






11
Nov
【外微分浅谈】7. 有力的计算
By 苏剑林 | 2016-11-11 | 28825位读者 | 引用这里我们将展示上面一节的方法对于计算黎曼曲率张量的计算是多少的有力!我们再次列出我们得到的所有公式。首先是概念式的
$$\begin{aligned}&\omega^{\mu}=h_{\alpha}^{\mu}dx^{\alpha}\\
&d\boldsymbol{r}=\hat{\boldsymbol{e}}_{\mu} \omega^{\mu}\\
&ds^2 = \eta_{\mu\nu} \omega^{\mu}\omega^{\nu}\\
&\langle \hat{\boldsymbol{e}}_{\mu}, \hat{\boldsymbol{e}}_{\nu}\rangle = \eta_{\mu\nu}\end{aligned} \tag{65} $$
然后是
$$\begin{aligned}&d\eta_{\mu\nu}=\omega_{\nu\mu}+\omega_{\mu\nu}=\eta_{\nu\alpha}\omega_{\mu}^{\alpha}+\eta_{\mu \alpha}\omega_{\nu}^{\alpha}\\
&d\omega^{\mu}+\omega_{\nu}^{\mu}\land \omega^{\nu}=0\end{aligned} \tag{66} $$
这两个可以帮助我们确定$\omega_{\nu}^{\mu}$;接着就是
$$\mathscr{R}_{\nu}^{\mu} = d\omega_{\nu}^{\mu}+\omega_{\alpha}^{\mu} \land \omega_{\nu}^{\alpha} \tag{67} $$
最后你要正交标架下的$\hat{R}^{\mu}_{\nu\beta\gamma}$,就要写出:
$$\mathscr{R}_{\nu}^{\mu}=\sum_{\beta < \gamma} \hat{R}^{\mu}_{\nu\beta\gamma}\omega^{\beta}\land \omega^{\gamma} \tag{68} $$
如果你要原始标架下的$R^{\mu}_{\nu\beta\gamma}$,就要写出
$$(h^{-1})_{\mu'}^{\mu}\mathscr{R}^{\mu'}_{\nu'}h_{\nu}^{\nu'} = \sum_{\beta < \gamma} R^{\mu}_{\nu\beta\gamma}dx^{\beta}\land dx^{\gamma} \tag{69} $$
然后依次读出$R^{\mu}_{\nu\beta\gamma}$,就像制表一样。
11
Jan
狄拉克函数:级数逼近
By 苏剑林 | 2017-01-11 | 48143位读者 | 引用魏尔斯特拉斯定理
将狄拉克函数理解为函数的极限,可以衍生出很丰富的内容,而且这些内容离严格的证明并不遥远。比如,定义
$$\delta_n(x)=\left\{\begin{aligned}&\frac{(1-x^2)^n}{I_n},x\in[-1,1]\\
&0,\text{其它情形}\end{aligned}\right.$$
其中$I_n = \int_{-1}^1 (1-x^2)^n dx$,于是不难证明
$$\delta(x)=\lim_{n\to\infty}\delta_n(x)$$
这样,对于$[a,b]$上的连续函数$f(x)$,我们就得到
$$f(x)=\int_{-1}^1 f(y)\delta(x-y)dy = \lim_{n\to\infty}\int_{-1}^1 f(y)\delta_n(x-y) dy$$
这里$-1 < a < b < 1$,并且我们已经“不严谨”地交换了积分号和极限号,但这不是特别重要。重要的是它的结果:可以看到
$$P_n(x)=\int_{-1}^1 f(y)\delta_n(x-y) dy$$
是$x$的一个$2n$次多项式,因此上式表明$f(x)$是一个$2n$次的多项式的极限!这就引出了著名的“魏尔斯特拉斯定理”:
闭区间上的连续函数都可以用多项式一致地逼近。
15
Jan
SVD分解(一):自编码器与人工智能
By 苏剑林 | 2017-01-15 | 53127位读者 | 引用咋看上去,SVD分解是比较传统的数据挖掘手段,自编码器是深度学习中一个比较“先进”的概念,应该没啥交集才对。而本文则要说,如果不考虑激活函数,那么两者将是等价的。进一步的思考就可以发现,不管是SVD还是自编码器,我们降维,并不是纯粹地为了减少储存量或者减少计算量,而是“智能”的初步体现。
等价性
假设有一个$m$行$n$列的庞大矩阵$M_{m\times n}$,这可能使得计算甚至存储上都成问题,于是考虑一个分解,希望找到矩阵$A_{m\times k}$和$B_{k\times n}$,使得
$$M_{m\times n}=A_{m\times k}\times B_{k\times n}$$
这里的乘法是矩阵乘法。如图
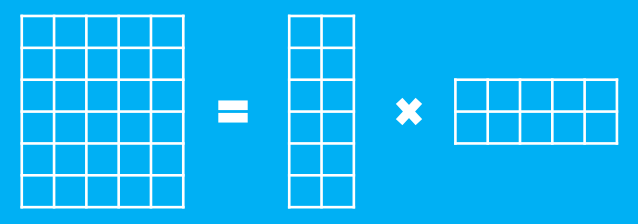
SVD
26
Jan
SVD分解(二):为什么SVD意味着聚类?
By 苏剑林 | 2017-01-26 | 81588位读者 | 引用提前祝各位读者新年快乐,2017行好运~
这篇文章主要想回答两个“为什么”的问题:1、为啥我就对SVD感兴趣了?;2、为啥我说SVD是一个聚类过程?回答的内容纯粹个人思辨结果,暂无参考文献。
