






16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 80152位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
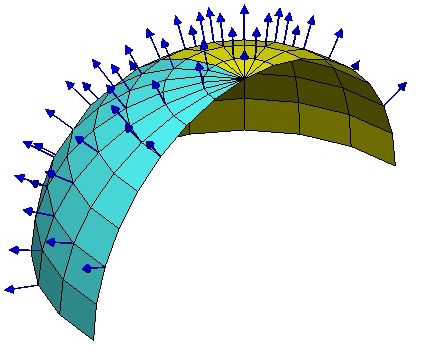
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
2
Nov
【理解黎曼几何】8. 处处皆几何 (力学几何化)
By 苏剑林 | 2016-11-02 | 57977位读者 | 引用黎曼几何在广义相对论中的体现和应用,虽然不能说家喻户晓,但想必大部分读者都有所听闻。一谈到黎曼几何在物理学中的应用,估计大家的第一反应就是广义相对论。常见的观点是,广义相对论的发现大大推动了黎曼几何的发展。诚然,这是事实,然而,大多数人不知道的事,哪怕经典的牛顿力学中,也有黎曼几何的身影。
本文要谈及的内容,就是如何将力学几何化,从而使用黎曼几何的概念来描述它们。整个过程事实上是提供了一种框架,它可以将不少其他领域的理论纳入到黎曼几何体系中。
黎曼几何的出发点就是黎曼度量,通过黎曼度量可以通过变分得到测地线。从这个意义上来看,黎曼度量提供了一个变分原理。那反过来,一个变分原理,能不能提供一个黎曼度量呢?众所周知,不少学科的基础原理都可以归结为一个极值原理,而有了极值原理就不难导出变分原理(泛函极值),如物理中就有最小作用量原理、最小势能原理,概率论中有最大熵原理,等等。如果有一个将变分原理导出黎曼度量的方法,那么就可以用几何的方式来描述它。幸运的是,对于二次型的变分原理,是可以做到的。
18
Oct
【理解黎曼几何】5. 黎曼曲率
By 苏剑林 | 2016-10-18 | 55326位读者 | 引用现在我们来关注黎曼曲率。总的来说,黎曼曲率提供了一种方案,让身处空间内部的人也能计算自身所处空间的弯曲程度。俗话说,“不识庐山真面目,只缘身在此山中”,还有“当局者迷,旁观者清”,等等,因此,能够身处空间之中而发现空间中的弯曲与否,是一件很了不起的事情,就好像我们已经超越了我们现有的空间,到了更高维的空间去“居高临下”那样。真可谓“心有多远,路就有多远,世界就有多远”。
如果站在更高维空间的角度看,就容易发现空间的弯曲。比如弯曲空间中有一条测地线,从更高维的空间看,它就是一条曲线,可以计算曲率等,但是在原来的空间看,它就是直的,测地线就是直线概念的一般化,因此不可能通过这种途径发现空间的弯曲性,必须有一些迂回的途径。可能一下子不容易想到,但是各种途径都殊途同归后,就感觉它是显然的了。
怎么更好地导出黎曼曲率来,使得它能够明显地反映出弯曲空间跟平直空间的本质区别呢?为此笔者思考了很长时间,看了不少参考书(《引力与时空》、《场论》、《引力论》等),比较了几种导出黎曼曲率的方式,简要叙述如下。
19
Oct
【理解黎曼几何】6. 曲率的计数与计算(Python)
By 苏剑林 | 2016-10-19 | 53128位读者 | 引用曲率的独立分量
黎曼曲率张量是一个非常重要的张量,当且仅当它全部分量为0时,空间才是平直的。它也出现在爱因斯坦的场方程中。总而言之,只要涉及到黎曼几何,黎曼曲率张量就必然是核心内容。
已经看到,黎曼曲率张量有4个指标,这也意味着它有$n^4$个分量,$n$是空间的维数。那么在2、3、4维空间中,它就有16、81、256个分量了,可见,要计算它,是一件相当痛苦的事情。幸好,这个张量有很多的对称性质,使得独立分量的数目大大减少,我们来分析这一点。
首先我们来导出黎曼曲率张量的一些对称性质,这部分内容是跟经典教科书是一致的。定义
$$R_{\mu\alpha\beta\gamma}=g_{\mu\nu}R^{\nu}_{\alpha\beta\gamma} \tag{50} $$
定义这个量的原因,要谈及逆变张量和协变张量的区别,我们这里主要关心几何观,因此略过对张量的详细分析。这个量被称为完全协变的黎曼曲率张量,有时候也直接叫做黎曼曲率张量,只要不至于混淆,一般不做区分。通过略微冗长的代数运算(在一般的微分几何、黎曼几何或者广义相对论教材中都有),可以得到
$$\begin{aligned}&R_{\mu\alpha\beta\gamma}=-R_{\mu\alpha\gamma\beta}\\
&R_{\mu\alpha\beta\gamma}=-R_{\alpha\mu\beta\gamma}\\
&R_{\mu\alpha\beta\gamma}=R_{\beta\gamma\mu\alpha}\\
&R_{\mu\alpha\beta\gamma}+R_{\mu\beta\gamma\alpha}+R_{\mu\gamma\alpha\beta}=0
\end{aligned} \tag{51} $$
21
Oct
【理解黎曼几何】7. 高斯-博内公式
