






19
Jul
通过互信息思想来缓解类别不平衡问题
By 苏剑林 | 2020-07-19 | 232306位读者 |类别不平衡问题,也叫“长尾问题”,是机器学习面临的常见问题之一,尤其是来源于真实场景下的数据集,几乎都是类别不平衡的。大概在两年前,笔者也思考过这个问题,当时正好对“互信息”相关的内容颇有心得,所以构思了一种基于互信息思想的解决办法,但又想了一下,那思路似乎过于平凡,所以就没有深究。然而,前几天在arxiv上刷到Google的一篇文章《Long-tail learning via logit adjustment》,意外地发现里边包含了跟笔者当初的构思几乎一样的方法,这才意识到当初放弃的思路原来还能达到SOTA的水平~于是结合这篇论文,将笔者当初的构思过程整理于此,希望不会被读者嫌弃“马后炮”。
问题描述 #
这里主要关心的是单标签的多分类问题,假设有$1,2,\cdots,K$共$K$个候选类别,训练数据为$(x,y)\sim\mathcal{D}$,建模的分布为$p_{\theta}(y|x)$,那么我们的优化目标是最大似然,或者说最小化交叉熵,即
\begin{equation}\mathop{\text{argmin}}_{\theta}\,\mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p_{\theta}(y|x)]\end{equation}
通常来说,我们建立的概率模型最后一步都是softmax,假设softmax之前的结果为$f(x;\theta)$(即logits),那么
\begin{equation}-\log p_{\theta}(y|x)=-\log \frac{e^{f_y(x;\theta)}}{\sum\limits_{i=1}^K e^{f_i(x;\theta)}}=\log\left[1 + \sum_{i\neq y}e^{f_i(x;\theta) - f_y(x;\theta)}\right]\label{eq:loss-1}\end{equation}
所谓类别不均衡,就是指某些类别的样本特别多,就好比“20%的人占据了80%的财富”一样,剩下的类别数很多,但是总样本数很少,如果从高到低排序的话,就好像带有一条很长的“尾巴”,所以叫做长尾现象。这种情况下,我们训练的时候采样一个batch,很少有机会采样到低频类别,因此很容易被模型忽略了低频类。但评测的时候,通常我们又更关心低频类别的识别效果,这便是矛盾之处。
常见思路 #
常见的思路大家应该也有所听说,大概就是三个方向:
1、从数据入手,通过过采样或降采样等手段,使得每个batch内的类别变得更为均衡一些;
2、从loss入手,经典的做法就是类别$y$的样本loss除以类别出现的频率$p(y)$;
3、从结果入手,对正常训练完的模型在预测阶段做些调整,更偏向于低频类别,比如正样本远少于负样本,我们可以把预测结果大于0.2(而不是0.5)都视为正样本。
Google的原论文中对这三个方向的思路也列举了不少参考文献,有兴趣调研的读者可以直接阅读原论文,另外,知乎上的文章《Long-Tailed Classification (2) 长尾分布下分类问题的最新研究》也对该问题进行了介绍,读者也可以参考阅读。
学习互信息 #
回想一下,我们是怎么断定某个分类问题是不均衡的呢?显然,一般的思路是从整个训练集里边统计出各个类别的频率$p(y)$,然后发现$p(y)$集中在某几个类别中。所以,解决类别不平衡问题的重点,就是如何把这个先验知识$p(y)$融入模型之中。
在之前构思词向量模型(如文章《更别致的词向量模型(二):对语言进行建模》)的时候,我们就强调过,相比拟合条件概率,如果模型能直接拟合互信息,那么将会学习到更本质的知识,因为互信息才是揭示核心关联的指标。但是拟合互信息没那么容易训练,容易训练的是条件概率,直接用交叉熵$-\log p_{\theta}(y|x)$进行训练就行了。所以,一个比较理想的想法就是:如何使得模型依然使用交叉熵为loss,但本质上是在拟合互信息?
