






25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 297852位读者 |高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
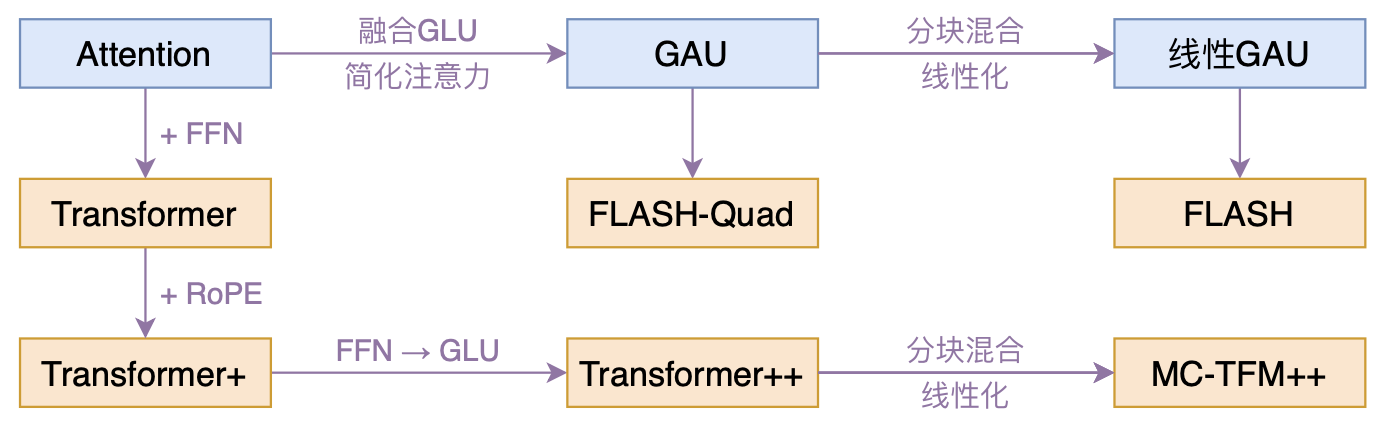
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
何喜之有 #
什么样的结果值得我们用“惊喜”来形容?有没有言过其实?我们不妨先来看看论文做到了什么:
1、提出了一种新的Transformer变体,它依然具有二次的复杂度,但是相比标准的Transformer,它有着更快的速度、更低的显存占用以及更好的效果;
2、提出一种新的线性化Transformer方案,它不但提升了原有线性Attention的效果,还保持了做Decoder的可能性,并且做Decoder时还能保持高效的训练并行性。
说实话,笔者觉得做到以上任意一点都是非常难得的,而这篇论文一下子做到了两点,所以我愿意用“惊喜满满”来形容它。更重要的是,论文的改进总的来说还是比较自然和优雅的,不像很多类似工作一样显得很生硬。此外,笔者自己也做了简单的复现实验,结果显示论文的可复现性应该是蛮好的,所以真的有种“Transformer危矣”的感觉了。
门控注意 #
闲话少说,进入主题。我们知道标准的Transformer其实是Attention层和FFN层交替构建的,而这篇论文的核心是提出了一个融合了两者的新设计GAU(Gated Attention Unit,门控注意力单元),它是新模型更快、更省、更好的关键,此外它使得整个模型只有一种层,也显得更为优雅。
威力初显 #
怎么做到Attention和FFN的融合呢?首先,标准的FFN是两层MLP模型:
\begin{equation}\boldsymbol{O}=\phi(\boldsymbol{X}\boldsymbol{W}_u)\boldsymbol{W}_o\end{equation}
这里$\boldsymbol{X}\in\mathbb{R}^{n\times d},\boldsymbol{W}_u\in\mathbb{R}^{d\times e},\boldsymbol{W}_o\in\mathbb{R}^{e\times d}$而$\phi$是激活函数。后来,《GLU Variants Improve Transformer》发现使用了GLU(Gated Linear Unit,门控线性单元)的FFN效果更好,并为后来的mT5所用,其形式为:
\begin{equation}\boldsymbol{O}=(\boldsymbol{U}\odot\boldsymbol{V})\boldsymbol{W}_o,\quad \boldsymbol{U}=\phi_u(\boldsymbol{X}\boldsymbol{W}_u),\quad\boldsymbol{V}=\phi_v(\boldsymbol{X}\boldsymbol{W}_v)\end{equation}
这里$\boldsymbol{W}_u,\boldsymbol{W}_v\in\mathbb{R}^{d\times e}$而$\odot$是逐位对应相乘(Hadamard积)。GLU更有效并不是一件让人意外的事情,早在2017年Facebook的《Convolutional Sequence to Sequence Learning》中GLU就起到了关键作用,此外笔者之前研究的DGCNN也肯定了GLU的有效性。
