






29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 85375位读者 | 引用
18
May
鱼与熊掌兼得:融合检索和生成的SimBERT模型
By 苏剑林 | 2020-05-18 | 315000位读者 | 引用前段时间我们开放了一个名为SimBERT的模型权重,它是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明。在这篇文章里,我们来补充这部分内容。
UniLM
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。我们之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

UniLM的Mask
7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 112390位读者 | 引用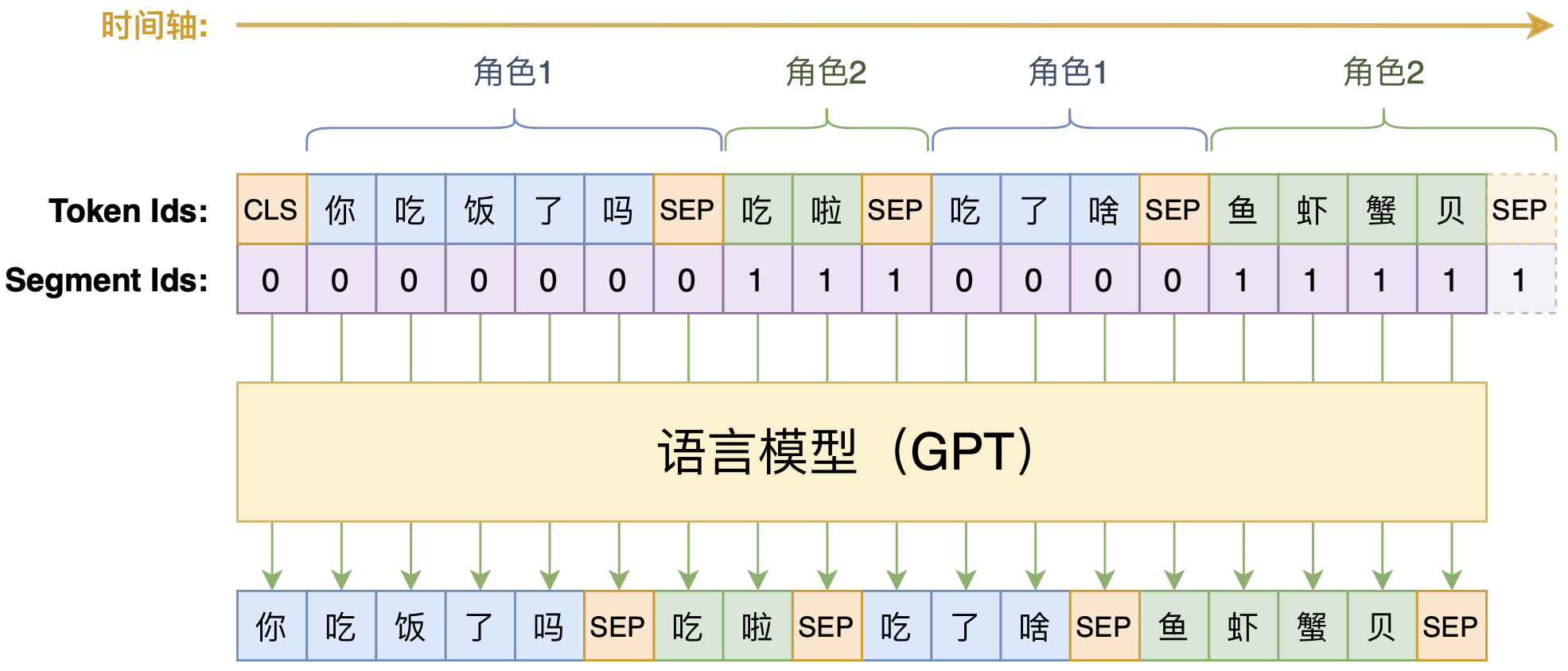
25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 124630位读者 | 引用机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
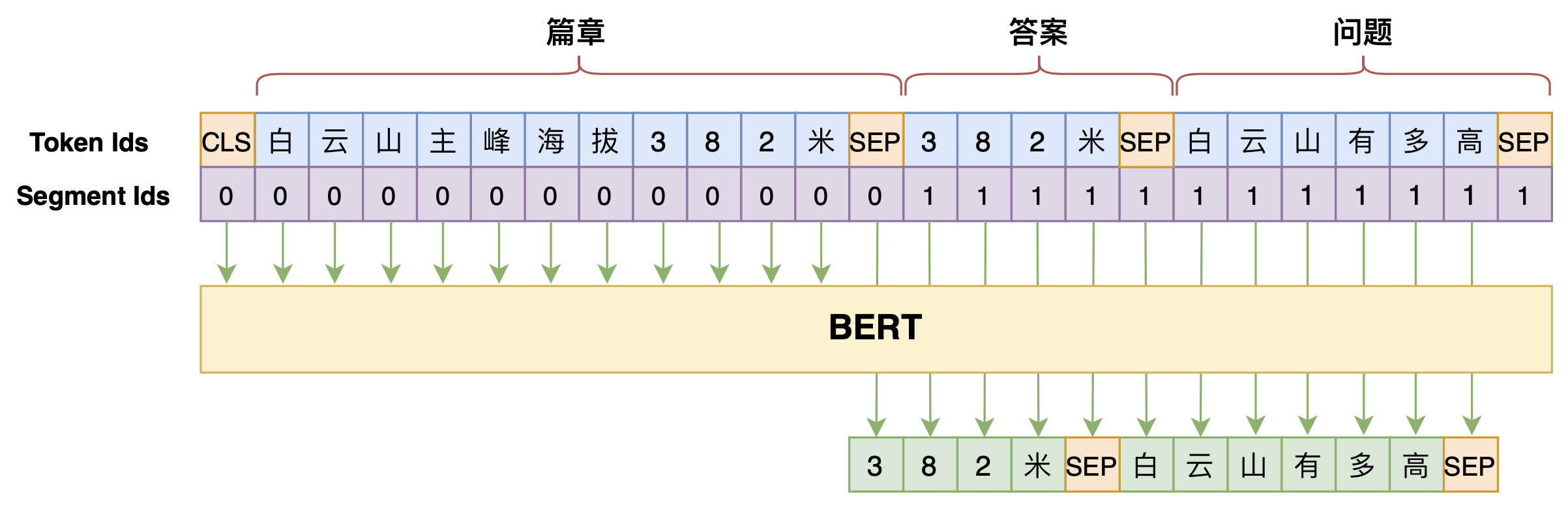
本文的问答生成模型示意图
10
Oct
从动力学角度看优化算法(五):为什么学习率不宜过小?
