






14
Dec
端到端的腾讯验证码识别(46%正确率)
By 苏剑林 | 2016-12-14 | 90692位读者 | 引用最新结果请参考:http://kexue.fm/archives/4503/
前段时间有幸得到了一个网友提供的一批带标签的腾讯验证码样本(验证码样板:http://captcha.qq.com/getimage),于是抽了点时间,测试了一下验证码识别的模型。

腾讯验证码
样本
这批验证码比较简单,4位的英文字母,有大小写,但输入的时候不区分大小写,图案有一定的混淆,传统的基于分割的方案估计比较难办。端到端的方案是,直接将验证码输入,做几个卷积层,然后连接几个分类器(26分类),然后就直接输出四个字母标签了。其实还真没有什么好说的,有样本就能做了,而且这个框架是通用的,可以用到区分大小写的情形(52分类),也可以用到英文数字混合的情形(再加10个类别而已)。
26
Jun
OCR技术浅探:9. 代码共享(完)
By 苏剑林 | 2016-06-26 | 89584位读者 | 引用
26
Jun
OCR技术浅探:8. 综合评估
By 苏剑林 | 2016-06-26 | 36487位读者 | 引用数据验证
尽管在测试环境下模型工作良好,但是实践是检验真理的唯一标准. 在本节中,我们通过自己的模型,与京东的测试数据进行比较验证.
衡量OCR系统的好坏有两部分内容:(1)是否成功地圈出了文字;(2)对于圈出来的文字,有没有成功识别. 我们采用评分的方法,对每一张图片的识别效果进行评分. 评分规则如下:
如果圈出的文字区域能够跟京东提供的检测样本的box文件中匹配,那么加1分,如果正确识别出文字来,另外加1分,最后每张图片的分数是前面总分除以文字总数.
按照这个规则,每张图片的评分最多是2分,最少是0分. 如果评分超过1,说明识别效果比较好了. 经过京东的测试数据比较,我们的模型平均评分大约是0.84,效果差强人意。
26
Jun
OCR技术浅探:7. 语言模型
By 苏剑林 | 2016-06-26 | 63449位读者 | 引用由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一.
转移概率
在我们分析实验结果的过程中,有出现这一案例.由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择.但是语言模型却可以很巧妙地解决这个问题.原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”.
从概率的角度来看,就是对于第一个字的区域的识别结果$s_1$,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率$W(s_1)$分别为0.99996、0.00004;第二个字的区域的识别结果$s_2$,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率$W(s_2)$分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”.
25
Jun
OCR技术浅探:6. 光学识别
By 苏剑林 | 2016-06-25 | 89788位读者 | 引用经过第一、二步,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别.
模型选择
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型.
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型. 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果. 事实上,我们选择卷积神经网络的主要原因有:
1. 对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2. 比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3. 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的.
24
Jun
OCR技术浅探:5. 文本切割
By 苏剑林 | 2016-06-24 | 57242位读者 | 引用

24
Jun
OCR技术浅探:4. 文字定位
By 苏剑林 | 2016-06-24 | 50879位读者 | 引用经过第一部分,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步:1、邻近搜索,目的是圈出单行文字;2、文本切割,目的是将单行文本切割为单字.
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字. 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元”这些字,由于不具有连通性,所以就被分拆开了,如图13. 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域.

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来. 如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了. 因此,我们只允许区域向单一的一个方向膨胀. 我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向.
既然涉及到了邻近,那么就需要有距离的概念. 下面给出一个比较合理的距离的定义.
距离
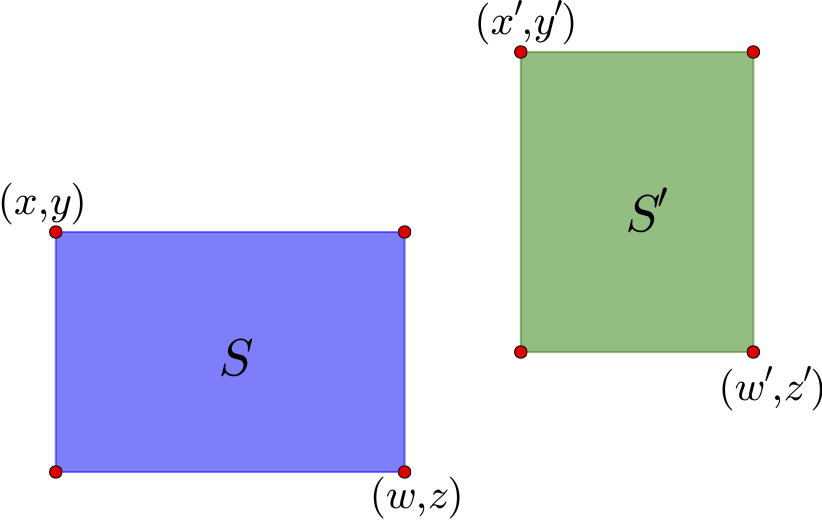
图14 两个示例区域
如上图,通过左上角坐标$(x,y)$和右下角坐标$(z,w)$就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的. 这个区域的中心是$\left(\frac{x+w}{2},\frac{y+z}{2}\right)$. 对于图中的两个区域$S$和$S'$,可以计算它们的中心向量差
$$(x_c,y_c)=\left(\frac{x'+w'}{2}-\frac{x+w}{2},\frac{y'+z'}{2}-\frac{y+z}{2}\right)\tag{10}$$
如果直接使用$\sqrt{x_c^2+y_c^2}$作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点. 因此,需要减去区域的长度:
$$(x'_c,y'_c)=\left(x_c-\frac{w-x}{2}-\frac{w'-x'}{2},y_c-\frac{z-y}{2}-\frac{z'-y'}{2}\right)\tag{11}$$
距离定义为
$$d(S,S')=\sqrt{[\max(x'_c,0)]^2+[\max(y'_c,0)]^2}\tag{12}$$
至于方向,由$(x_c,y_c)$的幅角进行判断即可.
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作.
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域. 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合.
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15.

图15 通过邻近搜索后,圈出的文字区域
18
Jun

最近评论