一般情况下的GLU是$\boldsymbol{U}$不加激活函数而$\boldsymbol{V}$加Sigmoid,但这篇论文$\boldsymbol{U},\boldsymbol{V}$都加了激活函数Swish(也叫SiLU,Sigmoid Linear Unit),这可以在附录中的源码找到,此处跟主流GLU用法略有不同,特别指出一下。
强强联合 #
既然GLU式的FFN更有效,那么我们就以它为基础进行修改。注意到FFN不能取代Attention,是因为它的各个token之间没有进行交互,也就是矩阵$\boldsymbol{U},\boldsymbol{V}$的每一行都是独立运算的。为了补充这点不足,一个自然的想法就是把token之间的联系补充到$\boldsymbol{U},\boldsymbol{V}$上去,而为了体现出跟Attetion的结合,那么一个比较自然的设计就是
\begin{equation}\boldsymbol{O}=(\boldsymbol{U}\odot\boldsymbol{A}\boldsymbol{V})\boldsymbol{W}_o\label{eq:mix}\end{equation}
其中$\boldsymbol{A}\in\mathbb{R}^{n\times n}$是Attention矩阵,它负责融合token之间的信息。这样出来的$\boldsymbol{O}$就包含了token之间的交互,原则上它可以取代Attention。至于$\boldsymbol{A}$怎么算,我们等会再说。
在式$\eqref{eq:mix}$中,如果$\boldsymbol{A}$等于单位阵$\boldsymbol{I}$,那么它就是GLU式的FFN;而如果$\boldsymbol{U}$是全1矩阵,那么它就是普通的注意力机制。所以说,$\eqref{eq:mix}$是Attention和FFN的一个简单而自然的融合,我们期望它能同时替换掉Attention和FFN,甚至有更好的表现。
弱注意力 #
刚才说了,GLU本身就很强,不然Facebook也无法凭借CNN+GLU做到了当时Seq2Seq的SOTA,而既然GLU那么强,那么一个猜测是它会弱化对Attention的依赖。也就是说,虽然在式$\eqref{eq:mix}$中$\boldsymbol{A}$是不可或缺的,但或许我们可以简化它的形式。事实上确实如此,原论文使用了如下的简化版Attention矩阵:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right),\quad \boldsymbol{Z}=\phi_z(\boldsymbol{X}\boldsymbol{W}_z)\label{eq:relu-att}\end{equation}
这里$\boldsymbol{W}_z\in\mathbb{R}^{d\times s}$,$s$即注意力的head_size,文中取了$s=128$,而$\mathcal{Q},\mathcal{K}$是简单的仿射变换(像Layer Norm中的乘$\gamma$加$\beta$),$\text{relu}^2$则是$\text{relu}$后再平方。
跟标准的Scaled-Dot Self Attention类似,这里的注意力矩阵还是$\boldsymbol{Q},\boldsymbol{K}$的内积并除以维度的平方根而来,复杂度还是$\mathcal{O}(n^2)$的,不同的是这里简化了$\boldsymbol{Q},\boldsymbol{K}$的来源变换,并且激活函数换用了$\text{relu}^2$。大家可能对这个激活函数比较陌生,事实上这是作者团队在他们之前的论文《Primer: Searching for Efficient Transformers for Language Modeling》用NAS的方式搜出来的。最后的$1/n$是简单的归一化因子,用以消除长度的影响。这个设计的成功也表明,注意力机制中的softmax不是必须的,可以换成常规的激活函数加简单的归一化。