By 苏剑林 | 2020-10-10 | 58805位读者 | 引用本文的主题是“为什么我们需要有限的学习率”,所谓“有限”,指的是不大也不小,适中即可,太大容易导致算法发散,这不难理解,但为什么太小也不好呢?一个容易理解的答案是,学习率过小需要迭代的步数过多,这是一种没有必要的浪费,因此从“节能”和“加速”的角度来看,我们不用过小的学习率。但如果不考虑算力和时间,那么过小的学习率是否可取呢?Google最近发布在Arxiv上的论文《Implicit Gradient Regularization》试图回答了这个问题,它指出有限的学习率隐式地给优化过程带来了梯度惩罚项,而这个梯度惩罚项对于提高泛化性能是有帮助的,因此哪怕不考虑算力和时间等因素,也不应该用过小的学习率。
对于梯度惩罚,本博客已有过多次讨论,在文章《对抗训练浅谈:意义、方法和思考(附Keras实现)》和《泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练》中,我们就分析了对抗训练一定程度上等价于对输入的梯度惩罚,而文章《我们真的需要把训练集的损失降低到零吗?》介绍的Flooding技巧则相当于对参数的梯度惩罚。总的来说,不管是对输入还是对参数的梯度惩罚,都对提高泛化能力有一定帮助。
5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 115557位读者 | 引用最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
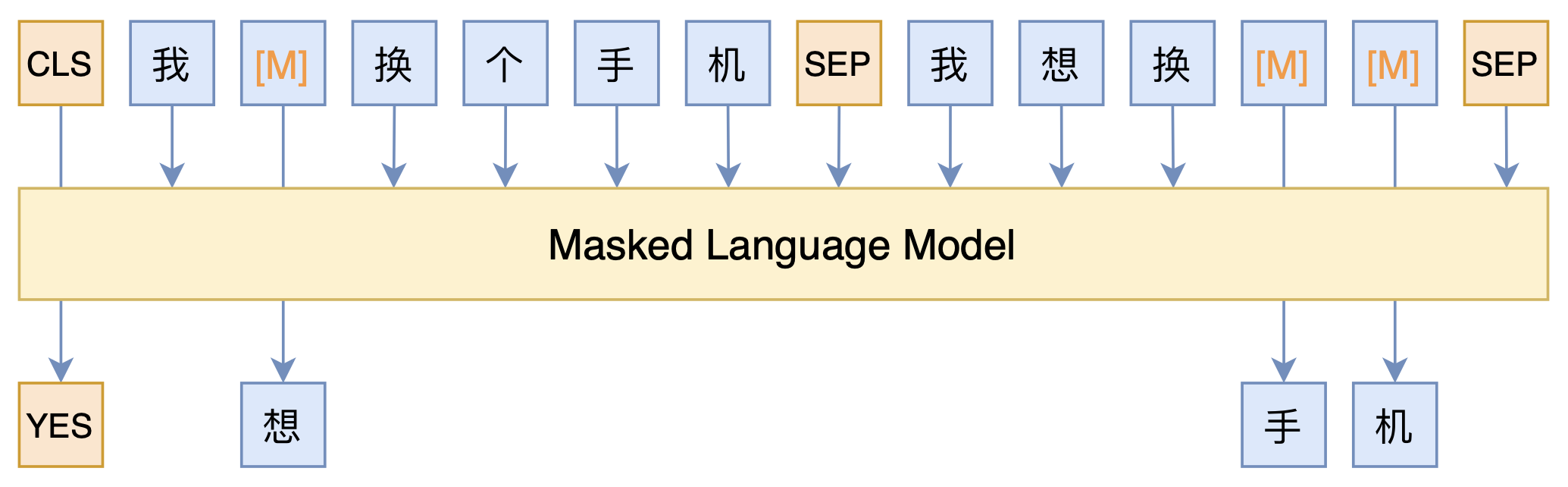
本文模型示意图
24
Aug
隐藏在动量中的梯度累积:少更新几步,效果反而更好?