在公式$\eqref{eq:loss-1}$中,我们是建模了
\begin{equation}p_{\theta}(y|x)=\frac{e^{f_y(x;\theta)}}{\sum\limits_{i=1}^K e^{f_i(x;\theta)}}\end{equation}
现在我们改为建模互信息,那么也就是希望
\begin{equation}\log \frac{p_{\theta}(y|x)}{p(y)}\sim f_y(x;\theta)\quad \Leftrightarrow\quad \log p_{\theta}(y|x)\sim f_y(x;\theta) + \log p(y)\end{equation}
按照右端的形式重新进行softmax归一化,那么就有$p_{\theta}(y|x)=\frac{e^{f_y(x;\theta)+\log p(y)}}{\sum\limits_{i=1}^K e^{f_i(x;\theta)+\log p(i)}}$,或者写成loss形式:
\begin{equation}-\log p_{\theta}(y|x)=-\log \frac{e^{f_y(x;\theta)+\log p(y)}}{\sum\limits_{i=1}^K e^{f_i(x;\theta)+\log p(i)}}=\log\left[1 + \sum_{i\neq y}\frac{p(i)}{p(y)}e^{f_i(x;\theta) - f_y(x;\theta)}\right]\label{eq:loss-2}\end{equation}
原论文称之为logit adjustment loss。如果更加一般化,那么还可以加个调节因子$\tau$:
\begin{equation}-\log p_{\theta}(y|x)=-\log \frac{e^{f_y(x;\theta)+\tau\log p(y)}}{\sum\limits_{i=1}^K e^{f_i(x;\theta)+\tau\log p(i)}}=\log\left[1 + \sum_{i\neq y}\left(\frac{p(i)}{p(y)}\right)^{\tau}e^{f_i(x;\theta) - f_y(x;\theta)}\right]\label{eq:loss-3}\end{equation}
一般情况下,$\tau=1$的效果就已经接近最优了。如果$f_y(x;\theta)$的最后一层有bias项的话,那么最简单的实现方式就是将bias项初始化为$\tau\log p(y)$。也可以写在损失函数中:
import numpy as np
import keras.backend as K
def categorical_crossentropy_with_prior(y_true, y_pred, tau=1.0):
"""带先验分布的交叉熵
注:y_pred不用加softmax
"""
prior = xxxxxx # 自己定义好prior,shape为[num_classes]
log_prior = K.constant(np.log(prior + 1e-8))
for _ in range(K.ndim(y_pred) - 1):
log_prior = K.expand_dims(log_prior, 0)
y_pred = y_pred + tau * log_prior
return K.categorical_crossentropy(y_true, y_pred, from_logits=True)
def sparse_categorical_crossentropy_with_prior(y_true, y_pred, tau=1.0):
"""带先验分布的稀疏交叉熵
注:y_pred不用加softmax
"""
prior = xxxxxx # 自己定义好prior,shape为[num_classes]
log_prior = K.constant(np.log(prior + 1e-8))
for _ in range(K.ndim(y_pred) - 1):
log_prior = K.expand_dims(log_prior, 0)
y_pred = y_pred + tau * log_prior
return K.sparse_categorical_crossentropy(y_true, y_pred, from_logits=True)结果分析 #