注意,按照论文附录的参考代码,原论文化简后的缩放因子实际上是$\frac{1}{n^2}$而不是上式的$\frac{1}{ns}$,笔者认为$\frac{1}{ns}$会更加合理一些,不然当$n$足够大时,每一项注意力都过小了。况且对照标准注意力所用的softmax,其分母也只是$\mathcal{O}(n)$的量级而已,设成$n^2$实在感觉不科学。笔者也简单做过对比实现,发现在512长度下$\frac{1}{ns}$版本还轻微好点,所以这里就按笔者的直觉来介绍了。
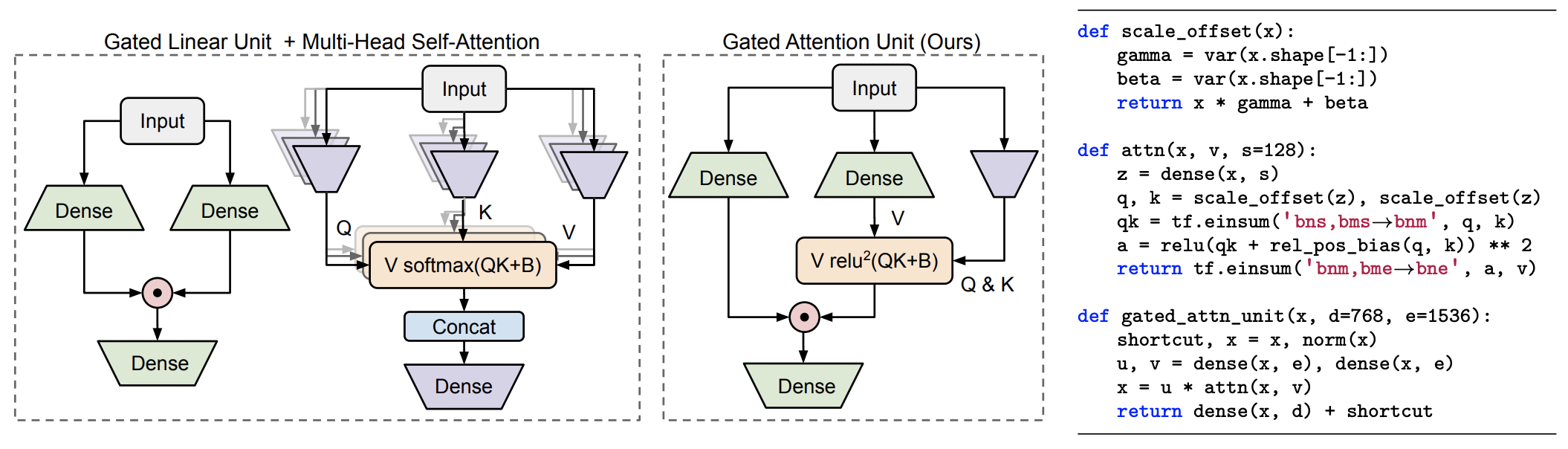
GAU示意图及其伪代码
以一当十 #
接下来请各位看官不要眨眼了,真正的“重磅”要登场了!可能GLU真的太强了,它对Attention的依赖真的非常非常弱,以至于作者们发现:只用一个头就够了!
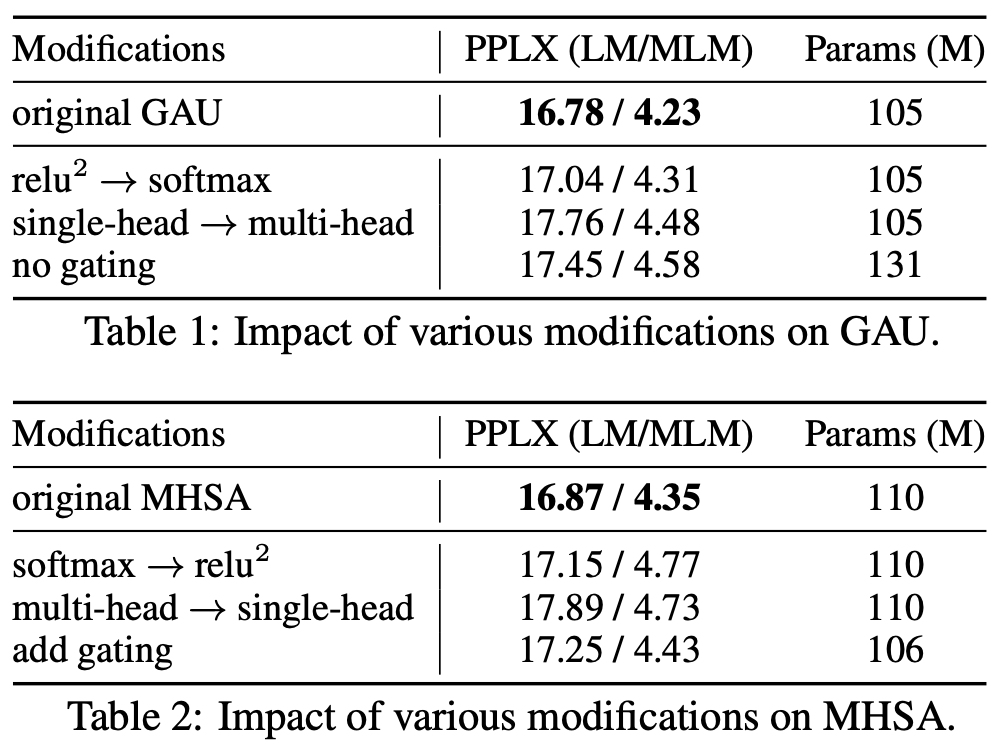
GAU与多头注意力的一些消融分析
我们知道标准的Transformer用的是多头注意力机制,在运算过程中需要产生$bhn^2$大小的矩阵,$b$是batch_size而$h$是头数,试想一下,当$n=1000$、$n=2000$甚至更大时,$n^2$已经够“惨”的了,还要活生生地乘个$h$,不管对时间还是空间复杂度无疑都是“雪上加霜”。而如今,只要一个头的GAU,就可以达到相同甚至更好的效果,不仅提高了计算速度,还降低了显存占用量,几乎算得上是“免费的午餐”了。
当GAU只有一个头时,$\boldsymbol{W}_z$的参数量就很少了,主要参数量在$\boldsymbol{W}_u,\boldsymbol{W}_v,\boldsymbol{W}_o$上,所以GAU的参数量大约为$3de$;而在标准的Transformer中,Attention的参数量为$4d^2$,FFN的参数量为$8d^2$(标准FFN中一般是$e=4d$),所以总参数量为$12d^2$。因此,从参数量看,当$e=2d$时,两层GAU大致上就等于原来的Attention+FFN。
所以,在GAU的实验中,作者都固定$e=2d$,那么“$n$层Attention+$n$层FFN”的标准Transformer模型,对应的就是“$2n$层GAU”的新模型,我们记为FLASH-Quad,其中Quad是“Quadratic”的简写,表明复杂度依然是二次的,至于FLASH的含义,后面再谈。
高效线性 #
其实FLASH-Quad已经是标准Transformer的一个非常优秀的替代品了,但作者们还不满意其二次复杂度,继而提出了具有线性复杂度的FLASH(Fast Linear Attention with a Single Head)。为此,作者提出了一种“分块混合注意力(Mixed Chunk Attention)”的方案,它不单可以用于前述GAU中,也可以用于标准的Attention中,是一种较为通用的线性化技巧。
现有方法 #
主流的高效Transformer工作对Attention的改进思路大体上可以两大类,分别是“稀疏化”和“线性化”。
本文开头提到的《为节约而生:从标准Attention到稀疏Attention》,就是“稀疏化”的工作之一,后面诸如Reformer等也算是此列,还有一些跟Pooling结合的如Linformer也可以理解为广义的“稀疏化”。这类工作的特点是引入一定的归纳先验,强制大部分注意力为0,从而理论上可以少减少计算量。但这种方案的缺点是往往需要专门的编程优化才能实现加速,或者是难以用来做Decoder(Pooling类工作),此外效果好坏比较依赖于其引入的归纳先验,显得不够自然。
