






6
May
记录一次爬取淘宝/天猫评论数据的过程
By 苏剑林 | 2015-05-06 | 213275位读者 |笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行。对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了。本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似的做法,不赘述。主要是分析页面以及用Python实现简单方便的抓取。
笔者使用的工具如下
Python 3——极其方便的编程语言。选择3.x的版本是因为3.x对中文处理更加友好。
Pandas——Python的一个附加库,用于数据整理。
IE 11——分析页面请求过程(其他类似的流量监控工具亦可)。
剩下的还有requests,re,这些都是Python自带的库。
实例页面(美的某热水器):http://detail.tmall.com/item.htm?id=41464129793
评论在哪里? #
要抓取评论数据,首先得找到评论究竟在哪里。打开上述网址,然后查看源代码,发现里面并没有评论内容!那么,评论数据究竟在哪里呢?原来天猫使用了ajax加密,它会从另外的页面中读取评论数据。
这时候IE 11就发挥作用了(当然你也可以使用其他的流量监控工具),使用前,先打开上述网址,待页面打开后,清除一下IE 11的缓存、历史文件等,然后按F12,会出现如下界面
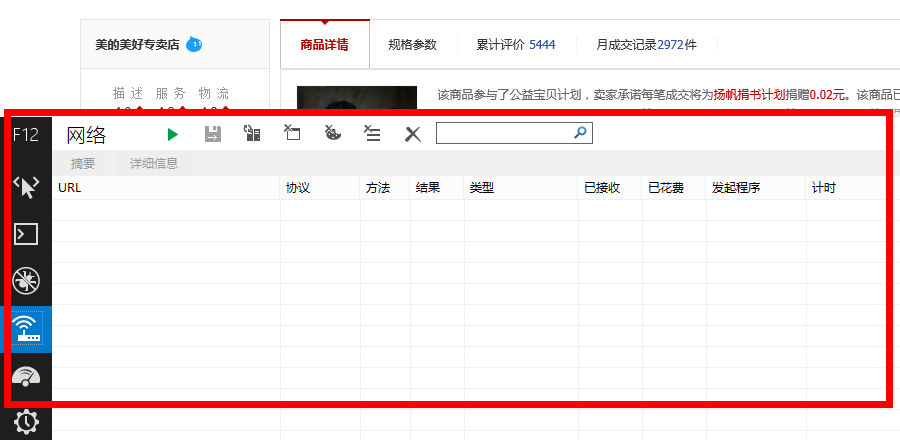
F12
这时候点击绿色的三角形按钮,启动网络流量捕获(或者直接按F5),然后点击天猫页面中的“累计评价”:
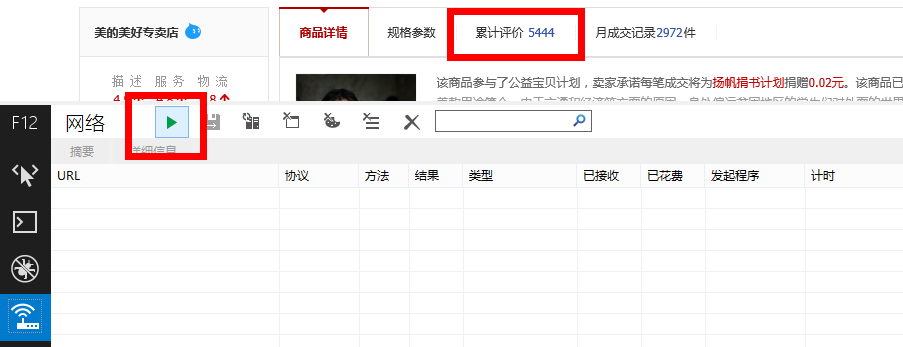
捕获
出现如下结果
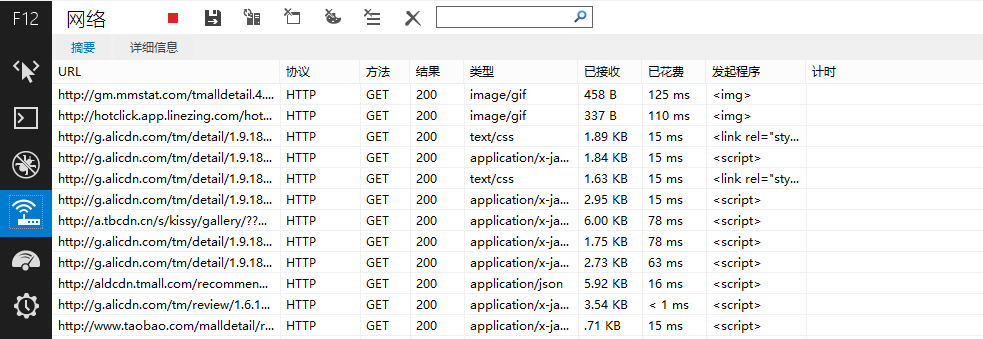
捕获结果
在URL下面出现很多网址,而评论数据正隐藏在其中!我们主要留意类型为“text/html”或者“application/json”的网址,经过测试发现,天猫的评论在下面这个网址之中
http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&spuId=296980116&sellerId=1652490016&order=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=166UW5TcyMNYQwiAiwVQX1EeUR5RH5Cd0xiNGI%3D%7CUm5Ockt1SHxBe0B0SXNOdCI%3D%7CU2xMHDJxPk82UjVOI1h2VngRd1snQSJEI107F2gFfgRlAmRKakQYeR9zFGoQPmg%2B%7CVGhXd1llXGJfa1ZsV2NeZFljVGlLdUt2TXFOc0tyT3pHe0Z6QHlXAQ%3D%3D%7CVWldfS0SMgo3FysUNBonHyMdNwI4HStHNkVrPWs%3D%7CVmhIGCIWNgsrFykQJAQ6DzQAIBwiGSICOAM2FioULxQ0DjEEUgQ%3D%7CV25OHjAePgA0DCwQKRYsDDgHPAdRBw%3D%3D%7CWGFBET8RMQ04ACAcJR0iAjYDNwtdCw%3D%3D%7CWWBAED5%2BKmIZcBZ6MUwxSmREfUl2VmpSbVR0SHVLcU4YTg%3D%3D%7CWmFBET9aIgwsECoKNxcrFysSL3kv%7CW2BAED5bIw0tESQEOBgkGCEfI3Uj%7CXGVFFTsVNQw2AiIeJxMoCDQIMwg9az0%3D%7CXWZGFjhdJQsrECgINhYqFiwRL3kv%7CXmdHFzkXNws3DS0RLxciAj4BPAY%2BaD4%3D%7CX2ZGFjgWNgo1ASEdIxsjAz8ANQE1YzU%3D%7CQHtbCyVAOBY2Aj4eIwM%2FAToONGI0%7CQXhYCCYIKBMqFzcLMwY%2FHyMdKRItey0%3D%7CQntbCyULKxQgGDgEPQg8HCAZIxoveS8%3D%7CQ3paCiQKKhYoFDQIMggwEC8SJh8idCI%3D%7CRH1dDSMNLRIrFTUJMw82FikWKxUueC4%3D%7CRX5eDiAOLhItEzMOLhIuFy4VKH4o%7CRn5eDiAOLn5GeEdnW2VeYjQUKQknCSkQKRIrFyN1Iw%3D%3D%7CR35Dfl5jQ3xcYFllRXtDeVlgQHxBYVV1QGBfZUV6QWFZeUZ%2FX2FBfl5hXX1AYEF9XXxDY0J8XGBbe0IU&isg=B2E8ACFC7C2F2CB185668041148A7DAA&_ksTS=1430908138129_1993&callback=jsonp1994
是不是感觉长到晕了?不要紧,只需要稍加分析,就发现可以精简为以下部分
http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1
我们发现天猫还是很慷慨的,评论页面的地址是很有规律的(像京东就完全没规律了,随机生成。),其中itemId是商品id,sellerid是卖家id,currentPage是页面号。
怎么爬取? #
费了一番周折,终于找到评论在哪里了,接下来是爬取,怎么爬取呢?首先分析一下页面规律。
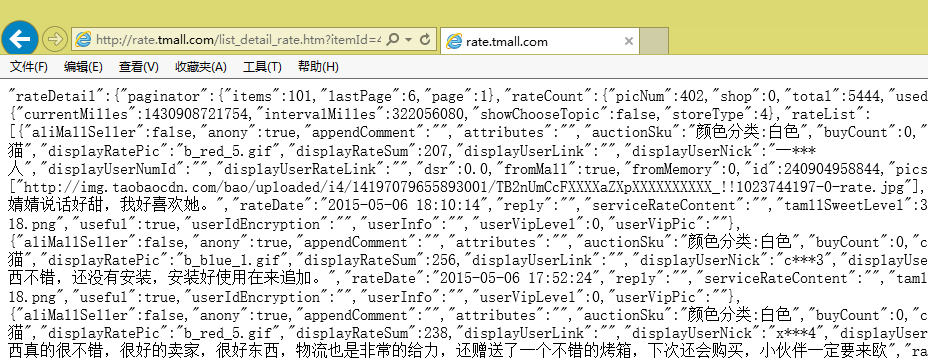