很明显logit adjustment loss也属于调整loss方案之一,不同的是它是在$\log$里边调整权重,而常规的思路则是在$\log$外调整。至于它的好处,就是互信息的好处:互信息揭示了真正重要的关联,所以给logits补上先验分布的bias,能让模型做到“能靠先验解决的就靠先验解决,先验解决不了的本质部分才由模型解决”。
在预测阶段,根据不同的评测指标,我们可以制定不同的预测方案。从《函数光滑化杂谈:不可导函数的可导逼近》可以知道,对于整体准确率而言,我们有近似
\begin{equation}\text{整体准确率} \approx \frac{1}{N}\sum_{i=1}^N p_{\theta}(y_i|x_i)\end{equation}
其中$\{(x_i,y_i)\}_{i=1}^N$是验证集。所以如果不考虑类别不均衡情况,追求更高的整体准确率,那么对于每个$x$我们直接输出$p_{\theta}(y|x)$最大的类别即可。但如果我们希望每个类的准确率都尽可能高,那么我们将上式改写成
\begin{equation}\text{整体准确率} \approx \frac{1}{N}\sum_{i=1}^N \frac{p_{\theta}(y_i|x_i)}{p(y_i)}\times p(y_i)=\sum_{y=1}^K p(y)\left(\frac{1}{N}\sum_{x_i\in\Omega_y} \frac{p_{\theta}(y|x_i)}{p(y)}\right)\end{equation}
其中$\Omega_y=\{x_i|y_i=y,i=1,2,\cdots,N\}$,也标签为$y$的$x$的集合,等号右边事实上就是先将同一个$y$的项合并起来。我们知道“整体准确率=每一类的准确率的加权平均”,而上式正好具有同样的形式,所以括号里边的$\frac{1}{N}\sum\limits_{x_i\in\Omega_y} \frac{p_{\theta}(y|x_i)}{p(y)}$就是“每一类的准确率”的一个近似了,因此,如果我们希望每一类的准确率都尽可能高,我们则要输出使得$\frac{p_{\theta}(y|x)}{p(y)}$最大的类别(不加权)。结合$p_{\theta}(y|x)$的形式,我们有结论
\begin{equation}y^{*}=\left\{\begin{aligned}&\mathop{\text{argmax}}\limits_y\, f_y(x;\theta)+\tau\log p(y),\quad(\text{追求整体准确率})\\
&\mathop{\text{argmax}}\limits_y\, f_y(x;\theta),\quad(\text{希望每一类的准确率都尽可能均匀})
\end{aligned}\right.\end{equation}
第一种其实就是输出条件概率最大者,而第二种就是输出互信息最大者,按具体需求选择。
至于详细的实验结果,大家可以自行看论文,总之就是好到有点意外:
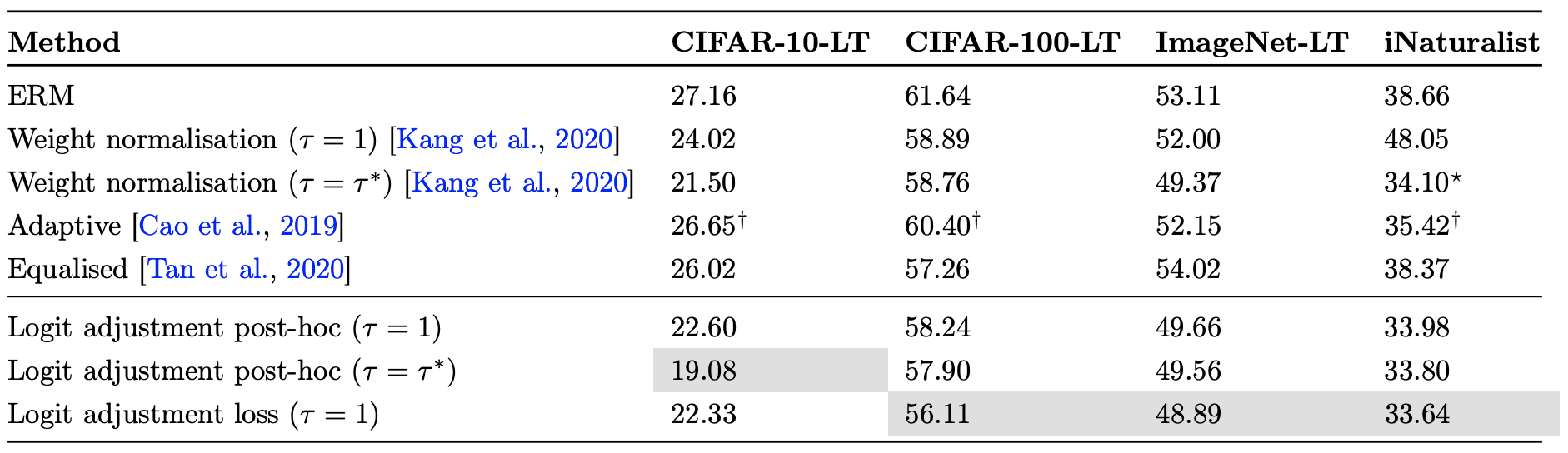
原论文的实验结果
文章小结 #
本文简单介绍了一种基于互信息思想的类别不平衡处理办法,该方案以前笔者也曾经构思过,不过没有深究,而最近Google的一篇论文也给出了同样的方法,遂在此简单记录分析一下,最后Google给出的实验结果显示该方法能达到SOTA的水平。
转载到请包括本文地址:https://kexue.fm/archives/7615
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jul. 19, 2020). 《通过互信息思想来缓解类别不平衡问题 》[Blog post]. Retrieved from https://kexue.fm/archives/7615
@online{kexuefm-7615,
title={通过互信息思想来缓解类别不平衡问题},
author={苏剑林},
year={2020},
month={Jul},
url={\url{https://kexue.fm/archives/7615}},
}

July 22nd, 2020
苏神,这篇文章有两个地方不理解,劳驾可否解惑一下:
1、公式4的左端对互信息的建模的公式不理解。
2、‘所以如果不考虑类别不均衡情况,追求更高的整体准确率,那么对于每个x我们直接输出pθ(y|x)最大的类别即可。’为什么可以得到公式9的1式?同样的‘如果我们希望每个类的准确率都尽可能高,则要输出使得pθ(y|x)p(y)最大的类别’为什么能得到公式9的2式??推断过程看明白了,就是论据跟结论之间的确立关系不明白。也可以这么理解问题:为什么加入先验知识可以提高模型的整体准确率?不加先验知识可以获得‘类别准确率均匀’??