至于“线性化”,我们在《线性Attention的探索:Attention必须有个Softmax吗?》有过介绍,研究的人相对多一些,后面的Performer、Nyströmformer以及最近的cosFormer、Flowformer都可以归入此类。简单来看,这类工作是将标准Attention的$\phi(\boldsymbol{Q}\boldsymbol{K}^{\top})\boldsymbol{V}$改为$(\phi_q(\boldsymbol{Q})\phi_k(\boldsymbol{K})^{\top})\boldsymbol{V}=\phi_q(\boldsymbol{Q})(\phi_k(\boldsymbol{K})^{\top}\boldsymbol{V})$从而实现了线性复杂度。这类方法的好处是易于实现,但有两个主要问题,一是低秩性会导致效果明显变差(参考《Transformer升级之路:3、从Performer到线性Attention》);另外是用来做Decoder(Causal)时会牺牲训练并行性,因为它需要转化为RNN来计算,又或者不牺牲并行性,但需要$bhns^2$的空间复杂度,相比于标准Attention的$bhn^2$,起码要$n \gg s^2$才有优势,而哪怕$s=64$,都要$n \gg 4096$了,多数情况下不现实。
分块混合 #
FLASH采取了“局部-全局”分块混合的方式,结合了“稀疏化”和“线性化”的优点。首先,对于长度为$n$的输入序列,我们将它不重叠地划分为$n/c$个长度为$c$的块(不失一般性,假设$c$能被$n$整除,论文取$c=256$),设$\boldsymbol{U}_g,\boldsymbol{V}_g\in\mathbb{R}^{c\times e},\boldsymbol{Z}_g\in\mathbb{R}^{c\times s}$为第$g$块,其中$\boldsymbol{U},\boldsymbol{V},\boldsymbol{Z}$的定义同前。跟式$\eqref{eq:relu-att}$一样,我们将$\boldsymbol{Z}_g$通过4个简单的仿射变换分别得到$\boldsymbol{Q}_g^{\text{quad}},\boldsymbol{K}_g^{\text{quad}},\boldsymbol{Q}_g^{\text{lin}},\boldsymbol{K}_g^{\text{lin}}$。
其中$\boldsymbol{Q}_g^{\text{quad}},\boldsymbol{K}_g^{\text{quad}}$我们用来算块内的自注意力:
\begin{equation}\hat{\boldsymbol{V}}_g^{\text{quad}}=\frac{1}{cs}\text{relu}^2\left(\boldsymbol{Q}_g^{\text{quad}}{\boldsymbol{K}_g^{\text{quad}}}^{\top}\right)\boldsymbol{V}_g\end{equation}
这代表的是每个块的token内部自行交互,本质上也算是“稀疏化”的一种,其复杂度大致是$\mathcal{O}(n/c\times c^2)=\mathcal{O}(nc)$,正比于$n$。实现时相当于头数为$n/c$、序列长度为$c$的多头注意力,可以充分地并行,而如果想要做Decoder,那么mask掉注意力矩阵的上三角部分即可。
剩下的$\boldsymbol{Q}_g^{\text{lin}},\boldsymbol{K}_g^{\text{lin}}$则用来做全局的Attention,我们直接用前述线性Attention的方式来做:
\begin{equation}\hat{\boldsymbol{V}}_g^{\text{lin}}=\frac{1}{n}\boldsymbol{Q}_g^{\text{lin}}\sum_{h=1}^{n/c} {\boldsymbol{K}_h^{\text{lin}}}^{\top}\boldsymbol{V}_h\end{equation}
注意,这个操作跟直接用完整矩阵$\boldsymbol{Q}^{\text{lin}},\boldsymbol{K}^{\text{lin}}\in\mathbb{R}^{n\times s}$与$\boldsymbol{V}$做线性Attention是完全等价的,写成这样只是更好地体现跟分块的联系。如果是做Decoder,那么要防止泄漏未来信息,所以要改为cumsum形式:
\begin{equation}\hat{\boldsymbol{V}}_g^{\text{lin}}=\frac{1}{(g-1)n/c}\boldsymbol{Q}_g^{\text{lin}}\sum_{h=1}^{g-1} {\boldsymbol{K}_h^{\text{lin}}}^{\top}\boldsymbol{V}_h\end{equation}
这种情况下,为了保持并行性,我们只需要$b(n/c)se$的空间复杂度,而如果不分块直接用线性Attention,那么是$bns^2$(要是原始的用法还要加上多头,那就是$bhns^2$),在当前参数设置下有$e/c\ll s$,所以是更省显存了。
最后,将两种Attention结果结合起来,整合到GAU中,得到线性版本的GAU
\begin{equation}\boldsymbol{O}_g=\left[\boldsymbol{U}_g\odot\left(\hat{\boldsymbol{V}}_g^{\text{quad}} + \hat{\boldsymbol{V}}_g^{\text{lin}}\right)\right]\boldsymbol{W}_o\end{equation}
基于线性版本GAU搭建的Transformer模型,便是作者笔下的FLASH模型了。
一些讨论 #
笔者认为,之所以这样分块做“局部-全局”的混合注意力,除了是想降低计算成本外,还因为这样做能得到更贴合实际情况的注意力分布。按照我们对NLP的经验理解,自然语言中的关联主要还是集中在局部的,而全局的、极度长距离的关联虽然存在,但不会是主导地位,所以这种混合式的注意力设计更有利于模型凸出局部关联但不舍弃长程关联。原论文还做了消融实验,显示相对来说局部注意力比全局注意力更重要,而混合式的效果最好。
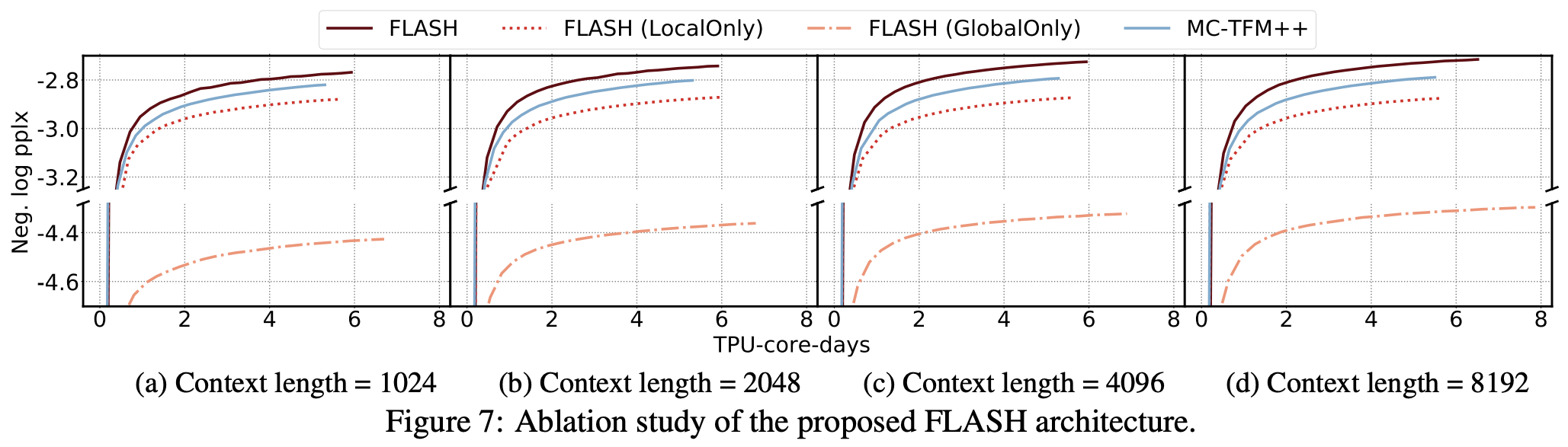
全局注意力和局部注意力的消融实验
此外,可能会有些读者担心这种非重叠的分块会不会不利于边界词的预测?原论文提到了这一点,它说引入更复杂的重叠式局部注意力确实有利于提升效果,但也引入了额外的计算成本,在增加同样计算成本的情况下,引入重叠式局部注意力带来的增益还不如直接多加几层目前的非重叠式GAU。所以说,目前的非重叠足够好地平衡了速度和效果。
最后,这种“分块混合”的线性化方案本质上是通用的,它不仅可以用于GAU中,也可以用于标准的Transformer中,即保留标准的Attention+FFN组合,然后Attention用分块混合的方式进行线性化,原论文称之为“MC-TFM”,并也进行了相应的比较,结果显示GAU在线性化方面也显得更有优势。
实验分析 #
关于GAU和FLASH的实验结果,笔者认为最值得留意的有两个。