By 苏剑林 | 2021-08-24 | 34714位读者 | 引用我们知道,梯度累积是在有限显存下实现大batch_size训练的常用技巧。在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们就简单介绍过梯度累积的实现,大致的思路是新增一组参数来缓存梯度,最后用缓存的梯度来更新模型。美中不足的是,新增一组参数会带来额外的显存占用。
这几天笔者在思考优化器的时候,突然意识到:梯度累积其实可以内置在带动量的优化器中!带着这个思路,笔者对优化了进行了一些推导和实验,最后还得到一个有意思但又有点反直觉的结论:少更新几步参数,模型最终效果可能会变好!
注:本文下面的结果,几乎原封不动且没有引用地出现在Google的论文《Combined Scaling for Zero-shot Transfer Learning》中,在此不做过多评价,请读者自行品评。
SGDM
在正式讨论之前,我们定义函数
\begin{equation}\chi_{t/k} = \left\{ \begin{aligned}&1,\quad t \equiv 0\,(\text{mod}\, k) \\
&0,\quad t \not\equiv 0\,(\text{mod}\, k)
\end{aligned}\right.\end{equation}
也就是说,$t$是一个整数,当它是$k$的倍数时,$\chi_{t/k}=1$,否则$\chi_{t/k}=0$,这其实就是一个$t$能否被$k$整除的示性函数。在后面的讨论中,我们将反复用到这个函数。
22
Apr
GAU-α:尝鲜体验快好省的下一代Attention
By 苏剑林 | 2022-04-22 | 51916位读者 | 引用在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了GAU(Gated Attention Unit,门控线性单元),在这里笔者愿意称之为“目前最有潜力的下一代Attention设计”,因为它真正达到了“更快(速度)、更好(效果)、更省(显存)”的特点。
然而,有些读者在自己的测试中得到了相反的结果,比如收敛更慢、效果更差等,这与笔者的测试结果大相径庭。本文就来分享一下笔者自己的训练经验,并且放出一个尝鲜版“GAU-α”供大家测试。
GAU-α
首先介绍一下开源出来的“GAU-α”在CLUE任务上的成绩单:
$$\small{\begin{array}{c|ccccccccccc}
\hline
& \text{iflytek} & \text{tnews} & \text{afqmc} & \text{cmnli} & \text{ocnli} & \text{wsc} & \text{csl} & \text{cmrc2018} & \text{c3} & \text{chid} & \text{cluener}\\
\hline
\text{BERT} & 60.06 & 56.80 & 72.41 & 79.56 & 73.93 & 78.62 & 83.93 & 56.17 & 60.54 & 85.69 & 79.45 \\
\text{RoBERTa} & 60.64 & \textbf{58.06} & 74.05 & 81.24 & 76.00 & \textbf{87.50} & 84.50 & 56.54 & 67.66 & 86.71 & 79.47\\
\text{RoFormer} & 60.91 & 57.54 & 73.52 & 80.92 & \textbf{76.07} & 86.84 & 84.63 & 56.26 & 67.24 & 86.57 & 79.72\\
\text{RoFormerV2}^* & 60.87 & 56.54 & 72.75 & 80.34 & 75.36 & 80.92 & 84.67 & 57.91 & 64.62 & 85.09 & \textbf{81.08}\\
\hline
\text{GAU-}\alpha & \textbf{61.41} & 57.76 & \textbf{74.17} & \textbf{81.82} & 75.86 & 79.93 & \textbf{85.67} & \textbf{58.09} & \textbf{68.24} & \textbf{87.91} & 80.01\\
\hline
\end{array}}$$

最近评论