页面格式
我们发现页面数据是很规范的,事实上,它是一种被称为JSON的轻量级数据交换格式(大家可以搜索JSON),但它又不是通常的JSON,事实上,页面中的方括号[]里边的内容,才是一个正确的JSON规范文本。
下面开始我们的爬取,我使用Python中的requests库进行抓取,在Python中依次输入:
import requests as rq
url='http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1'
myweb = rq.get(url)现在该页面的内容已经保存在myweb变量中了,我们可以用myweb.text查看文本内容。
接下来就是只保留方括号里边的部分,这需要用到正则表达式了,涉及到的模块有re。
import re
myjson = re.findall('\"rateList\":(\[.*?\])\,\"tags\"',myweb.text)[0]呃,这句代码什么意思?懂Python的读者大概都能读懂它,不懂的话,请先阅读一下相关的正则表达式的教程。上面的意思是,在文本中查找下面标签
"rateList":[...],"tags"
找到后保留方括号及方括号里边的内容。为什么不直接以方括号为标签呢,而要多加几个字符?这是为了防止用户评论中出现方括号而导致抓取出错。
现在抓取到了myjson,这是一个标准的JSON文本了,怎么读取JSON?也简单,直接用Pandas吧。这是Python中强大的数据分析工具,用它可以直接读取JSON。当然,如果仅仅是为了读取JSON,完全没必要用它,但是我们还要考虑把同一个商品的每个评论页的数据都合并成一个表,并进行预处理等,这时候Pandas就非常方便了。
import pandas as pd
mytable = pd.read_json(myjson)现在mytable就是一个规范的Pandas的DataFrame了:
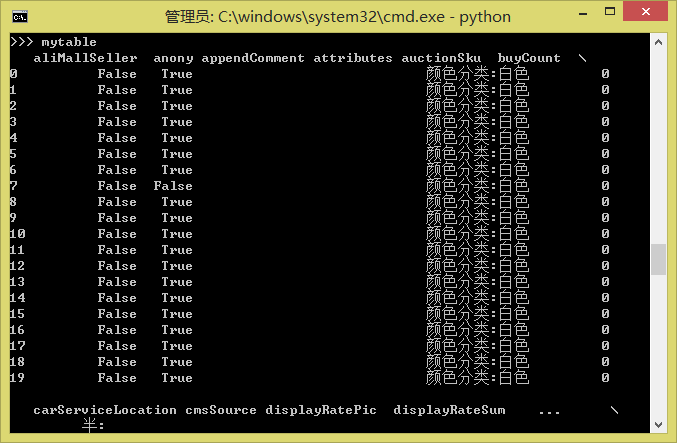
mytable1
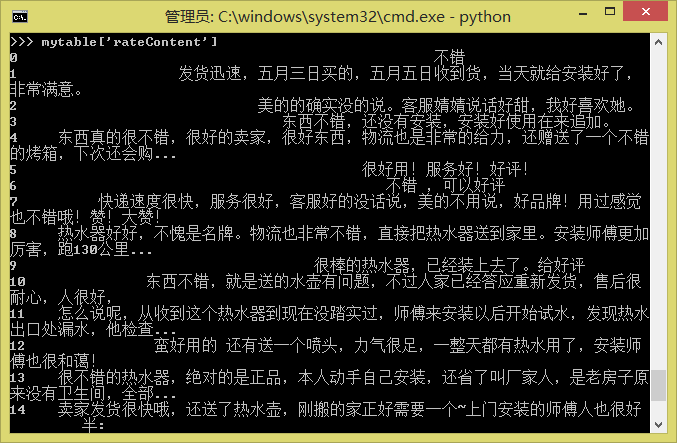
mytable2
如果有两个表mytable1和mytable2需要合并,则只要
pd.concat([mytable1, mytable2], ignore_index=True)等等。更多的操作请参考Pandas的教程。
最后,要把评论保存为txt或者Excel(由于存在中文编码问题,保存为txt可能出错,因此不妨保存为Excel,Pandas也能够读取Excel文件)
mytable.to_csv('mytable.txt')
mytable.to_excel('mytable.xls')
一点点结论 #
让我们看看一共用了几行代码?