第一个是新设计的门控注意力单元GAU与标准的多头注意力之间MHSA的比较,其实也就是FLASH-Quad和标准Transformer的比较了,如下图:

GAU与多头注意力的对比
注意横轴是速度,纵轴是效果,这种图越靠近右上角的点意味着越理想(速度和效果都最优),所以上图显示不管哪种规格的模型,GAU都比相应的多头注意力模型更有优势。
第二个则是FLASH模型的实验表格:
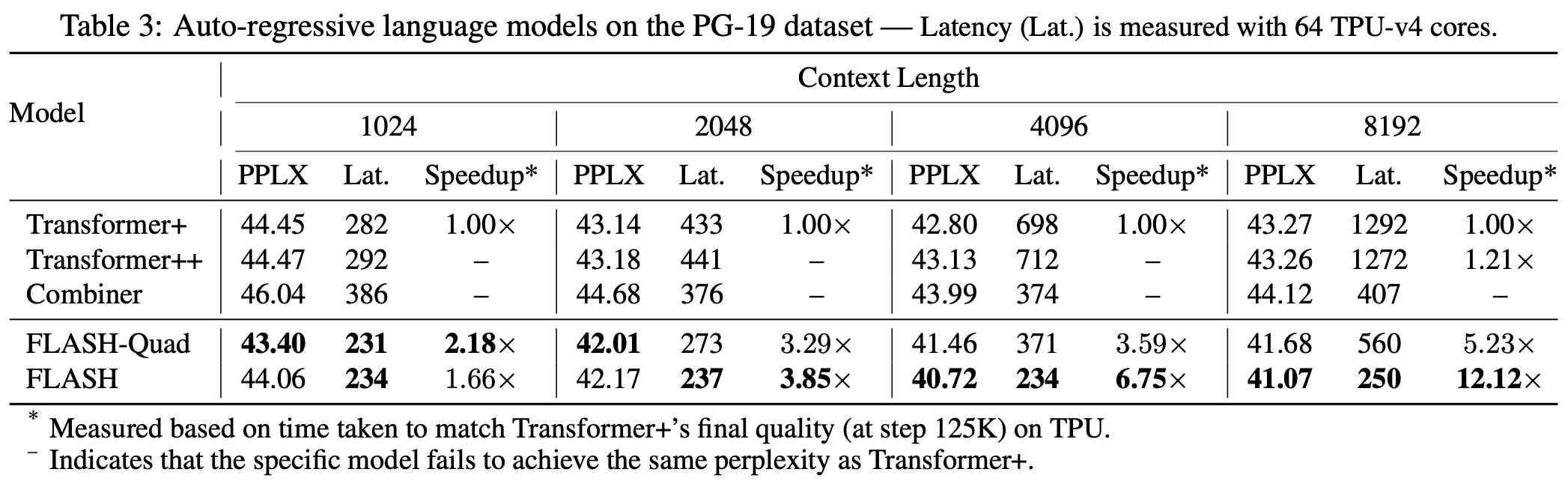
FLASH与标准Transformer的对比
该表格更直接地显示出:
1、尽管FLASH-Quad和Transformer都是二次复杂度,但FLASH-Quad效果更好、速度更快;
2、在序列足较长时,线性复杂度的FLASH比FLASH-Quad更快,并且效果相仿。
说实话,即便是FLASH-Quad这个依然是二次复杂度的模型的速度提升幅度,很多号称是线性复杂度的工作都未必能做到,GAU的强大可见一斑。对了,论文还特别指出笔者之前提的旋转位置编码RoPE能明显提高Transformer和FLASH的效果,所以论文实验的Transformer+、Transformer++、FLASH-Quad和FLASH都是带有RoPE编码的,在此沾沾自喜一下。
另外,上述表格并没有给出显存占用的对比。事实上,笔者测试发现,在base量级和序列长度为1024时,FLASH-Quad可用的最大batch_size将近是Transformer的两倍,这意味着FLASH-Quad明显降低了显存消耗。同时,笔者简单尝试了small版本FLASH-Quad的中文预训练,发现效果甚至比RoFormer(RoPE+Transformer)要好些,所以论文所报告的结果确实不虚。不过最近的卡有限,就没法进行更深入的测试了,以后有新结果再跟大家分享。
延伸思考 #
至此,对GAU、FLASH的介绍也基本结束了。到发博客时,作者还没有在Gihub上开放完整源代码,但是附录已经贴出了几乎可以直接抄来用的关键源码(tensorflow版),所以代码的实现应但是没有困难的,有兴趣有算力的同学,可以自行参考实验。另外论文有什么读不懂的地方,也可以直接参考源代码。
下面进行“挑骨头”环节,说一下我觉得这篇论文还做的不够完美的地方。
首先,笔者认为FLASH-Quad和FLASH解耦得不够好。如本文开头的观点,FLASH-Quad和FLASH都算得上是“重磅”级别的结果,甚至对笔者来说FLASH-Quad更有价值,因为自注意力的二次复杂度本身也带来了足够多的自由度,可以玩很多像UniLM这样的花样,所以FLASH-Quad本身应该是一个很独立、很值得肯定的模型,但在原论文中,它更像是FLASH的一个过渡产品,这我认为是过于“冷落”了FLASH-Quad。幸好,作者单独分离出了GAU的概念,也算是缓解了这个不足。
然后,GAU既可以代替Attention,也可以代替FFN,从设计上来看,它旨在代替的是Self-Attention,作者似乎不关心它对Cross Attention的可代替性,论文也没有相应的实验。那么,GAU是否有可能代替Cross Attention呢?从式$\eqref{eq:mix}$的形式看,理论上是有可能的,但不知道GAU代替Cross Attention时能否依然只保留一个头,因为只需一个头可谓是GAU替代Self Attention的最大亮点了,它是更快更省的关键。此外,论文只做了LM和MLM的语言模型实验,并没有做“预训练+微调”的实验,不确定GAU的迁移性能如何。或许等我有卡了,我也去补充一波实验。