谢谢~
1、我们的初衷不是为了解决类别不均衡问题导致长尾数据准确度角度低的问题?加入先验知识收获的不是应该是‘类别准确率均匀’么?
2、为什么加入先验知识后,输出的是pθ(y|x)最大的类别?不加入先验知识,输出的使得pθ(y|x)p(y)最大的类别??(灬ꈍ ꈍ灬)
蟹蟹~~
1、不知道你想表达什么;
2、本文没有你说的情况。
这还有1个问题:
1、“softmax+交叉熵”本身是可以解决类别不平衡问题,在这里提出的方法也是基于softmax+交叉熵加入先验知识来解决类别不平衡问题,softmax+交叉熵是否是只是能在一定程度上解决类别不均衡问题(主要比较对象是sigmoid)?softmax+交叉熵+先验知识叠加在一起的话,理论上在解决类别不均衡问题上效果是比只用softmax+交叉熵要好的??
如果你说的是之前那篇将softmax+交叉熵推广到多标签分类的文章,那么这两者是不一样的不平衡。
之前说的多标签多分类的不平衡,指的是”目标类比非目标类要多“,但目标类的分布还是均匀的;这篇文章的单标签多分类的不平衡,指的是“某些类作为目标类出现次数过多”,也就是目标类的分布不均匀。
1、什么叫做不理解?
2、公式9来源于公式7、8它们之间的文字描述。
至于你疑问的“为什么”,最根本的答案是“因为实验效果好”。如果非要讲什么故事,那么本文内已经讲了,用$f_{\theta}(x)$学习互信息,相比用它学习条件概率,能学习到更核心的关联。或者说,能让$f_{\theta}(x)$在真正有必要学习的时候才去学习。
嗯~,行吧,有空我再多多读几遍。谢谢~
August 13th, 2020
你好,看了你很多关于熵的内容。想请教你一个问题。
关于连续型随机变量的熵,香农的定义是 $- \int p(x) log \: p(x)dx $也叫微分熵
但这种定义是有缺陷的,它不满足变量替换的不变性,甚至可能是负数。
这使得不放心将其应用。
详见[维基百科](https://www.wikiwand.com/en/Differential_entropy)
我困惑为啥熵能取到负值,看了微分熵的定义,我注意到一点
$-\sum p(x)dx log [p(x)dx] $的极限似乎才是合理的定义。与香农的定义差了一个$dx$,数学功底差。。。拆到后面不会算了。
?这种计算应该不会取到负值,而指数分布$\lambda e^{\lambda x}$的微分熵是$1-ln\lambda$。可以为负值,我想我定义的与微分熵的结果应该是不同的。
不知道你怎么看?