By 苏剑林 | 2016-10-21 | 38317位读者 | 引用令人兴奋的是,我们导出黎曼曲率的途径,还能够让我们一瞥高斯-博内公式( Gauss–Bonnet formula)的风采,真正体验一番研究内蕴几何的味道。
高斯-博内公式是大范围微分几何学的一个经典的公式,它建立了空间的局部性质和整体性质之间的联系。而我们从一条几何的路径出发,结合一些矩阵变换和数学分析的内容,逐步导出了测地线、协变导数、曲率张量,现在可以还可以得到经典的高斯-博内公式,可见我们在这条路上已经走得足够远了。虽然过程不尽善尽美,然而并没有脱离这个系列的核心:几何直观。本文的目的,正是分享黎曼几何的一种直观思路,既然是思路,以思想交流为主,不以严格证明为目的。因此,对于大家来说,这个系列权当黎曼几何的补充材料吧。
形式改写
首先,我们可以将式$(48)$重写为更有几何意义的形式。从
4
Nov
【外微分浅谈】2. 反对称的威力
By 苏剑林 | 2016-11-04 | 44944位读者 | 引用内积与外积
向量(这里暂时指的是二维或者三维空间中的向量)的强大之处,在于它定义了内积和外积(更多时候称为叉积、向量积等),它们都是两个向量之间的运算,其中,内积被定义为是对称的,而外积则被定义为反对称的,它们都满足分配律。
沿着书本的传统,我们用$\langle,\rangle$表示内积,用$\land$表示外积,对于外积,更多的时候是用$\times$,但为了不至于出现太多的符号,我们统一使用$\land$。我们将向量用基的形式写出来,比如
$$\boldsymbol{A}=\boldsymbol{e}_{\mu}A^{\mu} \tag{1} $$
其中$\boldsymbol{e}_{\mu}$代表着一组基,而$A^{\mu}$则是向量的分量。我们来计算两个向量$\boldsymbol{A},\boldsymbol{B}$的内积和外积,即
$$\begin{aligned}&\langle \boldsymbol{A}, \boldsymbol{B}\rangle=\langle \boldsymbol{e}_{\mu}A^{\mu}, \boldsymbol{e}_{\nu}B^{\nu}\rangle=\langle\boldsymbol{e}_{\mu},\boldsymbol{e}_{\nu}\rangle A^{\mu}A^{\nu}\\
&\boldsymbol{A}\land \boldsymbol{B}=(\boldsymbol{e}_{\mu}A^{\mu})\land (\boldsymbol{e}_{\nu}B^{\nu})=\boldsymbol{e}_{\mu}\land\boldsymbol{e}_{\nu} A^{\mu}B^{\nu}
\end{aligned} \tag{2} $$
7
Nov
【外微分浅谈】6. 微分几何
By 苏剑林 | 2016-11-07 | 44917位读者 | 引用终于开始谈到重点了,就是这部分内容促使我学习外微分的。用外微分可以方便地推导微分几何的一些内容,有时候还能方便计算。其主要根源在于:外微分本身在形式上是微分的推广,因此微分几何的东西能够使用外微分来描述并不出奇;然后,最重要的原因是,外微分把$dx^{\mu}$看成一组基,因此相当于在几何中引入了两组基,一组是本身的向量基(用张量的语言,就是逆变向量的基),这组基可以做对称的内积,另外一组基就是$dx^{\mu}$,这组基可以做反对称的外积。因此,当外微分引入几何时,微分几何就拥有了微分、积分、对称积、反对称积等各种“理想装备”,这就是外微分能够加速微分几何推导的主要原因。
标架的运动
前面已经得到
$$\begin{aligned}&\omega^{\mu}=h_{\alpha}^{\mu}dx^{\alpha}\\
&d\boldsymbol{r}=\hat{\boldsymbol{e}}_{\mu} \omega^{\mu}\\
&ds^2 = \eta_{\mu\nu} \omega^{\mu}\omega^{\nu}\\
&\langle \hat{\boldsymbol{e}}_{\mu}, \hat{\boldsymbol{e}}_{\nu}\rangle = \eta_{\mu\nu}\end{aligned} \tag{45} $$
16
Nov
为什么勒贝格积分比黎曼积分强?
By 苏剑林 | 2016-11-16 | 114731位读者 | 引用学过实变函数的朋友,总会知道有个叫勒贝格积分的东西,号称是黎曼积分的改进版。虽然“实变函数学十遍,泛函分析心泛寒”,在学习实变函数的时候,我们通常都是云里雾里的,不过到最后,在老师的“灌溉”之下,也就耳濡目染了知道了一些结论,比如“黎曼可积的函数(在有限区间),也是勒贝格可积的”,说白了,就是“勒贝格积分比黎曼积分强”。那么,问题来了,究竟强在哪儿?为什么会强?

黎曼

勒贝格
这个问题,笔者在学习实变函数的时候并没有弄懂,后来也一直搁着,直到最近认真看了《重温微积分》之后,才有了些感觉。顺便说,齐民友老师的《重温微积分》真的很赞,值得一看。

最近评论