最后,有一个笔者不大理解的地方,就是GAU/FLASH-Quad/FLASH同时用上了加性绝对、加性相对以及RoPE三种位置编码,理论上三者只用其一就行了,笔者自己做的GAU实验也只用RoPE但效果依然挺好,所以这里同时用三种有什么讲究吗?最后,从论文附录所给的源码看,作者并没有仔细处理好padding的问题,以及做Decoder是归一化因子递归也没有写好(前$t$项求和应该除以$t$而不是$n$),这些都是不大不小的可改善的细节。当然,不排除作者的原始代码是正确的,附录只是出于可读性目的做了简化,因为附录里边的代码还是以“伪代码”自称。
本文小结 #
本文介绍了Google新出的一个高效Transformer工作,里边将Attention和FFN融合为一个新的GAU层,从而得到了Transformer变体FLASH-Quad,作者还进一步提出了一种“分块混合”线性化方案,得到了具有线性复杂度的FLASH。目前的实验结果显示,不管FLASH-Quad还是FLASH,跟标准Transformer相比都是更快、更省、更好。也许不久之后,All You Need的就不再是Attention而是GAU了。
转载到请包括本文地址:https://kexue.fm/archives/8934
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Feb. 25, 2022). 《FLASH:可能是近来最有意思的高效Transformer设计 》[Blog post]. Retrieved from https://kexue.fm/archives/8934
@online{kexuefm-8934,
title={FLASH:可能是近来最有意思的高效Transformer设计},
author={苏剑林},
year={2022},
month={Feb},
url={\url{https://kexue.fm/archives/8934}},
}

February 25th, 2022
QK为什么是仿射变换?原版里面qkv都是一个全连接吧,为什么这里QK不走全连接呢
省点参数呀,更加突出了GAU对Attention依赖很弱的特点。
那么原版的transformer把qk换成仿射变换是不是也能在省参数情况下不怎么影响效果。
按照论文的意思是,标准Transformer没有gate机制,对注意力的依赖还是很大的。
其实省不省参数无所谓,因为那一块的参数很少,最重要的还是多头变单头,既省又快。
又仔细看了下伪代码,感觉不自然的地方太多,比如为什么uv都通过silu激活函数,为什么softmax用relu平方代替,为什么base经过rope后qk还加bias,为什么qk是仿射变换。给人感觉是作者想融合attn和mlp层,但不知道怎么组合好,于是很可能用nas试出了这个可能的最佳组合。
1、u、v加silu/swish没什么不自然的,所谓“不自然”只不过是我们先入为主认识了常规的GLU罢了,这一点不能拿来说事;
2、理论上,relu平方取代softmax的好处就是节省计算量,另外就是softmax的好处是带来Attention矩阵的稀疏性,而relu直接落实了这种稀疏性,所以也能理解,当然为什么是relu的平方不是一次方或者三次方,这个确实是NAS出来的,但另一方面来看,对于我们常用的softmax,我们又能说出多少真正“自然”、“合理”的理由呢,所以,还是抛开先入为主的观念的话,这也没什么值得吐槽的;
3、rope后加bias,确实值得吐槽,但我自己的实验没加bias也能work得不错,所以如果你对这一点不满意,可以去掉;
4、q/k通过简单仿射变换得出,论文的意思是为了节省参数量,我觉得还有另一种可能性,就是这样设计的话,初始状态下Attention矩阵就接近一个单位阵(的若干倍),这样可能更利于优化,其实只有一个头的话,q、k哪怕不共享参数量也不大,所以这个看自己喜欢吧。
February 25th, 2022
式6是不是应该是1/(n/c)?
