






8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 114942位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在$\mathbb{R}^n$上的连续型概率分布,其概率密度函数为
\begin{equation}p(\boldsymbol{x})=\frac{1}{\sqrt{(2\pi)^n \det(\boldsymbol{\Sigma})}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\}\end{equation}
5
Aug
经典电视剧:《仙剑奇侠传3》专辑
By 苏剑林 | 2009-08-05 | 25195位读者 | 引用
27
Jul
今天升级了Blog(欢迎大家来“顶”!)
By 苏剑林 | 2009-07-27 | 67623位读者 | 引用
18
Aug
世界各国能否联手应对气候变化?
By 苏剑林 | 2009-08-18 | 25826位读者 | 引用
28
Aug
正十七边形的尺规作图
By 苏剑林 | 2009-08-28 | 43310位读者 | 引用为何正17边形能够用尺规作出来?要如何作?先别急,请看下面的解释:
一个正质数多边形可以用标尺作图的充分和必要条件是,该多边形的边数必定是一个费马质数。换句话说,只有正三边形、正五边形、正十七边形、正257边形和正63357边形可以用尺规作出来,其它的正质数多边形就不可以了。(除非我们再发现另一个费马质数。)
正17边形的尺规作法是高斯在1796年得出的,他也因此决心要成为数学家。关于费马质数,是指形如$2^{2^n}+1$的质数,一开始费马认为对于所有的n,这种形式的数都是质数。可是这似乎是上天的玩笑,目前只发现了当n=0,1,2,3,4的时候$2^{2^n}+1$是质数,其余都是合数。
1
Oct
【NASA每日一图】春分时刻的土星
By 苏剑林 | 2009-10-01 | 20425位读者 | 引用
8
Oct
【NASA每日一图】撞击目标:凯布斯月球坑
By 苏剑林 | 2009-10-08 | 18629位读者 | 引用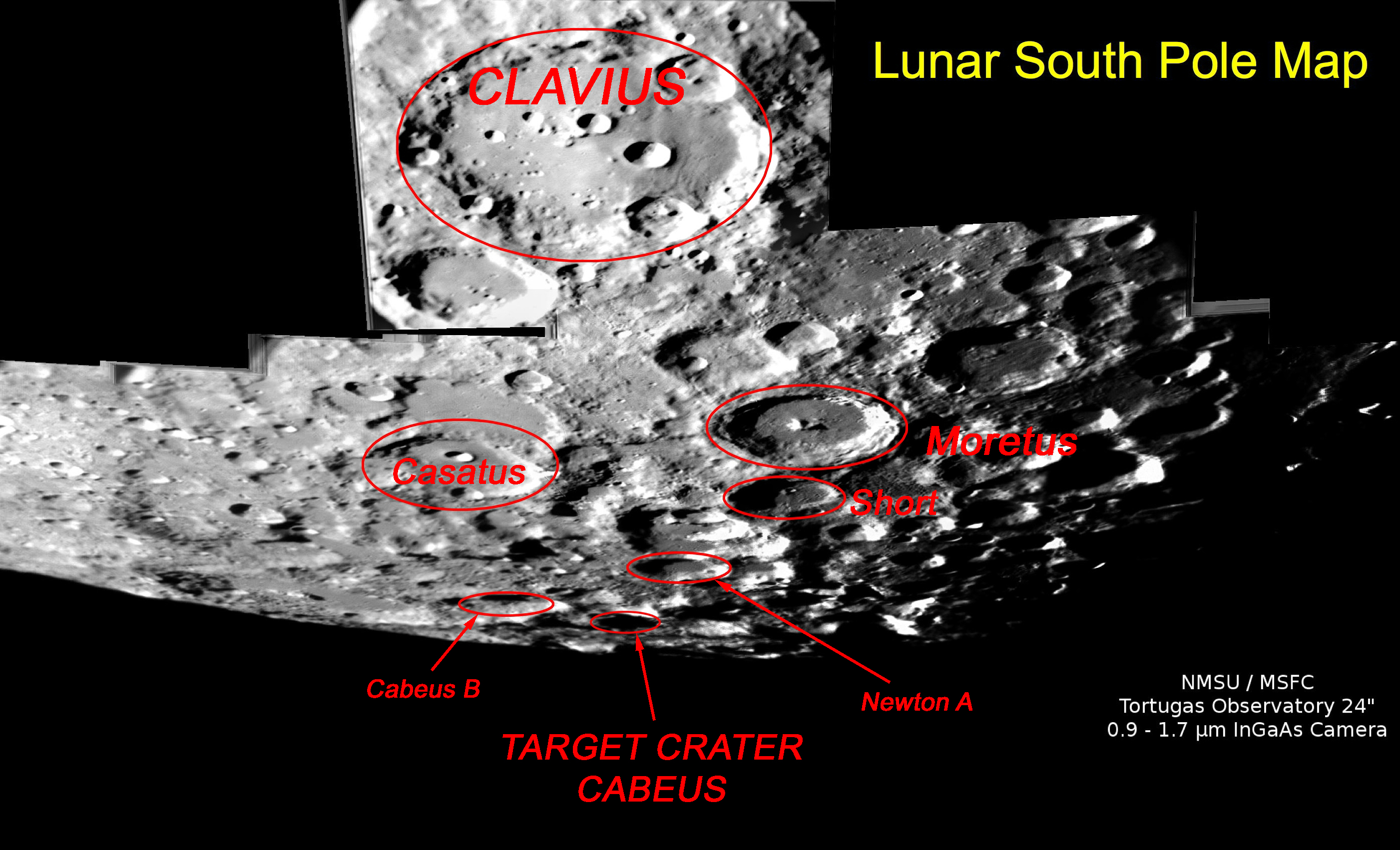
13
Oct


最近评论