为什么要研究SVD?
从2015年接触深度学习到现在,已经研究了快两年的深度学习了,现在深度学习、数据科学等概念也遍地开花。为什么在深度学习火起来的时候,我反而要回去研究“古老”的SVD分解呢?我觉得,SVD作为一个矩阵分解算法,它的价值不仅仅体现在它广泛的应用,它背后还有更加深刻的内涵,即它的可解释性。在深度学习流行的今天,不少人还是觉得深度学习(神经网络)就是一个有效的“黑箱”模型。但是,仅用“黑箱”二字来解释深度学习的有效性显然不能让人满意。前面已经说过,SVD分解本质上与不带激活函数的三层自编码机等价,理解SVD分解,能够为神经网络模型寻求一个合理的概率解释。
19
Feb
Python的多进程编程技巧
By 苏剑林 | 2017-02-19 | 39438位读者 | 引用过程
在Python中,如果要多进程运算,一般是通过multiprocessing来实现的,常用的是multiprocessing中的进程池,比如:
from multiprocessing import Pool
import time
def f(x):
time.sleep(1)
print x+1
return x+1
a = range(10)
pool = Pool(4)
b = pool.map(f, a)
pool.close()
pool.join()
print b
这样写简明清晰,确实方便,有趣的是,只需要将multiprocessing换成multiprocessing.dummy,就可以将程序从多进程改为多线程了。
30
Mar
文本情感分类(四):更好的损失函数
By 苏剑林 | 2017-03-30 | 128537位读者 | 引用文本情感分类其实就是一个二分类问题,事实上,对于分类模型,都会存在这样一个毛病:优化目标跟考核指标不一致。通常来说,对于分类(包括多分类),我们都会采用交叉熵作为损失函数,它的来源就是最大似然估计(参考《梯度下降和EM算法:系出同源,一脉相承》)。但是,我们最后的评估目标,并非要看交叉熵有多小,而是看模型的准确率。一般来说,交叉熵很小,准确率也会很高,但这个关系并非必然的。
要平均,不一定要拔尖
一个更通俗的例子是:一个数学老师,在努力提高同学们的平均分,但期末考核的指标却是及格率(60分及格)。假如平均分是100分(也就意味着所有同学都考到了100分),那么自然及格率是100%,这是最理想的。但现实不一定这么美好,平均分越高,只要平均分还没有达到100,那么及格率却不一定越高,比如两个人分别考40和90,那么平均分就是65,及格率只有50%;如果两个人的成绩都是60,平均分就是60,及格率却有100%。这也就是说,平均分可以作为一个目标,但这个目标并不直接跟考核目标挂钩。
那么,为了提升最后的考核目标,这个老师应该怎么做呢?很显然,首先看看所有学生中,哪些同学已经及格了,及格的同学先不管他们,而针对不及格的同学进行补课加强,这样一来,原则上来说有很多不及格的同学都能考上60分了,也有可能一些本来及格的同学考不够60分了,但这个过程可以迭代,最终使得大家都在60分以上,当然,最终的平均分不一定很高,但没办法,谁叫考核目标是及格率呢?
7
Apr
【不可思议的Word2Vec】 3.提取关键词
By 苏剑林 | 2017-04-07 | 209311位读者 | 引用本文主要是给出了关键词的一种新的定义,并且基于Word2Vec给出了一个实现方案。这种关键词的定义是自然的、合理的,Word2Vec只是一个简化版的实现方案,可以基于同样的定义,换用其他的模型来实现。
说到提取关键词,一般会想到TF-IDF和TextRank,大家是否想过,Word2Vec还可以用来提取关键词?而且,用Word2Vec提取关键词,已经初步含有了语义上的理解,而不仅仅是简单的统计了,而且还是无监督的!
什么是关键词?
诚然,TF-IDF和TextRank是两种提取关键词的很经典的算法,它们都有一定的合理性,但问题是,如果从来没看过这两个算法的读者,会感觉简直是异想天开的结果,估计很难能够从零把它们构造出来。也就是说,这两种算法虽然看上去简单,但并不容易想到。试想一下,没有学过信息相关理论的同学,估计怎么也难以理解为什么IDF要取一个对数?为什么不是其他函数?又有多少读者会破天荒地想到,用PageRank的思路,去判断一个词的重要性?
说到底,问题就在于:提取关键词和文本摘要,看上去都是一个很自然的任务,有谁真正思考过,关键词的定义是什么?这里不是要你去查汉语词典,获得一大堆文字的定义,而是问你数学上的定义。关键词在数学上的合理定义应该是什么?或者说,我们获取关键词的目的是什么?
24
Apr
【语料】2500万中文三元组!
By 苏剑林 | 2017-04-24 | 93788位读者 | 引用闲聊
这两年,知识图谱、问答系统、聊天机器人等领域是越来越火了。知识图谱是一个很泛化的概念,在我看来,涉及到知识库的构建、检索、利用等机器学习相关的内容,都算知识图谱。当然,这也不是个什么定义,只是个人的直观感觉。
做知识图谱的读者都知道,三元组是结构化知识的一种方法,是做知识型问答系统的重要组成部分。对于英文领域,已经有一些较大的开源的三元组语料库,而很显然,中文目前还没有这样的语料库共享(哪怕有人爬取到了,也珍藏起来了)。笔者前段时间写了个百度百科的爬虫,爬了一段时间,抓了几百万个百度百科的词条。其中不少词条含有一些结构化的信息,直接抽取出来,就是有效的“三元组”了,可以用来做知识图谱。本文分享的三元组语料正是由此而来,共有2500万个三元组。

百度百科的三元组

最近评论