你的思考没有问题,而且很棒,类似的思考我也有过。关键的问题在于$\log dx$在数值上不是一个可忽略的量,但它又可以类比地看作是趋于负无穷的“常数”,所以我们可以去掉$\log dx$而采用标准形式。
你好
我又参考了[Differential Entropy and “Limiting density of discrete points”](https://math.stackexchange.com/questions/3536042/differential-entropy-and-limiting-density-of-discrete-points)
这篇回答,$-\sum p(x)\nabla log \: \nabla$的极限是无穷大,并且提到了‘unrenormalized entropy’的概念来表示这个无穷大的量,在量子力学关于熵的理论中也有类似的理论。
文中提到了绝对的熵都是无穷,因此没有意义。而相对的熵则是可以有意义的。
幸运的是KL散度、互信息都可以看作相对度量。尽管有点忐忑,似乎用是没有问题的。
不过我对连续变量的熵究竟如何理解依然很感兴趣,现实中我们往往使用连续变量,即便量化,数据样本也太少以至于没有统计意义。
主要是想知道熵与描述复杂度(很重要)的联系,(直觉上是有的),不过肯定不是一回事,正太分布的微分熵大,但描述复杂度高吗?也可以认为正太分布是一种简单分布吧(因为常见)。
想问一问博主的看法。
先说说我的一个想法吧。
我在知乎[熵是什么](https://zhuanlan.zhihu.com/p/103369369)一文中关于统计力学的熵的定义中找到些许灵感,可测度熵=总熵-不可测度的熵。
我感觉问题的关键在于测度,即区分(识别)随机变量的取值。似乎在测度上,离散随机变量与连续随机变量存在不同。对于离散随机变量,每种取值都是可测度的,而连续型随机变量这点则没被考虑过。对于
参考另一篇关于描述复杂度的博文[算法信息论随笔](https://zhuanlan.zhihu.com/p/33600595),其中一个关于图灵机概率的定义$p=2^{-n}$,其含义是越复杂的图灵机出现的概率越低。反推我们可以得出$n=-log \: p$。
由此启发,可以将$-log \: p$看作复杂度的度量,这也很合理,对于经常出现的事件更容易区分。
平均识别困难度=$\int p(x)D(x)dx$其中$D(x)$当作$x$本识别的困难程度(似乎这个和描述复杂度很相像了)。在离散随机变量的熵的定义中,$D(x)=-log \: p(x)$。我觉得对于识别,样本之间的距离也是值得考虑的因素,可以用与其它各个样本距离的期望来定义。不过这里也还只是大胆猜测的程度,要想定义一个好的度量,还要满足很多约束,如量纲选取的不变性等。
这里也想听听博主的看法
另外
[Limiting density of discrete points](https://www.wikiwand.com/en/Limiting_density_of_discrete_points)一文中,对微分熵作了改进。
我的理解是,他假设$lim_{N \rightarrow \infty} \frac{1}{N}(\text {number of points in a < x < b}) = \int_{a}^{b} m(x) d x $
对一个小区间$[a, b]$的概率密度函数用$m(x)$表示,$m(x)$一般取均匀分布。新的熵的定义为:
$\lim _{N \rightarrow \infty} H_{N}(X)=\log (N)-\int p(x) \log \frac{p(x)}{m(x)} d x$
这个定义可以满足很多微分熵的性质,这个可以和上面说的一些内容作应证,只作参考。
个人感觉实用性好像不强?老实说,我不懂如何方便的取$m$,如何应用。
弯弯绕绕,从不懂到以为懂了,结果扎进去又发现自己根本没懂。应了政治那啥,认知是螺旋上升的?
感谢回答,也希望看到更多博主关于此的博文。
感谢你这个长长的回复,让我有点受宠若惊了,哈哈。
我前后看了一下,其实你的困惑,只要你放弃“熵是绝对的”这个思想,就可以顺利得到解决。熵是相对的,所以某些特殊情况下其值趋于无穷也无妨,因为这不妨碍相对比较;同时,熵在换元的情况下可能发生变化(差一个行列式),那还是因为熵是相对的,依赖于具体的流形(或者说测度)。接受这两点作为熵的基本性质即可。
August 13th, 2020
这里自定义的prior是通过统计train dataset中各类的比例而定义的吗? 还是可以采用其他方式定义prior呢?