import requests as rq
import re
import pandas as pd
url='http://rate.tmall.com/list_detail_rate.htm?itemId=41464129793&sellerId=1652490016¤tPage=1'
myweb = rq.get(url)
myjson = re.findall('\"rateList\":(\[.*?\])\,\"tags\"',myweb.text)[0]
mytable = pd.read_json(myjson)mytable.to_csv('mytable.txt')
mytable.to_excel('mytable.xls')
九行!十行不到,我们就完成了一个简单的爬虫程序,并且能够爬取到天猫上的数据了!是不是跃跃欲试了?
当然,这只是一个简单的示例文件。要想实用,还要加入一些功能,比如找出评论共有多少页,逐页读取评论。另外,批量获取商品id也是要实现的。这些要靠大家自由发挥了,都不是困难的问题,本文只希望起到抛砖引玉的作用,为需要爬取数据的读者提供一个最简单的指引。
其中最困难的问题,应该是大量采集之后,有可能被天猫本身的系统发现,然后要你输入验证码才能继续访问的情况,这就复杂得多了,解决的方案有使用代理、使用更大的采集时间间隔或者直接OCR系统识别验证码等等,笔者也没有很好的解决办法。
转载到请包括本文地址:https://kexue.fm/archives/3298
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 06, 2015). 《记录一次爬取淘宝/天猫评论数据的过程 》[Blog post]. Retrieved from https://kexue.fm/archives/3298
@online{kexuefm-3298,
title={记录一次爬取淘宝/天猫评论数据的过程},
author={苏剑林},
year={2015},
month={May},
url={\url{https://kexue.fm/archives/3298}},
}

May 23rd, 2015
好厉害啊!好久没来了,网站又更新了这么多的内容,佩服佩服,嘻嘻
October 26th, 2015
看了你的文章,试着找到了天猫的评价页面,但是希望能多一点知识出来
请问大概是哪方面的知识呢?
就是一开始找评论的方法,化简加查找,受益良多,对于初学来说。现在尝试找360手机助手PC端的评论,可惜隐藏太深。
360手机助手PC端的评论?是在哪个页面吗?
zhushou.360.cn,我后面发现应该先用手机抓包,抓是抓出来了,但是我需要的汉字内容变成“\u5ba4\u53cb\u67d0\u7c73\u624b\u673a\u4e”这种,这应该是需要转码吧,卡在这里了
http://intf.baike.360.cn/index.php?name=大话西游(手游年轻派)+Android_com.netease.dhxy.qihoo&c=message&a=getmessage&start=0&count=10
以上就是地址了,好像不能精简了~可以调整的参数是start=
“\u5ba4\u53cb\u67d0\u7c73\u624b\u673a”这种是UTF-8编码,已经是正确的格式了,在python中,用print输出就可以看到中文。如
print('\u5ba4\u53cb\u67d0\u7c73\u624b\u673a')
输出“室友某米手机”。
恩,今天上午就清楚这种了,首先你在电脑上抓的是百科的,不能实际对应正确日期,而且内容也是百科上的,实际地址是手机抓包出来的,可以化简为http://comment.mobilem.360.cn/comment/getComments?baike=77208&start=(*)&count=10,参数是START,用ID号表示软件应用,至于\··之类的,的确,是unicode编码的,我上午想或许这个是一种密码,一百度还是找出来了,现在已经解决了,发现之前思路都是正确的,虽然结果如此的简单,但是过程还是比较难搞得,特别是没有人指点的情况下。
谢谢你有帮我看
今天遇到新的问题,http://detail.1688.com/offer/1180547851.html?spm=0.0.0.0.QqQKj4这个网站的用户是匿名的,请问一下如何采集到用户的数据,用之前的方法可以采集到评论,但是买家的信息无法得到,二者之间貌似毫无关联
你要采集买家信息?指的是哪些信息?具体分析某个买家的购买行为?
