剑林 | 2014-06-04 | 24804位读者 | 引用我们在上一篇文章中已经看到,随机游走的概率分布是正态的,而在概率论中可以了解到正态分布(几乎)是最重要的一种分布了。随机游走模型和正态分布的应用都很广,我们或许可以思考一个问题,究竟是随机游走造就了正态分布,还是正态分布造就了随机游走?换句话说,哪个更本质些?个人就自己目前所阅读到的内容来看,随机游走更本质些,随机游走正好对应着普遍存在的随机不确定性(比如每次测量的误差),它的分布正好就是正态分布,所以正态分布才应用得如此广泛——因为随机不确定性无处不在。
下面我们来考虑随机游走的另外一种描述方式,原则上来说,它更广泛,更深刻,其大名曰“路径积分”。
13
Jan
当概率遇上复变:从二项分布到泊松分布
By 苏剑林 | 2015-01-13 | 25993位读者 | 引用泊松分布,适合于描述单位时间内随机事件发生的次数的概率分布,如某一服务设施在一定时间内受到的服务请求的次数、汽车站台的候客人数等。[维基百科]泊松分布也可以作为小概率的二项分布的近似,其推导过程在一般的概率论教材都会讲到。可是一般教材上给出的证明并不是那么让人赏心悦目,如《概率论与数理统计教程》(第二版,茆诗松等编)的第98页就给出的证明过程。那么,哪个证明过程才更让人点赞呢?我认为是利用母函数的证明。
二项分布的母函数为
$$\begin{equation}(q+px)^n,\quad q=1-p\end{equation}$$
10
Jun
无监督分词和句法分析!原来BERT还可以这样用
By 苏剑林 | 2020-06-10 | 91578位读者 | 引用BERT的一般用法就是加载其预训练权重,再接一小部分新层,然后在下游任务上进行finetune,换句话说一般的用法都是有监督训练的。基于这个流程,我们可以做中文的分词、NER甚至句法分析,这些想必大家就算没做过也会有所听闻。但如果说直接从预训练的BERT(不finetune)就可以对句子进行分词,甚至析出其句法结构出来,那应该会让人感觉到意外和有趣了。
本文介绍ACL 2020的论文《Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT》,里边提供了直接利用Masked Language Model(MLM)来分析和解释BERT的思路,而利用这种思路,我们可以无监督地做到分词甚至句法分析。
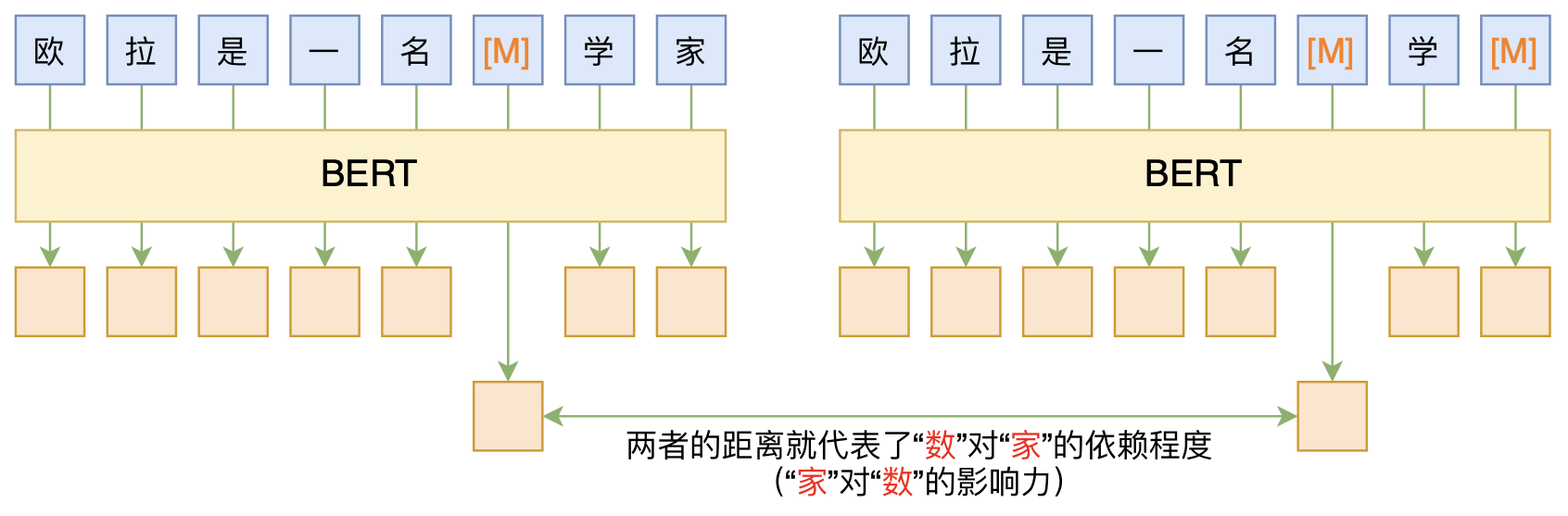
基于BERT的“token-token”相关度计算图示
14
Jul
澳洲恐龙洞穴揭示气候变化
By 苏剑林 | 2009-07-14 | 28302位读者 | 引用
12
Aug
科学家计划研制造云船对抗全球变暖(图)
By 苏剑林 | 2009-08-12 | 25338位读者 | 引用
18
Aug

最近评论