嗯,一般是直接统计就好。
August 18th, 2020
请问文章可以转载吗?谢谢
可以,保留个链接即可~参考:https://kexue.fm/archives/6508#%E6%96%87%E7%AB%A0%E5%A6%82%E4%BD%95%E8%BD%AC%E8%BD%BD/%E5%BC%95%E7%94%A8
August 24th, 2020
写了个pytorch的代码, 发现连优化都做不到了, 仔细看了下原文的公式, 改了下正负号, 大佬可以检查下是不是符号错了
y_pred = y_pred + tau * log_prior --> y_pred = y_pred - tau * log_prior
没有搞错,就是正号,原文也是正号,我不知道你哪里看到了负号(原文的公式$(10)$是正号)。我也不至于故事讲得头头是道,结果讲的全是搞错的符号吧~
原文 第8, 9个公式, 以下为第9个公式
$argmax_{y\in [L]} exp(w^T\Phi(x))/\pi(y)^T=argmax_{y∈[L]} f_y(x) − τ · \log π(y)$
在实际代码中, 我使用softmax的结果和类别的先验概率
```python
self.weight=-tau*torch.log(class_dist+1e-8)
y_pred = F.softmax(y_pred, dim=-1)
y_pred=y_pred+self.weight
crossEntropyLoss(y_pred, Variable(true_dist, requires_grad=False), weight=self.weight, reduction='sum')
```
另附互信息公式直觉 argmax H(y)-H(y|x) -> argmin H(y|x)-H(y)
原文将$exp_y(x)$作为p(y|x)的表达(估计?这个地方的描述不是特别准确), 从优化角度上看, 由于exp(x)是与log(x)单调性相似的函数,我个人理解没有影响
请指正,哈哈
你这一看就是没认真读论文的。
原论文的公式$(9)$,那一节的名字叫做“post-hoc logit adjustment”,意思是用正常的方式训练完模型后,预测的时候不输出$\mathop{\arg\max}_y f_y(x)$而是输出$\mathop{\arg\max}_y f_y(x)-\tau \log \pi(y)$,这是一种后处理方式,不是训练方式。
公式$(10)$才叫做“logit adjusted softmax cross-entropy”,公式$(10)$才是要用来训练的。
August 27th, 2020
哈哈哈,被发现了,受教了,回去看了下论文,仔细体会了下,确实如大佬所说。 我也写了个分类例子, 发现两种情形下,运气好都能优化(尴尬的是,我随机测了好几遍都效果没啥明显区别,只能说明随机例子不够适合), 运气不好都挂掉(也可能是随机数据太乱,模型又太简单)。 另外仔细调教了下自己模型的代码,发现在我的模型上使用这个方法不时会无法进行优化(early stopping死在第一个epoch),暂时无法确定是模型和方法上的具体那一部分的问题。这里附上例子代码,有时间和精力的人可以仔细分析下,谢谢大佬哈哈
```python
%matplotlib inline
import torch
import torch.nn as nn
x=torch.tensor([[i,i**2] for i in range(100)],dtype=torch.float32)
y=(torch.randn((100))>0).int()
import matplotlib.pyplot as plt
plt.plot(x[:,0],y)
from collections import Counter
y_c=Counter(y.numpy())
print(y_c)
x.requires_grad_=False
y.requires_grad_=False
import random
l = [i for i in range(100)];
y=y.long()
model=nn.Sequential(nn.Linear(2,8),nn.ReLU6(),nn.Linear(8,8),nn.GELU(),nn.Linear(8,2))
adaOpt=torch.optim.SGD(model.parameters(),lr=0.01)
y_prior=torch.log(torch.tensor([62.,38.],requires_grad=False))#根据上面统计的比例填入
criterion=nn.CrossEntropyLoss(reduction='sum')
eps=[]
lss=[]
accs=[]
for ep in range(5000):
random.shuffle(l)
y_pred=model.forward(x[l])
# print('acc:', (y_pred.argmax(-1)==y).sum().item(),'%')
loss=criterion(y_pred+y_prior,y)
loss.backward()
adaOpt.step()
adaOpt.zero_grad()
# print('loss:', loss.item())
eps.append(ep)
lss.append(loss.item())
accs.append((y_pred.argmax(-1)==y).sum().item())
plt.plot(eps,lss)
plt.plot(eps,accs)
```
“early stopping死在第一个epoch”是个什么现象?换个loss就卡死了?这不应该吧?