买家信息一般不公开的,但是通过概率论或许可以做一点工作。
具体来说是买家信息,也就是通过匿名如“韩**”等名称找到买家ID号,然后再进行采集,抓包出来的结果如"countBuyerOrder":1,"mix":false,"buyerName":"韩***","unit":"件","price":["35"],"里面的buyerName就是匿名了,无法得知这个匿名后面的含义,也就是买家信息,的确不公开的,概率论倒是不清楚是否可以采集,我网上找的最有分析性的文章为这个http://bbs.csdn.net/topics/390169622,所以只能粗略了解
你的目的是?如果是为了采集到id,然后做进一步的用途,那我就无能为力了;但是如果你只是想分析某个用户的购买行为,那么基于概率论的思想,还是可以做一点事情的。
恩,只是单纯研究罢了,如果要继续研究下去,那需要的知识就比较复杂了,打算换个新的网址去研究。
yiyiyi你研究的真不错,最近也是需要采集点数据,浏览到你的回复,不知你现在还对采集有研究不,请教点
比较少了,有兴趣还可以探讨
现在淘宝封了不少,要想采集到ID和用户,不知如何下手。迷惑中
March 27th, 2016
为什么我出现了这样的问题:Traceback (most recent call last):
File "C:\Users\lenovo\Desktop\example.py", line 6, in
myjson = re.findall('\"rateList\":(\[.*?\])\,\"tags\"', myweb.text)[0]
IndexError: list index out of range
请问下这问题你解决了么?
我也是这个问题,不知哪里的问题
我也是这个问题,怎么破?
因为tags变成 searchinfo 了
April 22nd, 2016
太感谢你了,我正愁怎么抓取商品评价呢,谢谢你的文章。
May 24th, 2016
我觉得对于开发者来说,能脚本化编写爬虫是一件挺开心的事情( ̄▽ ̄)"。所以我们团队开发了一个专门让开发者用简单的几行 javascript 就能在云上编写和运行复杂爬虫的系统,叫神箭手云爬虫开发平台: http://www.shenjianshou.cn 。欢迎同行们来试用拍砖,尽情给俺们提意见。有想法的可以加群讨论: 342953471
好像是很吸引人的项目。其实python的requests做爬虫已经足够人性化了,但是验证码识别、代理等还需要自己解决。看介绍你们能解决这两个问题?
July 5th, 2016
myjson = re.findall('\"rateList\":(\[.*?\])\,\"tags\"',myweb.text)[0]
IndexError: list index out of range
请问这个提示超出范围该怎么改?谢谢
"searchinfo":"","tags":""},
把tags 改成 searchinfo
July 18th, 2016
博主好厉害,赞赞赞
我也分享个
淘宝商品信息及评价采集爬虫(按商品搜索关键字)
http://www.shenjianshou.cn/index.php?r=market/configDetail&pid=119
June 7th, 2017
想请问一下,得到的这个评论是完整的吗或者说评论的长度是有限制吗?有些貌似...是省略了一些
December 21st, 2017
博主好:"rateList":[],"searchinfo":"","tags"这个是我们正则提取的[]里的内容,可是这[]里什么都没有,而且我提取除来的也仅仅是[],请问这个是什么回事?谢谢!
正则表达式写错了,建议看一下正则表达式。
June 15th, 2018
初学这一块,请问下多个页面怎么写?我试图用pd的concat函数把多个页面合起来,但没有成功。