






2
Apr
通过梯度近似寻找Normalization的替代品
By 苏剑林 | 2025-04-02 | 5164位读者 | 引用不知道大家有没有留意到前段时间的《Transformers without Normalization》?这篇论文试图将Transformer模型中的Normalization层用一个Element-wise的运算DyT替代,以期能提高速度并保持效果。这种基础架构的主题本身自带一点吸引力,加之Kaiming He和Yann LeCun两位大佬挂名,所以这篇论文发布之时就引起了不少围观,评价也是有褒有贬。
无独有偶,上周的一篇新论文《The Mathematical Relationship Between Layer Normalization and Dynamic Activation Functions》从梯度分析和微分方程的视角解读了DyT,并提出了新的替代品。个人感觉这个理解角度非常本质,遂学习和分享一波。
写在前面
DyT全称是Dynamic Tanh,它通过如下运算来替代Normalization层:
\begin{equation}\mathop{\text{DyT}}(\boldsymbol{x}) = \boldsymbol{\gamma} \odot \tanh(\alpha \boldsymbol{x}) + \boldsymbol{\beta}\end{equation}
8
Aug
生成扩散模型漫谈(六):一般框架之ODE篇
By 苏剑林 | 2022-08-08 | 144109位读者 | 引用上一篇文章《生成扩散模型漫谈(五):一般框架之SDE篇》中,我们对宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》做了基本的介绍和推导。然而,顾名思义,上一篇文章主要涉及的是原论文中SDE相关的部分,而遗留了被称为“概率流ODE(Probability flow ODE)”的部分内容,所以本文对此做个补充分享。
事实上,遗留的这部分内容在原论文的正文中只占了一小节的篇幅,但我们需要新开一篇文章来介绍它,因为笔者想了很久后发现,该结果的推导还是没办法绕开Fokker-Planck方程,所以我们需要一定的篇幅来介绍Fokker-Planck方程,然后才能请主角ODE登场。
再次反思
我们来大致总结一下上一篇文章的内容:首先,我们通过SDE来定义了一个前向过程(“拆楼”):
\begin{equation}d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\label{eq:sde-forward}\end{equation}
1
Mar
科学空间|Scientific Spaces 介绍
By 苏剑林 | 2009-03-01 | 437315位读者 | 引用中山大学基础数学研究生,本科为华南师范大学。93年从奥尔特星云移民地球,因忘记回家路线,遂仰望星空,希望找到时空之路。同时兼爱各种科学,热衷钻牛角尖,因此经常碰壁,但偶然把牛角钻穿,也乐在其中。偏爱物理、天文、计算机,喜欢思考,虽擅长理性分析,但也容易感情用事,崇拜Feynman。爱好阅读,没事偷懒玩玩象棋,闲时爱好进入厨房做几道小菜,偶尔也开开数据“挖掘机”。明明要学基础数学,偏偏不务正业,沉溺神经网络,妄想人工智能,曾未在ACL、AAAI、COLING等会议上发表一篇文章。近期还挣扎在NLP大坑,在科学空间(https://kexue.fm)期待大家的拯救。
历史内容
华南师范大学数学系学生。93年从奥尔特星云移民地球,因忘记回家路线,遂仰望星空,希望找到时空之路。同时兼爱各种科学,热衷钻牛角尖,因此经常碰壁,但偶然把牛角钻穿,也乐在其中。偏爱物理、天文,喜欢思考,虽擅长理性分析,但也容易感情用事,崇拜费曼。长期阅读《天文爱好者》和《环球科学》,没事偷懒玩玩象棋,闲时爱好进入厨房做几道小菜,偶尔也当当电工。近期主要学习理论物理,在科学空间期待大家的指教。
名称:科学空间|Scientific Spaces
网址:http://kexue.fm
站长:苏剑林
信念:探索我们的世界,聆听我们的自然
网站历史
2009.03.01 网站初步建立,刚开始的时候使用的是BoBlog以及宇宙驿站的空间,内容定位:科学转载。 2009.03.28 开始进行大规模推广,访问量开始提高 2009.03-05 期间进行过多次改变,特别是Blog程序的转换,内容上的改革等
7
Nov
人不能忘本|我的数学竞赛题
By 苏剑林 | 2009-11-07 | 43145位读者 | 引用
1
May
我们打算飞到小行星上——但是,哪一颗好呢?
By 苏剑林 | 2010-05-01 | 37024位读者 | 引用
漫游在太空的小行星
站长:已经很久没有翻译过科普文章了。现在再来尝试一下,依旧是“Google+金山+搜索+理解”的模式,依旧是那么烂的水平,依旧是那么差的文采,呵呵。有任何意见欢迎提出。 4月15日,美国总统巴拉克·奥巴马视察了位于佛罗里达州的肯尼迪航天中心并发表演讲,提出美国航天新计划:美国未来航天的目的地是火星和小行星,终止布什政府提出的国家载人航天飞行项目。他强有力地回击了其政策的批评者,同时呼吁私营企业铺设飞往火星的创新之路,而不是以国家之力展示美国的优势。 众所周知,载人登小行星比载人登月难多了。除了苛刻的技术条件外,适合登录的小行星也不多,奥巴马的新方案真的可行吗?让我们拭目以待!
15
Aug
《方程与宇宙》:拉格朗日点的点点滴滴(四)
By 苏剑林 | 2010-08-15 | 101922位读者 | 引用The New Calculation Of Lagrangian Point 1,2,3
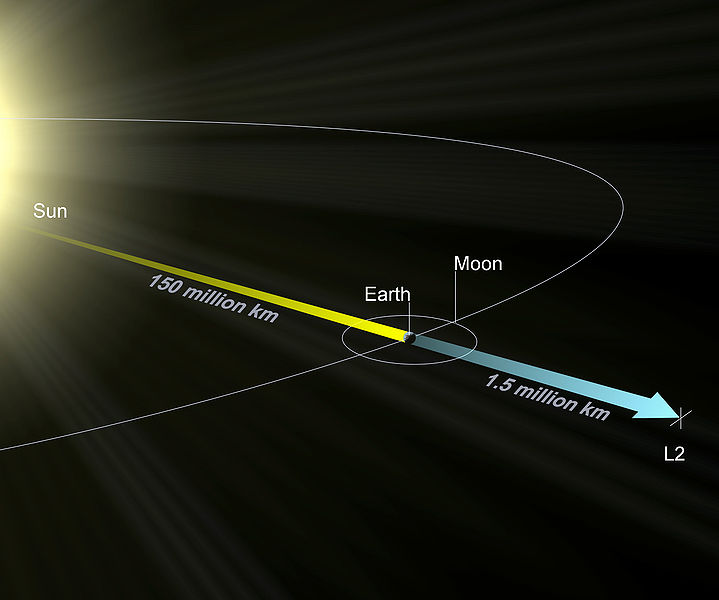
L2_rendering
关于n体问题,选择质心或其他定点为参考点,我们可以列出下面的运动方程:
$$\ddot{\vec{r}}_k=\sum_{i=1,i != k}^{n} Gm_i\frac{\vec{r}_i-\vec{r}_k}{|\vec{r}_i-\vec{r}_k|^3}\tag{19}$$
现在我们只考虑三体问题。天文学家一直希望能够找到三体问题的简洁解,可是很遗憾,庞加莱已经证明了三体问题的解是混沌的,也就是说任何微小的扰动都有可能造成不可预料的后果(可以形象的比喻为:巴西的一只蝴蝶翅膀的扇动,有可能因此美国的一场龙卷风)。



最近评论