我仔细检查了下,在最后的线性层做损失函数的计算时候应该仍然需要softmax, 否则遇到线性层预测的负值直接上交叉熵损失函数就死掉/爆炸了, 例如预测二分类任务下最后线性层对于某一个样例预测输出(-100,10),设先验log后的结果为(5,2), 那么相加后结果为(-95,12),设真实标签为(1,0), 那么交叉熵为log(-95)+0log(14), 這样就不行了, 上面的描述有没有问题可以检查下(這样一想,如果真是這样,从学术上看一个大的idea就变得庸俗了,只是softmax前后的正负号的区别,哈哈哈)
是要加softmax的啊。我实现的时候,强调y_pred不要加softmax,是因为我后面用了K.categorical_crossentropy(y_true, y_pred, from_logits=True),其中from_logits=True会帮我自动补上softmax。
而且公式$(6)$也说得很清楚了,是$-\log\text{softmax}(f_y(x;\theta)+\tau\log p(y))$。不知道为啥现在还有这个疑问...
August 29th, 2020
我的锅我的锅, 我没咋用过keras, 上来按照大佬代码猛敲了一顿pytorch, 然后发现不行, 然后去原文抓了波公式, 奏效后就没有仔细搞了, 预测完调整效果提升1%, 回复后又搞了一波, 还是有疏漏把, 不好意思. 回头空闲点再弄个仔细的评测发上来,哈哈,
先把本文通读一遍(捂脸)
September 7th, 2020
苏神,确认一下,这样模型里面出来的y_pred,实际上是互信息,对吧
只能说y_pred跟互信息更加正相关,不能说就是互信息。
对对对,我也是这么觉得,但由于底子差,也不太好意思问
我的理解,看看对不对。
$f_{y}(x;\theta)$应该就是y_pred。实现的时候,应该就是按照公式$\log{pθ(y|x)}\sim{f_{y}(x;\theta) + \log{p(y)}}$,对于y_pred加了$\log{p(y)}$,得到$\log{pθ(y|x)}$。后面重新归一化后重新代入计算交叉熵那段,好像也能理解大概的意思。
有几个问题,虽然很低级,但是还是硬着头皮问一下:
1、y_pred,也就是$f_{y}(x;\theta)$,到底是个啥
2、归一化,是在K.categorical_crossentropy里面自动完成了,是吧
3、在预测的时候
$$y^*=\begin{cases}
argmax\quad f_y(x;\theta)+ \tau\log{p(y)}& \text{(追求整体准确率)}\\
argmax\quad f_y(x;\theta)& \text{(希望每一类的准确率都尽可能均匀)}
\end{cases}$$
$\tau\log{p(y)}$好像是常数?那和用传统交叉熵训练,预测的时候看情况多减去一个$\tau\log{p(y)}$有啥区别?好像哪里不对,又想不太明白
哦,好像有点像明白了,是因为交叉熵函数对于x求导的结果里面还是和x相关的,相差的$\tau\log{p(y)}$还是在影响梯度的,是这样吧
1、为什么一定要关心y_pred是个啥?给出个名字很重要吗?那如果正常训练的y_pred又是个啥?
2、from_logits=True会自动加上softmax
3、$\tau\log p(y)$是个常向量(每个类的数值可能不一样)。至于“用传统交叉熵训练,预测的时候看情况多减去一个$\tau\log p(y)$有啥区别?”,其实没啥大区别,原论文里边确实有说了这种方案,也是可行的。
明白了,多谢解惑!
其实也不是在纠结拉,只是编辑这个回复花了比较多的时间,没有想到你已经马上回复了,所以列在里面
November 28th, 2020
你不是有篇文章 用无监督学习利用互信息来提取特征的文章吗?不是可以根据那篇文章的思路利用互信息来训练模型吗
然后呢?没看明白你要表达什么。
December 24th, 2020
苏神您好,想问一下就是prior是用的频率还是频数啊?如果有频率的话,取log会出现负数,不知道会不会有影响。
很明显因为有softmax的存在,不管用频率还是用频数,结果都是等价的,不会有什么影响。