不是,就是$1/n$,因为${\boldsymbol{K}_h^{\text{lin}}}^{\top}\boldsymbol{V}_h$这一步隐含了组内求和,所以总的求和数是$n/c\times c=n$。
那7式为什么除以了n/c啊?
哪是$n/c$,那么大个$g-1$看不见嘛。
February 25th, 2022
苏神,cosformer不值得讲一讲吗
相比FLASH,几乎所有的线性Transformer都黯然失色了。
而且从技术本身来看,私以为cosformer还不如同期的flowformer有启发性。
February 25th, 2022
你好,请问下为什么GLU的ffn比原始的ffn效果更好,原理是什么呢?是否可以推广到有mlp的地方替换成GLU+mlp的效果可能会更好?
为什么GLU的效果比FFN好,这问题我回答不了,只能直觉说门控机制的威力真大~
苏神你好,GLU的效果比FFN的效果好,有没有可能是这个过程很符合对信息处理的过程,通过门控的方法,利用当前的信息,决定后续往后流动的有用信息有哪些,有点去除噪音的感觉,通过不断的层叠网络,留下真正对任务有用的信息,细想起来也像是一种“注意力机制”,也有点像人类处理信息的方式,不断的去粗取精。
这种只能算直观的科普,不是理论解释。你这个解释可以照搬到ResNet、Attention等模型中去,而我们真正想知道的是它们的细微之处究竟有啥不同。
确实在理论上比较难解释,但是门控的这种设计,从网络结构上就显式的引入了对信息流动的控制,相当于有了一种结构先验,可能就稍微比没有这种结构的网络稍微好一点点。各种解释也是强行解释,苏神要不抽时间出个专题分析版。
我要是能分析出来我就写了~问题是现在我还没能力分析出来呢。
感谢回复
February 26th, 2022
个人实现了一个pytorch版本的FLASHQuad,大家可以帮我看看有没有啥错,谢谢。
https://github.com/JunnYu/FLASHQuad_pytorch
手动点赞,建议解耦开GAU,没必要100%对齐FLASH的论文实现
February 28th, 2022
大佬,请问分块与混合那部分,能像SwinTransformer那样用移动窗口去做吗?
都可以尝试。
March 2nd, 2022
苏神,在“现有方法”小节说到中:“又或者不牺牲并行性,但需要${bhns}_2$的空间复杂度”,我理解这里是$K(Z)∈ℝ_{n×s}$与$V∈ℝ_{n×e}$做外积,得到一个$n×s×e$的矩阵,然后对$n$那一维执行$cumsum$运算,如果是这样的话,那么空间复杂度应该为$bhnse$,不知我是否理解正确
是的。但我那句话的位置说的是标准的多头线性Attention,所以那种情况下是$\boldsymbol{V}\in\mathbb{R}^{n\times h\times s}$,最终复杂度就是$bhns^2$了。
按上下文意思确实时,但是看到用$s$标记就容易代入Flash
您好,想请教一下这个具体是咋实现并行化的呢?谢谢!
March 2nd, 2022
苏神后续有可能做一个关于这个模型的bert4keras的例子吗?期待~
https://github.com/bojone/bert4keras/blob/8bf47989488009c2b8f68c20a97000fb96e07f9b/bert4keras/layers.py#L583
具体的预训练模型后面再看算力是否充裕了。
March 3rd, 2022
请问代码在哪里呀?
论文附录,或者 https://github.com/bojone/bert4keras/blob/8bf47989488009c2b8f68c20a97000fb96e07f9b/bert4keras/layers.py#L583
March 4th, 2022
请教一下关于弱注意力那部分的A的公式,
$A = \frac{1}{n} \text{relu}^2 (...)$
这个开头的归一化因子 1/n 我好像没在原文 equation(5) 中看到过
看附录源码,以及本文在下面的介绍文字。论文正文只给出了最核心的运算,很多细节在源码中。